Evidence from counterfactual tasks supports emergent analogical reasoning in large language models
2404.13070
0
0

Abstract
We recently reported evidence that large language models are capable of solving a wide range of text-based analogy problems in a zero-shot manner, indicating the presence of an emergent capacity for analogical reasoning. Two recent commentaries have challenged these results, citing evidence from so-called `counterfactual' tasks in which the standard sequence of the alphabet is arbitrarily permuted so as to decrease similarity with materials that may have been present in the language model's training data. Here, we reply to these critiques, clarifying some misunderstandings about the test materials used in our original work, and presenting evidence that language models are also capable of generalizing to these new counterfactual task variants.
Create account to get full access
Overview
- This paper presents evidence that large language models (LLMs) can exhibit emergent analogical reasoning, where they can reason about counterfactual scenarios beyond their training data.
- The researchers designed a series of "counterfactual" tasks that go beyond standard language understanding tests, challenging LLMs to reason about hypothetical situations that deviate from reality.
- The results suggest that LLMs can engage in analogical reasoning, drawing inferences and making predictions about unfamiliar situations by leveraging their broad knowledge and language understanding.
Plain English Explanation
Analogical reasoning is the ability to understand how different things are related and apply that knowledge to new situations. This paper explores whether large language models (LLMs), which are AI systems trained on vast amounts of text data, can exhibit this type of reasoning.
The researchers designed a series of "counterfactual" tasks, where the models were asked to reason about hypothetical scenarios that were different from the real-world situations they were trained on. For example, they might be asked to predict what would happen if a TV was turned off, or if a character in a story had made a different choice.
The results suggest that LLMs are able to go beyond simply reciting information from their training data and can engage in analogical reasoning to make inferences about these novel, counterfactual situations. This suggests that these models have a deeper understanding of language and the world, and can apply that knowledge in flexible and creative ways.
The researchers believe this emergent analogical reasoning in LLMs is an important capability that could have implications for how we design and use these powerful AI systems. It suggests that LLMs may be able to reason about hypothetical scenarios and make informed predictions, which could be useful in fields like decision-making, risk assessment, and creative problem-solving.
Technical Explanation
The paper presents a series of experiments designed to test the counterfactual reasoning abilities of large language models (LLMs). The researchers created a set of "counterfactual tasks" that challenged the models to reason about hypothetical situations that deviated from the real-world data they were trained on.
For example, one task asked the models to predict what would happen if a TV show character made a different choice in a story. Another task involved reasoning about what would occur if a physical property of an object, like its color, was changed.
The researchers tested several state-of-the-art LLMs, including GPT-3 and Megatron-Turing NLG, on these counterfactual tasks. The models performed surprisingly well, demonstrating an ability to go beyond simply reciting information from their training data and instead engage in analogical reasoning to make plausible inferences about the novel, hypothetical scenarios.
The results suggest that LLMs possess an emergent capacity for analogical reasoning, where they can draw connections between different concepts and apply that knowledge to reason about unfamiliar situations. The researchers believe this capability arises from the models' broad understanding of language and the world, acquired through their extensive training on vast amounts of text data.
Critical Analysis
The paper provides compelling evidence that LLMs can exhibit emergent analogical reasoning, but there are still some important caveats and limitations to consider:
-
The tasks used in the experiments, while innovative, may not fully capture the nuances and complexities of real-world counterfactual reasoning. More research is needed to explore the boundaries and robustness of this capability.
-
The paper does not delve into the specific mechanisms and representations within the LLMs that enable this analogical reasoning. Further research is needed to understand the underlying cognitive processes involved.
-
The performance of the LLMs, while promising, is still far from human-level in many of the counterfactual tasks. There is room for significant improvement and refinement of these capabilities.
Additionally, the potential applications and implications of this emergent analogical reasoning in LLMs warrant further exploration and discussion. Researchers and policymakers should consider how these capabilities could be leveraged responsibly and ethically, as well as any potential risks or unintended consequences.
Conclusion
This paper presents compelling evidence that large language models (LLMs) can exhibit emergent analogical reasoning, going beyond simple language understanding to reason about hypothetical, counterfactual scenarios.
The researchers' innovative experiments suggest that LLMs can draw connections between concepts and apply their broad knowledge to make plausible inferences about unfamiliar situations. This emergent capability has significant implications for how we design and utilize these powerful AI systems, potentially enabling them to engage in more flexible, creative, and robust reasoning.
While further research is needed to fully understand the mechanisms and limitations of this analogical reasoning in LLMs, the findings of this paper represent an important step forward in our understanding of the cognitive capabilities of these advanced language models. As AI systems continue to evolve, the ability to reason about hypothetical scenarios and apply knowledge in novel ways will become increasingly crucial for tackling complex real-world challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Response: Emergent analogical reasoning in large language models
Damian Hodel, Jevin West
0
0
In their recent Nature Human Behaviour paper, Emergent analogical reasoning in large language models, (Webb, Holyoak, and Lu, 2023) the authors argue that large language models such as GPT-3 have acquired an emergent ability to find zero-shot solutions to a broad range of analogy problems. In this response, we provide counterexamples of the letter string analogies. In our tests, GPT-3 fails to solve simplest variations of the original tasks, whereas human performance remains consistently high across all modified versions. Zero-shot reasoning is an extraordinary claim that requires extraordinary evidence. We do not see that evidence in our experiments. To strengthen claims of humanlike reasoning such as zero-shot reasoning, it is important that the field develop approaches that rule out data memorization.
