Generalized Multi-Objective Reinforcement Learning with Envelope Updates in URLLC-enabled Vehicular Networks
2405.11331
0
0
Abstract
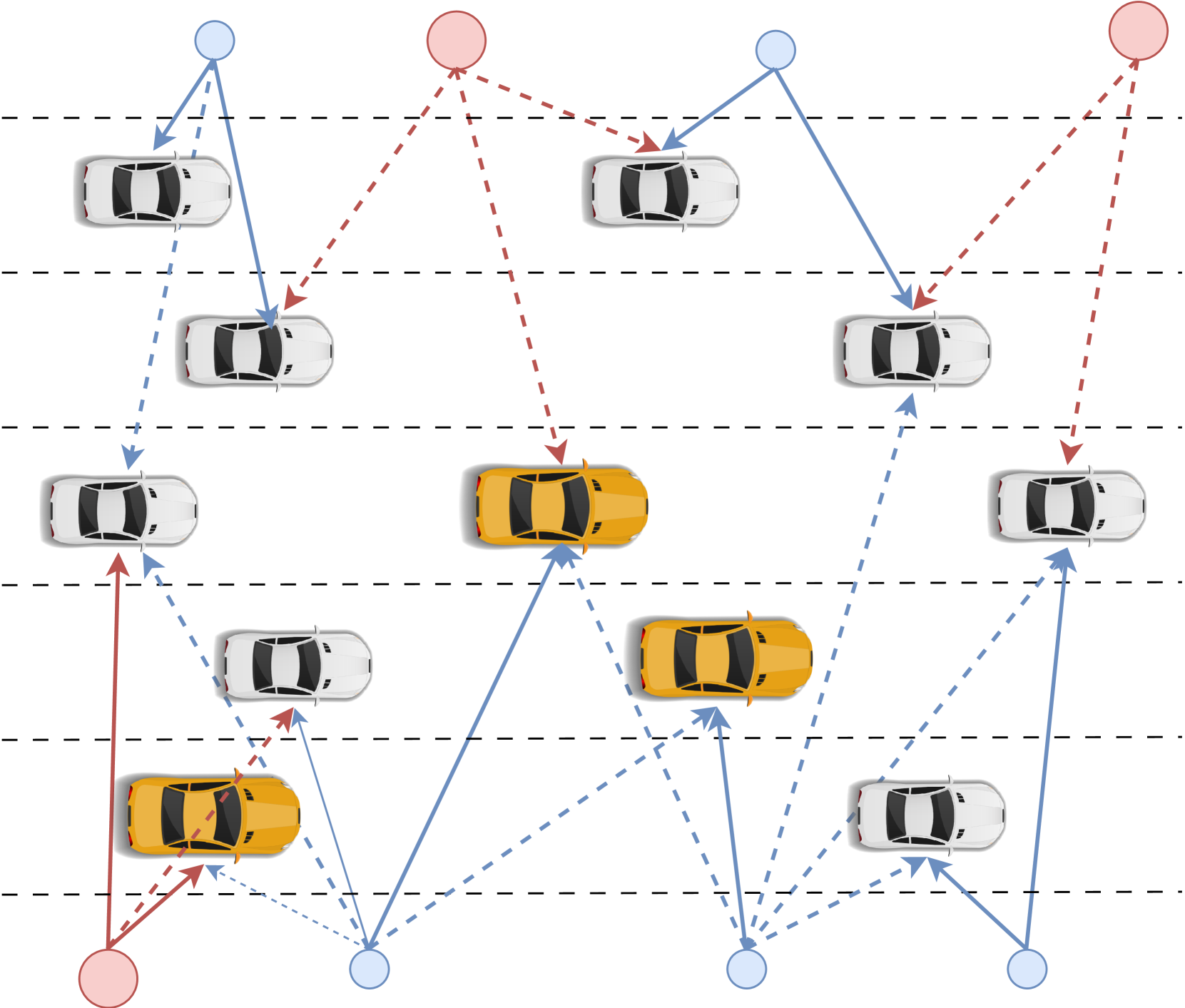
We develop a novel multi-objective reinforcement learning (MORL) framework to jointly optimize wireless network selection and autonomous driving policies in a multi-band vehicular network operating on conventional sub-6GHz spectrum and Terahertz frequencies. The proposed framework is designed to 1. maximize the traffic flow and 2. minimize collisions by controlling the vehicle's motion dynamics (i.e., speed and acceleration), and enhance the ultra-reliable low-latency communication (URLLC) while minimizing handoffs (HOs). We cast this problem as a multi-objective Markov Decision Process (MOMDP) and develop solutions for both predefined and unknown preferences of the conflicting objectives. Specifically, deep-Q-network and double deep-Q-network-based solutions are developed first that consider scalarizing the transportation and telecommunication rewards using predefined preferences. We then develop a novel envelope MORL solution which develop policies that address multiple objectives with unknown preferences to the agent. While this approach reduces reliance on scalar rewards, policy effectiveness varying with different preferences is a challenge. To address this, we apply a generalized version of the Bellman equation and optimize the convex envelope of multi-objective Q values to learn a unified parametric representation capable of generating optimal policies across all possible preference configurations. Following an initial learning phase, our agent can execute optimal policies under any specified preference or infer preferences from minimal data samples.Numerical results validate the efficacy of the envelope-based MORL solution and demonstrate interesting insights related to the inter-dependency of vehicle motion dynamics, HOs, and the communication data rate. The proposed policies enable autonomous vehicles to adopt safe driving behaviors with improved connectivity.
