Ever-Evolving Memory by Blending and Refining the Past

0
Sign in to get full access
Overview
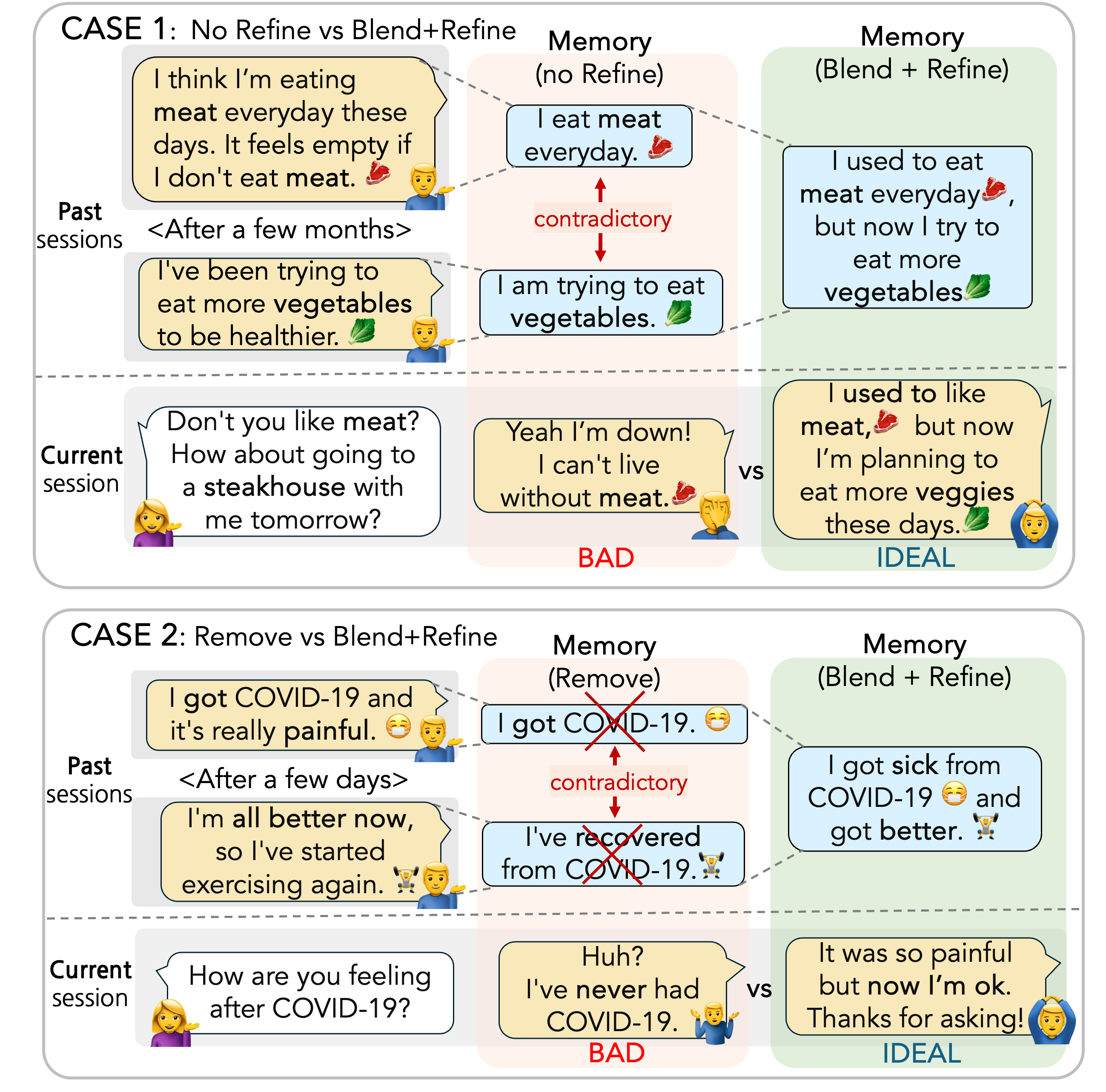
- The paper discusses the limitations of current approaches to memory in large language models (LLMs), where only the current session is considered when creating new memory.