5/2/2024
💬
Reasoning or Reciting? Exploring the Capabilities and Limitations of Language Models Through Counterfactual Tasks
Zhaofeng Wu, Linlu Qiu, Alexis Ross, Ekin Akyurek, Boyuan Chen, Bailin Wang, Najoung Kim, Jacob Andreas, Yoon Kim
0
0
The impressive performance of recent language models across a wide range of tasks suggests that they possess a degree of abstract reasoning skills. Are these skills general and transferable, or specialized to specific tasks seen during pretraining? To disentangle these effects, we propose an evaluation framework based on counterfactual task variants that deviate from the default assumptions underlying standard tasks. Across a suite of 11 tasks, we observe nontrivial performance on the counterfactual variants, but nevertheless find that performance substantially and consistently degrades compared to the default conditions. This suggests that while current LMs may possess abstract task-solving skills to an extent, they often also rely on narrow, non-transferable procedures for task-solving. These results motivate a more careful interpretation of language model performance that teases apart these aspects of behavior.
4/1/2024

Can language models learn analogical reasoning? Investigating training objectives and comparisons to human performance
Molly R. Petersen, Lonneke van der Plas
0
0
While analogies are a common way to evaluate word embeddings in NLP, it is also of interest to investigate whether or not analogical reasoning is a task in itself that can be learned. In this paper, we test several ways to learn basic analogical reasoning, specifically focusing on analogies that are more typical of what is used to evaluate analogical reasoning in humans than those in commonly used NLP benchmarks. Our experiments find that models are able to learn analogical reasoning, even with a small amount of data. We additionally compare our models to a dataset with a human baseline, and find that after training, models approach human performance.
5/6/2024
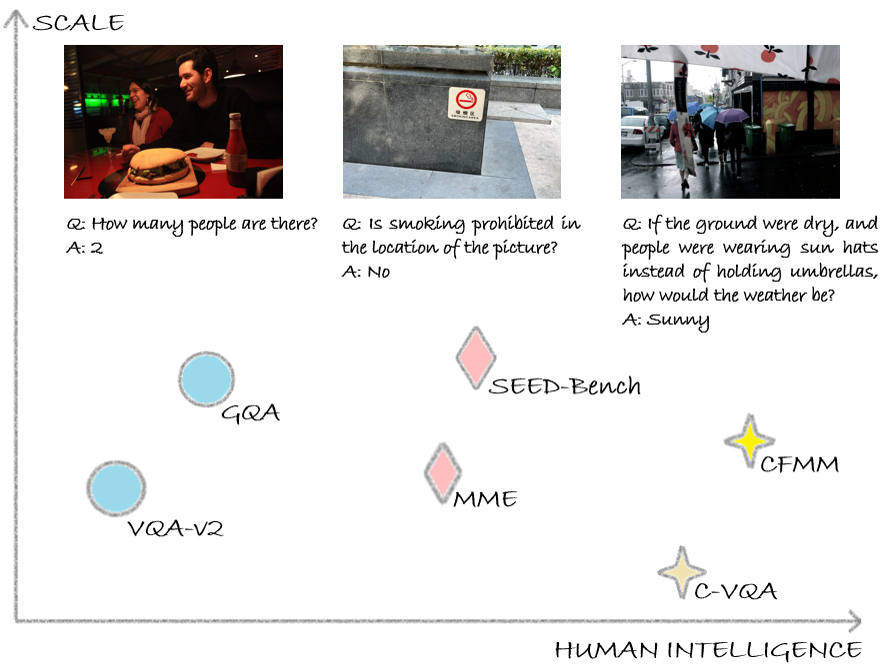
Eyes Can Deceive: Benchmarking Counterfactual Reasoning Abilities of Multi-modal Large Language Models
Yian Li, Wentao Tian, Yang Jiao, Jingjing Chen, Yu-Gang Jiang
0
0
Counterfactual reasoning, as a crucial manifestation of human intelligence, refers to making presuppositions based on established facts and extrapolating potential outcomes. Existing multimodal large language models (MLLMs) have exhibited impressive cognitive and reasoning capabilities, which have been examined across a wide range of Visual Question Answering (VQA) benchmarks. Nevertheless, how will existing MLLMs perform when faced with counterfactual questions? To answer this question, we first curate a novel textbf{C}ountertextbf{F}actual textbf{M}ultitextbf{M}odal reasoning benchmark, abbreviated as textbf{CFMM}, to systematically assess the counterfactual reasoning capabilities of MLLMs. Our CFMM comprises six challenging tasks, each including hundreds of carefully human-labeled counterfactual questions, to evaluate MLLM's counterfactual reasoning capabilities across diverse aspects. Through experiments, interestingly, we find that existing MLLMs prefer to believe what they see, but ignore the counterfactual presuppositions presented in the question, thereby leading to inaccurate responses. Furthermore, we evaluate a wide range of prevalent MLLMs on our proposed CFMM. The significant gap between their performance on our CFMM and that on several VQA benchmarks indicates that there is still considerable room for improvement in existing MLLMs toward approaching human-level intelligence. On the other hand, through boosting MLLMs performances on our CFMM in the future, potential avenues toward developing MLLMs with advanced intelligence can be explored.
4/22/2024