MA-LMM: Memory-Augmented Large Multimodal Model for Long-Term Video Understanding
2404.05726
0
0
Abstract
With the success of large language models (LLMs), integrating the vision model into LLMs to build vision-language foundation models has gained much more interest recently. However, existing LLM-based large multimodal models (e.g., Video-LLaMA, VideoChat) can only take in a limited number of frames for short video understanding. In this study, we mainly focus on designing an efficient and effective model for long-term video understanding. Instead of trying to process more frames simultaneously like most existing work, we propose to process videos in an online manner and store past video information in a memory bank. This allows our model to reference historical video content for long-term analysis without exceeding LLMs' context length constraints or GPU memory limits. Our memory bank can be seamlessly integrated into current multimodal LLMs in an off-the-shelf manner. We conduct extensive experiments on various video understanding tasks, such as long-video understanding, video question answering, and video captioning, and our model can achieve state-of-the-art performances across multiple datasets. Code available at https://boheumd.github.io/MA-LMM/.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents MA-LMM, a Memory-Augmented Large Multimodal Model for long-term video understanding.
- MA-LMM leverages large language models and memory modules to effectively process and reason about long video sequences.
- The model demonstrates strong performance on various long-form video understanding tasks, outperforming previous state-of-the-art approaches.
Plain English Explanation
MA-LMM is a new artificial intelligence (AI) model that is designed to understand and analyze long videos. It combines the power of large language models, which are AI systems trained on vast amounts of text data, with specialized memory modules that allow the model to remember and reason about events and information over long time periods.
The key innovation of MA-LMM is its ability to process and comprehend extended video sequences, rather than just short clips. This is an important advancement, as many real-world applications require understanding the context and flow of events in longer videos, such as surveillance footage, instructional videos, or documentaries.
By leveraging large language models and memory modules, MA-LMM can better capture the semantic and temporal relationships within long videos, enabling it to perform a variety of tasks like video summarization, question answering, and long-form video understanding. This represents a significant advancement over previous approaches, which often struggled with longer video inputs.
Technical Explanation
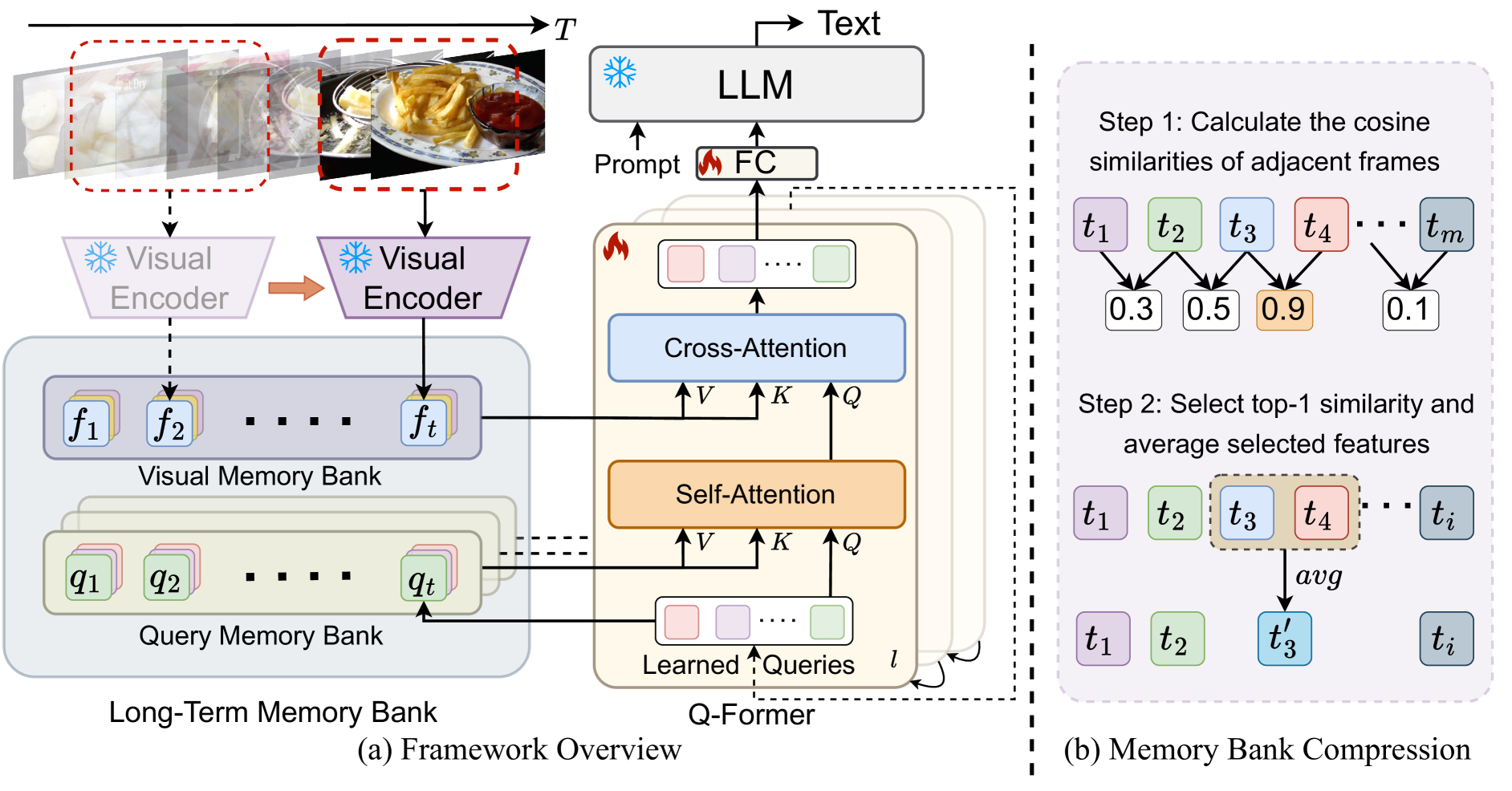
The core architecture of MA-LMM consists of a large multimodal transformer model, which is trained to process both visual and textual inputs, and a memory module that allows the model to maintain and retrieve relevant information over long time periods.
The visual inputs are encoded using pre-trained computer vision models, while the textual inputs (e.g., video captions or transcripts) are encoded using a large language model, such as BERT or GPT-3. These multimodal representations are then fed into the transformer model, which learns to reason about the relationships between the visual and textual information.
The key innovation of MA-LMM is the inclusion of a memory module, which allows the model to maintain and retrieve relevant information from previous time steps as it processes longer video sequences. This memory module is implemented using a differentiable neural memory, which can be trained end-to-end with the rest of the model.
The researchers evaluate MA-LMM on a variety of long-form video understanding tasks, such as video question answering, video summarization, and video event segmentation. The results demonstrate that MA-LMM outperforms previous state-of-the-art approaches, particularly on tasks that require understanding and reasoning about events and information over long time periods.