- This can lead to memory containing outdated or contradictory information, as past experiences are not properly incorporated.
- The paper proposes a novel approach to memory management that blends and refines past experiences to create an ever-evolving memory, addressing the shortcomings of existing methods.
Plain English Explanation
The paper explores an important issue with how current artificial intelligence (AI) systems, particularly large language models, store and use information. Typically, these models only consider the immediate context or "session" when adding new information to their memory. This means that past experiences and knowledge are not properly integrated, leading to a memory that can be outdated or even contradictory.
Imagine you're trying to learn a new skill, like cooking. Each time you try a new recipe, the AI assistant only remembers that specific instance, without considering how your skills have improved over time. As a result, the assistant may give you the same basic advice every time, even though you've become more experienced.
The researchers propose a solution to this problem, which involves blending and refining past experiences to create an "ever-evolving" memory. This is similar to how human memory works - we don't just store isolated facts, but constantly update and refine our understanding based on new information and experiences.
By incorporating this approach into AI systems, the researchers hope to create more robust and adaptive memory that can better support tasks like personalized response generation and memory-augmented learning. This could lead to AI assistants that are more helpful, personalized, and aligned with the user's evolving needs and knowledge.
Technical Explanation
The paper introduces a novel approach to memory management in large language models, which aims to address the limitations of existing methods that only consider the current session when creating new memory.
The researchers propose a memory-augmented architecture that blends and refines past experiences to create an ever-evolving memory. This is achieved through two key components:
-
Memory Blending: The model continuously integrates new experiences with past memories, updating the memory representation to reflect the user's evolving knowledge and understanding.
-
Memory Refinement: The model selectively refines and prunes outdated or contradictory information in the memory, ensuring that the stored knowledge remains coherent and up-to-date.
By incorporating these mechanisms, the researchers demonstrate that the model can maintain a more accurate and comprehensive memory representation, which can lead to improved performance on tasks that require personalized assistant capabilities or long-term knowledge retention.
Critical Analysis
The paper presents a compelling approach to addressing the limitations of current memory management techniques in large language models. However, it is important to note that the proposed solution is still a conceptual framework, and further research and empirical evaluation are needed to fully assess its effectiveness and generalizability.
One potential concern is the complexity of implementing the memory blending and refinement mechanisms, as they may require additional computational resources and training data to ensure the memory representation remains coherent and accurate over time. Additionally, the paper does not explore the potential trade-offs or potential edge cases that may arise when applying this approach in real-world scenarios.
Furthermore, the paper does not provide a detailed comparison to alternative memory management techniques, such as episodic memory or meta-learning approaches. A more comprehensive evaluation of the strengths and weaknesses of the proposed method relative to other state-of-the-art techniques would strengthen the paper's contribution.
Conclusion
The paper presents a novel approach to memory management in large language models, which aims to address the limitations of existing methods that only consider the current session when creating new memory. By blending and refining past experiences, the proposed architecture can maintain an ever-evolving and coherent memory representation, potentially leading to more personalized and adaptive AI assistants.