Create account to get full access
Overview
- This paper proposes a generalized multi-objective reinforcement learning (MORL) framework for ultra-reliable and low-latency communication (URLLC)-enabled vehicular networks.
- The framework uses envelope updates to efficiently explore the Pareto front and find optimal policies that balance multiple objectives.
- The authors demonstrate the approach on a simulation of a URLLC-enabled vehicular network with conflicting objectives such as minimizing delay, maximizing reliability, and maximizing throughput.
Plain English Explanation
In this research, the authors have developed a new way to train artificial intelligence (AI) systems to make decisions in complex environments with multiple, sometimes conflicting, goals. The specific application they focus on is vehicular networks - networks of connected vehicles that need to communicate reliably and quickly.
The key challenge is that these vehicles may have competing objectives, such as minimizing delay, maximizing reliability, and maximizing throughput. Traditional reinforcement learning approaches struggle to find the right balance between these goals. The authors' solution is to use a generalized multi-objective reinforcement learning (MORL) framework that can efficiently explore the different possible tradeoffs and find the best overall policy.
The core idea is to use "envelope updates" - a way of updating the AI system's knowledge that allows it to quickly learn the range of possible outcomes and decide on the best compromise. This is especially important in URLLC-enabled vehicular networks, where the requirements for reliable and low-latency communication are critical.
By testing their approach in simulations, the authors demonstrate that their MORL framework with envelope updates can outperform traditional single-objective reinforcement learning methods in finding optimal policies that balance the competing goals in this type of complex, real-world environment.
Technical Explanation
The authors propose a generalized multi-objective reinforcement learning (MORL) framework for URLLC-enabled vehicular networks. The key innovation is the use of "envelope updates" to efficiently explore the Pareto front and find optimal policies that balance multiple objectives, such as minimizing delay, maximizing reliability, and maximizing throughput.
The authors formulate the problem as a multi-objective Markov decision process (MOMDPs). They then propose a new MORL algorithm that maintains a set of value function envelopes, which represent the range of possible values for each objective. During training, the agent uses these envelopes to guide its exploration and find policies that improve the overall set of Pareto-optimal solutions.
The authors evaluate their approach on a simulation of a URLLC-enabled vehicular network. They compare the performance of their MORL framework with envelope updates to traditional single-objective reinforcement learning methods. The results show that their approach can find policies that better balance the conflicting objectives, outperforming the baselines in terms of delay, reliability, and throughput.
Critical Analysis
The authors have made a strong contribution to the field of multi-objective reinforcement learning. Their use of envelope updates is a novel and effective way to explore the Pareto front and find optimal policies in complex, real-world environments.
One potential limitation of the work is the reliance on simulations. While the authors demonstrate the effectiveness of their approach in the simulated URLLC-enabled vehicular network, it would be valuable to see how it performs in real-world deployments. Additional research could investigate the robustness of the approach to factors not captured in the simulation, such as environmental noise, sensor errors, and unpredictable human behavior.
Furthermore, the authors focus on a specific set of objectives (delay, reliability, and throughput) in the vehicular network context. It would be interesting to see how the MORL framework with envelope updates could be applied to other multi-objective problems, where the objectives and constraints may differ.
Overall, this paper presents a promising approach to multi-objective reinforcement learning that could have significant implications for a wide range of real-world applications, from autonomous vehicles to smart city infrastructure.