Critical Analysis
The authors acknowledge several limitations and potential areas for future research. For example, the memory module in MA-LMM is currently limited in its capacity and may struggle to retain and retrieve information over extremely long video sequences. Additionally, the training process for the model can be computationally intensive, which may limit its practical deployment in certain scenarios.
There are also open questions about the interpretability and explainability of the model's decision-making process, particularly when it comes to the reasoning behind its outputs. As with many large, complex AI models, it can be challenging to understand the internal workings and biases that may be present.
Further research could explore ways to improve the scalability and efficiency of the memory module, as well as investigate techniques for enhancing the model's transparency and interpretability. Incorporating additional modalities, such as audio or sensor data, could also be a fruitful direction for future work.
Conclusion
The MA-LMM model represents a significant advancement in the field of long-term video understanding, leveraging large language models and specialized memory modules to effectively process and reason about extended video sequences. The strong performance of MA-LMM on a variety of tasks highlights the potential of this approach to drive progress in applications that require understanding the context and flow of events in long-form video data, such as surveillance, education, and content curation.
As AI systems continue to become more sophisticated, the development of models like MA-LMM will be crucial for expanding the range of real-world problems that can be tackled using these technologies. While there are still challenges to address, the promising results presented in this paper suggest a bright future for memory-augmented multimodal models in the realm of long-term video understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
LongVLM: Efficient Long Video Understanding via Large Language Models
Yuetian Weng, Mingfei Han, Haoyu He, Xiaojun Chang, Bohan Zhuang
0
0
Empowered by Large Language Models (LLMs), recent advancements in VideoLLMs have driven progress in various video understanding tasks. These models encode video representations through pooling or query aggregation over a vast number of visual tokens, making computational and memory costs affordable. Despite successfully providing an overall comprehension of video content, existing VideoLLMs still face challenges in achieving detailed understanding in videos due to overlooking local information in long-term videos. To tackle this challenge, we introduce LongVLM, a straightforward yet powerful VideoLLM for long video understanding, building upon the observation that long videos often consist of sequential key events, complex actions, and camera movements. Our approach proposes to decompose long videos into multiple short-term segments and encode local features for each local segment via a hierarchical token merging module. These features are concatenated in temporal order to maintain the storyline across sequential short-term segments. Additionally, we propose to integrate global semantics into each local feature to enhance context understanding. In this way, we encode video representations that incorporate both local and global information, enabling the LLM to generate comprehensive responses for long-term videos. Experimental results on the VideoChatGPT benchmark and zero-shot video question-answering datasets demonstrate the superior capabilities of our model over the previous state-of-the-art methods. Qualitative examples demonstrate that our model produces more precise responses for long videos understanding. Code will be available at https://github.com/ziplab/LongVLM.
