Every Dataset Counts: Scaling up Monocular 3D Object Detection with Joint Datasets Training

0
🔎
Sign in to get full access
Overview
- Monocular 3D object detection is crucial for autonomous driving
- Existing algorithms rely on 3D labels from LiDAR, which are costly and challenging to deploy
- This study investigates training a monocular 3D model on diverse 2D and 3D datasets
Plain English Explanation
Monocular 3D object detection is the process of identifying and locating 3D objects in a single camera image. This capability is vital for autonomous vehicles, as it allows them to perceive and understand their surroundings. However, the current approaches to monocular 3D detection often depend on 3D labels derived from expensive LiDAR sensors, which can be difficult to obtain for new datasets and challenging to use in novel environments.
This research study aims to address this challenge by developing a framework that can train a monocular 3D object detection model using a diverse collection of 2D and 3D datasets. The proposed framework has three key components:
- A robust monocular 3D model that can function across various camera settings.
- A selective-training strategy to accommodate datasets with different class annotations.
- A pseudo 3D training approach that leverages 2D labels to enhance detection performance in scenes with only 2D labels.
By using this framework, the researchers were able to train models on a combination of open 3D and 2D datasets, resulting in significantly stronger generalization capabilities and improved performance on new datasets with only 2D labels available.
Technical Explanation
The proposed framework consists of three main components. The first is a robust monocular 3D model that can function across various camera settings, allowing the model to be deployed in diverse environments. The second component is a selective-training strategy that accommodates datasets with different class annotations, enabling the model to be trained on a wider range of datasets.
The third component is a pseudo 3D training approach that uses 2D labels to enhance the detection performance in scenes containing only 2D annotations. This approach leverages the available 2D data to improve the model's ability to detect 3D objects, even in the absence of full 3D labels.
The researchers conducted extensive experiments on several datasets, including KITTI, nuScenes, ONCE, Cityscapes, and BDD100K, to demonstrate the scaling ability and generalization performance of the proposed framework. By training on a diverse set of datasets, the model was able to achieve strong results on new datasets with only 2D labels, showcasing its potential for practical deployment in autonomous driving scenarios.
Critical Analysis
The research presented in this paper addresses an important challenge in the field of monocular 3D object detection, which is the dependence on costly and difficult-to-obtain 3D labels from LiDAR sensors. The proposed framework's ability to leverage a variety of 2D and 3D datasets is a significant advancement, as it allows for better generalization and performance in novel environments.
However, the paper does not explicitly discuss potential limitations or areas for further research. For example, it would be interesting to understand how the framework performs on datasets with more diverse or complex scenes, or how it handles cases where the 2D annotations are noisy or incomplete.
Additionally, the authors could have explored the trade-offs between the different components of the framework, such as the impact of the selective-training strategy or the pseudo 3D training approach on the overall model performance. This could provide valuable insights for researchers and practitioners looking to implement similar techniques.
Conclusion
This study presents a novel framework for training monocular 3D object detection models on diverse 2D and 3D datasets. By addressing the limitations of existing approaches that rely on costly 3D labels, the proposed framework enables the development of more scalable and versatile 3D detection models. The extensive experiments demonstrated the framework's ability to generalize and perform well on new datasets with only 2D labels, highlighting its potential for practical deployment in autonomous driving applications.
Overall, this research represents an important step forward in the field of monocular 3D object detection, paving the way for more accessible and robust 3D perception capabilities in autonomous vehicles and other applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
0
Every Dataset Counts: Scaling up Monocular 3D Object Detection with Joint Datasets Training
Fulong Ma, Xiaoyang Yan, Guoyang Zhao, Xiaojie Xu, Yuxuan Liu, Ming Liu
Monocular 3D object detection plays a crucial role in autonomous driving. However, existing monocular 3D detection algorithms depend on 3D labels derived from LiDAR measurements, which are costly to acquire for new datasets and challenging to deploy in novel environments. Specifically, this study investigates the pipeline for training a monocular 3D object detection model on a diverse collection of 3D and 2D datasets. The proposed framework comprises three components: (1) a robust monocular 3D model capable of functioning across various camera settings, (2) a selective-training strategy to accommodate datasets with differing class annotations, and (3) a pseudo 3D training approach using 2D labels to enhance detection performance in scenes containing only 2D labels. With this framework, we could train models on a joint set of various open 3D/2D datasets to obtain models with significantly stronger generalization capability and enhanced performance on new dataset with only 2D labels. We conduct extensive experiments on KITTI/nuScenes/ONCE/Cityscapes/BDD100K datasets to demonstrate the scaling ability of the proposed method.