Conclusion
This research proposes a generalized multi-objective reinforcement learning (MORL) framework with envelope updates for URLLC-enabled vehicular networks. The key innovation is the use of envelope updates to efficiently explore the Pareto front and find optimal policies that balance multiple, often conflicting objectives such as minimizing delay, maximizing reliability, and maximizing throughput.
The authors demonstrate the effectiveness of their approach through simulations, showing that it can outperform traditional single-objective reinforcement learning methods in this complex, real-world environment. While the work is limited to simulations, it represents a significant advancement in the field of multi-objective reinforcement learning and has the potential to impact a wide range of applications where multiple, competing goals must be balanced.
Future research could explore the robustness of the approach in real-world deployments and investigate its applicability to other multi-objective problems beyond the vehicular network context. Overall, this paper provides a valuable contribution to the ongoing efforts to develop AI systems capable of making nuanced, multi-faceted decisions in complex, dynamic environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Optimizing Vehicular Networks with Variational Quantum Circuits-based Reinforcement Learning
Zijiang Yan, Ramsundar Tanikella, Hina Tabassum
0
0
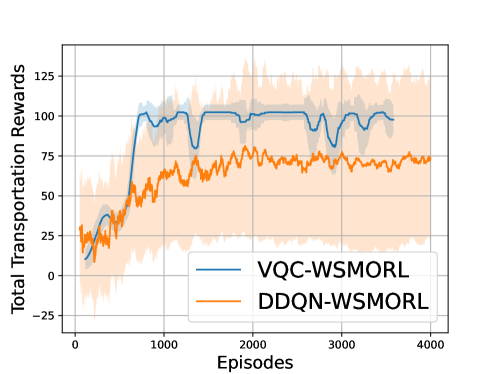
In vehicular networks (VNets), ensuring both road safety and dependable network connectivity is of utmost importance. Achieving this necessitates the creation of resilient and efficient decision-making policies that prioritize multiple objectives. In this paper, we develop a Variational Quantum Circuit (VQC)-based multi-objective reinforcement learning (MORL) framework to characterize efficient network selection and autonomous driving policies in a vehicular network (VNet). Numerical results showcase notable enhancements in both convergence rates and rewards when compared to conventional deep-Q networks (DQNs), validating the efficacy of the VQC-MORL solution.
5/30/2024

Demonstration Guided Multi-Objective Reinforcement Learning
Junlin Lu, Patrick Mannion, Karl Mason
0
0
Multi-objective reinforcement learning (MORL) is increasingly relevant due to its resemblance to real-world scenarios requiring trade-offs between multiple objectives. Catering to diverse user preferences, traditional reinforcement learning faces amplified challenges in MORL. To address the difficulty of training policies from scratch in MORL, we introduce demonstration-guided multi-objective reinforcement learning (DG-MORL). This novel approach utilizes prior demonstrations, aligns them with user preferences via corner weight support, and incorporates a self-evolving mechanism to refine suboptimal demonstrations. Our empirical studies demonstrate DG-MORL's superiority over existing MORL algorithms, establishing its robustness and efficacy, particularly under challenging conditions. We also provide an upper bound of the algorithm's sample complexity.