While further research and empirical evaluation are needed, this work represents an important step forward in the quest to develop AI systems that can better understand and adapt to the user's evolving needs and knowledge. As the field of AI continues to advance, the ability to effectively manage and leverage memory will be crucial for creating more intelligent and useful applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Ever-Evolving Memory by Blending and Refining the Past
Seo Hyun Kim, Keummin Ka, Yohan Jo, Seung-won Hwang, Dongha Lee, Jinyoung Yeo
For a human-like chatbot, constructing a long-term memory is crucial. However, current large language models often lack this capability, leading to instances of missing important user information or redundantly asking for the same information, thereby diminishing conversation quality. To effectively construct memory, it is crucial to seamlessly connect past and present information, while also possessing the ability to forget obstructive information. To address these challenges, we propose CREEM, a novel memory system for long-term conversation. Improving upon existing approaches that construct memory based solely on current sessions, CREEM blends past memories during memory formation. Additionally, we introduce a refining process to handle redundant or outdated information. Unlike traditional paradigms, we view responding and memory construction as inseparable tasks. The blending process, which creates new memories, also serves as a reasoning step for response generation by informing the connection between past and present. Through evaluation, we demonstrate that CREEM enhances both memory and response qualities in multi-session personalized dialogues.
Read more4/9/2024

0
Self-evolving Agents with reflective and memory-augmented abilities
Xuechen Liang, Meiling Tao, Yinghui Xia, Tianyu Shi, Jun Wang, JingSong Yang
Large language models (LLMs) have made significant advances in the field of natural language processing, but they still face challenges such as continuous decision-making. In this research, we propose a novel framework by integrating iterative feedback, reflective mechanisms, and a memory optimization mechanism based on the Ebbinghaus forgetting curve, it significantly enhances the agents' capabilities in handling multi-tasking and long-span information.
Read more9/4/2024
0
Toward Conversational Agents with Context and Time Sensitive Long-term Memory
Nick Alonso, Tom'as Figliolia, Anthony Ndirango, Beren Millidge
There has recently been growing interest in conversational agents with long-term memory which has led to the rapid development of language models that use retrieval-augmented generation (RAG). Until recently, most work on RAG has focused on information retrieval from large databases of texts, like Wikipedia, rather than information from long-form conversations. In this paper, we argue that effective retrieval from long-form conversational data faces two unique problems compared to static database retrieval: 1) time/event-based queries, which requires the model to retrieve information about previous conversations based on time or the order of a conversational event (e.g., the third conversation on Tuesday), and 2) ambiguous queries that require surrounding conversational context to understand. To better develop RAG-based agents that can deal with these challenges, we generate a new dataset of ambiguous and time-based questions that build upon a recent dataset of long-form, simulated conversations, and demonstrate that standard RAG based approaches handle such questions poorly. We then develop a novel retrieval model which combines chained-of-table search methods, standard vector-database retrieval, and a prompting method to disambiguate queries, and demonstrate that this approach substantially improves over current methods at solving these tasks. We believe that this new dataset and more advanced RAG agent can act as a key benchmark and stepping stone towards effective memory augmented conversational agents that can be used in a wide variety of AI applications.
Read more6/6/2024

0
MemBench: Towards Real-world Evaluation of Memory-Augmented Dialogue Systems
Junqing He, Liang Zhu, Qi Wei, Rui Wang, Jiaxing Zhang
Long-term memory is so important for chatbots and dialogue systems (DS) that researchers have developed numerous memory-augmented DS. However, their evaluation methods are different from the real situation in human conversation. They only measured the accuracy of factual information or the perplexity of generated responses given a query, which hardly reflected their performance. Moreover, they only consider passive memory retrieval based on similarity, neglecting diverse memory-recalling paradigms in humans, e.g. emotions and surroundings. To bridge the gap, we construct a novel benchmark covering various memory recalling paradigms based on cognitive science and psychology theory. The Memory Benchmark (MemBench) contains two tasks according to the two-phrase theory in cognitive science: memory retrieval, memory recognition and injection. The benchmark considers both passive and proactive memory recalling based on meta information for the first time. In addition, novel scoring aspects are proposed to comprehensively measure the generated responses. Results from the strongest embedding models and LLMs on MemBench show that there is plenty of room for improvement in existing dialogue systems. Extensive experiments also reveal the correlation between memory injection and emotion supporting (ES) skillfulness, and intimacy. Our code and dataset will be released.
Read more9/24/2024