Read more8/9/2024
0
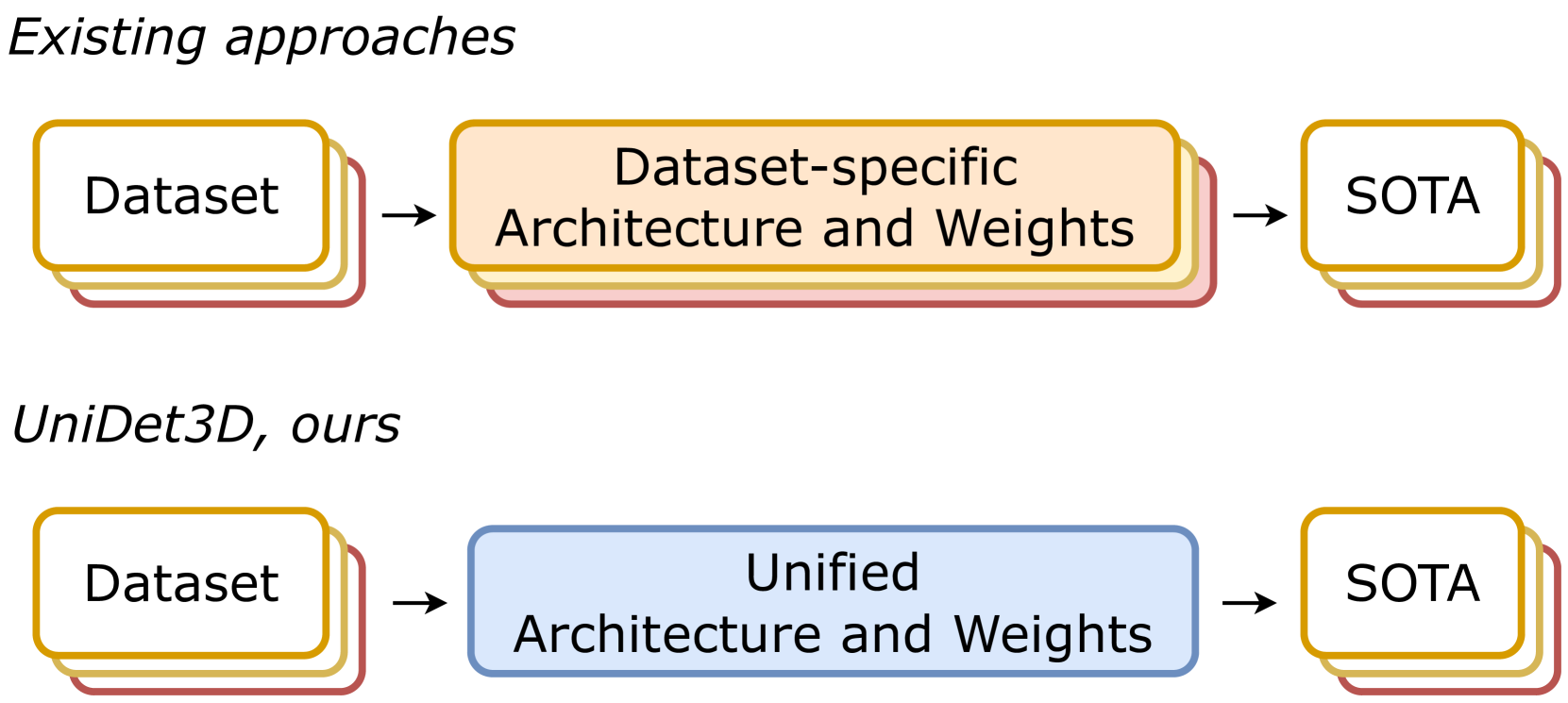
UniDet3D: Multi-dataset Indoor 3D Object Detection
Maksim Kolodiazhnyi, Anna Vorontsova, Matvey Skripkin, Danila Rukhovich, Anton Konushin
Growing customer demand for smart solutions in robotics and augmented reality has attracted considerable attention to 3D object detection from point clouds. Yet, existing indoor datasets taken individually are too small and insufficiently diverse to train a powerful and general 3D object detection model. In the meantime, more general approaches utilizing foundation models are still inferior in quality to those based on supervised training for a specific task. In this work, we propose ours{}, a simple yet effective 3D object detection model, which is trained on a mixture of indoor datasets and is capable of working in various indoor environments. By unifying different label spaces, ours{} enables learning a strong representation across multiple datasets through a supervised joint training scheme. The proposed network architecture is built upon a vanilla transformer encoder, making it easy to run, customize and extend the prediction pipeline for practical use. Extensive experiments demonstrate that ours{} obtains significant gains over existing 3D object detection methods in 6 indoor benchmarks: ScanNet (+1.1 mAP50), ARKitScenes (+19.4 mAP25), S3DIS (+9.1 mAP50), MultiScan (+9.3 mAP50), 3RScan (+3.2 mAP50), and ScanNet++ (+2.7 mAP50). Code is available at https://github.com/filapro/unidet3d .
Read more9/9/2024

0
Sparse Points to Dense Clouds: Enhancing 3D Detection with Limited LiDAR Data
Aakash Kumar, Chen Chen, Ajmal Mian, Neils Lobo, Mubarak Shah
3D detection is a critical task that enables machines to identify and locate objects in three-dimensional space. It has a broad range of applications in several fields, including autonomous driving, robotics and augmented reality. Monocular 3D detection is attractive as it requires only a single camera, however, it lacks the accuracy and robustness required for real world applications. High resolution LiDAR on the other hand, can be expensive and lead to interference problems in heavy