4/8/2024
Learning Adaptive Multi-Objective Robot Navigation with Demonstrations
Jorge de Heuvel, Tharun Sethuraman, Maren Bennewitz
0
0
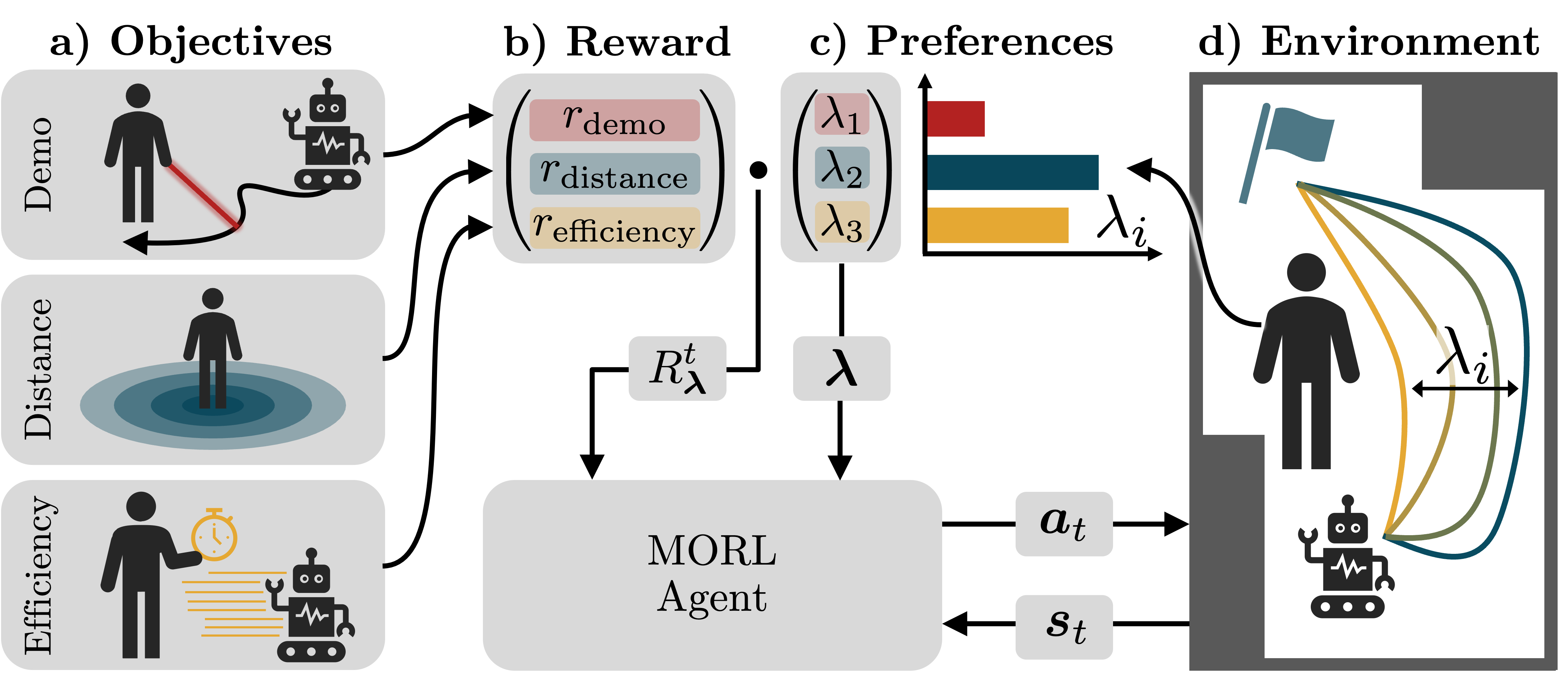
Preference-aligned robot navigation in human environments is typically achieved through learning-based approaches, utilizing demonstrations and user feedback for personalization. However, personal preferences are subject to change and might even be context-dependent. Yet traditional reinforcement learning (RL) approaches with a static reward function often fall short in adapting to these varying user preferences. This paper introduces a framework that combines multi-objective reinforcement learning (MORL) with demonstration-based learning. Our approach allows for dynamic adaptation to changing user preferences without retraining. Through rigorous evaluations, including sim-to-real and robot-to-robot transfers, we demonstrate our framework's capability to reflect user preferences accurately while achieving high navigational performance in terms of collision avoidance and goal pursuance.
4/15/2024

Large Language Model-Driven Curriculum Design for Mobile Networks
Omar Erak, Omar Alhussein, Shimaa Naser, Nouf Alabbasi, De Mi, Sami Muhaidat
0
0
This study introduces an innovative framework that employs large language models (LLMs) to automate the design and generation of curricula for reinforcement learning (RL). As mobile networks evolve towards the 6G era, managing their increasing complexity and dynamic nature poses significant challenges. Conventional RL approaches often suffer from slow convergence and poor generalization due to conflicting objectives and the large state and action spaces associated with mobile networks. To address these shortcomings, we introduce curriculum learning, a method that systematically exposes the RL agent to progressively challenging tasks, improving convergence and generalization. However, curriculum design typically requires extensive domain knowledge and manual human effort. Our framework mitigates this by utilizing the generative capabilities of LLMs to automate the curriculum design process, significantly reducing human effort while improving the RL agent's convergence and performance. We deploy our approach within a simulated mobile network environment and demonstrate improved RL convergence rates, generalization to unseen scenarios, and overall performance enhancements. As a case study, we consider autonomous coordination and user association in mobile networks. Our obtained results highlight the potential of combining LLM-based curriculum generation with RL for managing next-generation wireless networks, marking a significant step towards fully autonomous network operations.
6/24/2024