4/11/2024
From Image to Video, what do we need in multimodal LLMs?
Suyuan Huang, Haoxin Zhang, Yan Gao, Yao Hu, Zengchang Qin
0
0
Multimodal Large Language Models (MLLMs) have demonstrated profound capabilities in understanding multimodal information, covering from Image LLMs to the more complex Video LLMs. Numerous studies have illustrated their exceptional cross-modal comprehension. Recently, integrating video foundation models with large language models to build a comprehensive video understanding system has been proposed to overcome the limitations of specific pre-defined vision tasks. However, the current advancements in Video LLMs tend to overlook the foundational contributions of Image LLMs, often opting for more complicated structures and a wide variety of multimodal data for pre-training. This approach significantly increases the costs associated with these methods.In response to these challenges, this work introduces an efficient method that strategically leverages the priors of Image LLMs, facilitating a resource-efficient transition from Image to Video LLMs. We propose RED-VILLM, a Resource-Efficient Development pipeline for Video LLMs from Image LLMs, which utilizes a temporal adaptation plug-and-play structure within the image fusion module of Image LLMs. This adaptation extends their understanding capabilities to include temporal information, enabling the development of Video LLMs that not only surpass baseline performances but also do so with minimal instructional data and training resources. Our approach highlights the potential for a more cost-effective and scalable advancement in multimodal models, effectively building upon the foundational work of Image LLMs.
4/19/2024
MovieChat+: Question-aware Sparse Memory for Long Video Question Answering
Enxin Song, Wenhao Chai, Tian Ye, Jenq-Neng Hwang, Xi Li, Gaoang Wang
0
0
Recently, integrating video foundation models and large language models to build a video understanding system can overcome the limitations of specific pre-defined vision tasks. Yet, existing methods either employ complex spatial-temporal modules or rely heavily on additional perception models to extract temporal features for video understanding, and they only perform well on short videos. For long videos, the computational complexity and memory costs associated with long-term temporal connections are significantly increased, posing additional challenges.Taking advantage of the Atkinson-Shiffrin memory model, with tokens in Transformers being employed as the carriers of memory in combination with our specially designed memory mechanism, we propose MovieChat to overcome these challenges. We lift pre-trained multi-modal large language models for understanding long videos without incorporating additional trainable temporal modules, employing a zero-shot approach. MovieChat achieves state-of-the-art performance in long video understanding, along with the released MovieChat-1K benchmark with 1K long video, 2K temporal grounding labels, and 14K manual annotations for validation of the effectiveness of our method. The code along with the dataset can be accessed via the following https://github.com/rese1f/MovieChat.
4/29/2024

A Review of Multi-Modal Large Language and Vision Models
Kilian Carolan, Laura Fennelly, Alan F. Smeaton
0
0
Large Language Models (LLMs) have recently emerged as a focal point of research and application, driven by their unprecedented ability to understand and generate text with human-like quality. Even more recently, LLMs have been extended into multi-modal large language models (MM-LLMs) which extends their capabilities to deal with image, video and audio information, in addition to text. This opens up applications like text-to-video generation, image captioning, text-to-speech, and more and is achieved either by retro-fitting an LLM with multi-modal capabilities, or building a MM-LLM from scratch. This paper provides an extensive review of the current state of those LLMs with multi-modal capabilities as well as the very recent MM-LLMs. It covers the historical development of LLMs especially the advances enabled by transformer-based architectures like OpenAI's GPT series and Google's BERT, as well as the role of attention mechanisms in enhancing model performance. The paper includes coverage of the major and most important of the LLMs and MM-LLMs and also covers the techniques of model tuning, including fine-tuning and prompt engineering, which tailor pre-trained models to specific tasks or domains. Ethical considerations and challenges, such as data bias and model misuse, are also analysed to underscore the importance of responsible AI development and deployment. Finally, we discuss the implications of open-source versus proprietary models in AI research. Through this review, we provide insights into the transformative potential of MM-LLMs in various applications.
4/3/2024