traffic given their active transmissions. We propose a balanced approach that combines the advantages of monocular and point cloud-based 3D detection. Our method requires only a small number of 3D points, that can be obtained from a low-cost, low-resolution sensor. Specifically, we use only 512 points, which is just 1% of a full LiDAR frame in the KITTI dataset. Our method reconstructs a complete 3D point cloud from this limited 3D information combined with a single image. The reconstructed 3D point cloud and corresponding image can be used by any multi-modal off-the-shelf detector for 3D object detection. By using the proposed network architecture with an off-the-shelf multi-modal 3D detector, the accuracy of 3D detection improves by 20% compared to the state-of-the-art monocular detection methods and 6% to 9% compare to the baseline multi-modal methods on KITTI and JackRabbot datasets.
Read more4/11/2024

0
Transfer Learning from Simulated to Real Scenes for Monocular 3D Object Detection
Sondos Mohamed, Walter Zimmer, Ross Greer, Ahmed Alaaeldin Ghita, Modesto Castrill'on-Santana, Mohan Trivedi, Alois Knoll, Salvatore Mario Carta, Mirko Marras
Accurately detecting 3D objects from monocular images in dynamic roadside scenarios remains a challenging problem due to varying camera perspectives and unpredictable scene conditions. This paper introduces a two-stage training strategy to address these challenges. Our approach initially trains a model on the large-scale synthetic dataset, RoadSense3D, which offers a diverse range of scenarios for robust feature learning. Subsequently, we fine-tune the model on a combination of real-world datasets to enhance its adaptability to practical conditions. Experimental results of the Cube R-CNN model on challenging public benchmarks show a remarkable improvement in detection performance, with a mean average precision rising from 0.26 to 12.76 on the TUM Traffic A9 Highway dataset and from 2.09 to 6.60 on the DAIR-V2X-I dataset when performing transfer learning. Code, data, and qualitative video results are available on the project website: https://roadsense3d.github.io.
Read more8/29/2024