Evolving Scientific Discovery by Unifying Data and Background Knowledge with AI Hilbert

0
📊
Sign in to get full access
Overview
- Scientists have traditionally derived natural laws by manipulating equations based on existing knowledge, forming new equations, and verifying them experimentally.
- In recent years, data-driven scientific discovery has emerged as a viable approach, but it often fails when data is noisy or scarce.
- Recent works combine regression and reasoning to eliminate formulae inconsistent with background theory, but the problem of searching for the best-fitting formula is not well-solved.
- This paper proposes a solution to this problem when all axioms and scientific laws are expressible via polynomial equalities and inequalities.
Plain English Explanation
The paper focuses on the challenge of discovering scientific formulae that can parsimoniously explain natural phenomena while aligning with existing background theory. Historically, scientists have developed natural laws by manipulating equations based on their current understanding, creating new equations, and then verifying them through experiments. In more recent years, data-driven approaches have emerged as an alternative way to discover scientific laws, but these methods often struggle when the available data is noisy or limited.
To address this issue, the researchers propose combining regression techniques with logical reasoning to eliminate formulae that are inconsistent with the background theory. However, the challenge of finding the formula that best fits the data while being consistent with the background theory remains a difficult problem. The paper presents a solution to this problem, but it comes with the constraint that all axioms and scientific laws must be expressible as polynomial equalities and inequalities.
Technical Explanation
The paper introduces a novel approach to the problem of automated discovery of symbolic laws governing natural phenomena from experimental data and background theory. The key insight is to model notions of minimal complexity using binary variables and logical constraints, and then solve the resulting polynomial optimization problems via mixed-integer linear or semidefinite optimization.
The paper shows that this approach can derive some famous scientific laws, including Kepler's Third Law of Planetary Motion, the Hagen-Poiseuille Equation, and the Radiated Gravitational Wave Power equation, in a principled manner from axioms and experimental data. The optimization techniques leveraged in this work allow the approach to run in polynomial time with fully correct background theory, or non-deterministic polynomial (NP) time with partially correct background theory, under the assumption that the complexity of the derivation is bounded.
Critical Analysis
The paper presents a promising approach to the challenge of data-driven scientific discovery, but it does come with some limitations. The requirement that all axioms and scientific laws be expressible as polynomial equalities and inequalities may limit the applicability of the method to a subset of scientific domains. Additionally, the assumption that the complexity of the derivation is bounded may not hold in all cases, which could impact the scalability of the approach.
While the paper demonstrates the successful derivation of several famous scientific laws, it would be valuable to see the method applied to a broader range of scientific domains and data sets to fully assess its capabilities and limitations. Exploring ways to relax the polynomial constraint or develop more efficient optimization techniques could also enhance the versatility and practical applicability of the proposed approach.
Conclusion
This paper presents a novel approach to the problem of automated discovery of scientific laws from experimental data and background theory. By modeling notions of minimal complexity and leveraging advanced optimization techniques, the researchers demonstrate the ability to derive several well-known scientific laws in a principled manner. This work highlights the potential of combining regression and reasoning to overcome the limitations of purely data-driven methods, and it offers a promising direction for further research in the field of automated scientific discovery.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Evolving Scientific Discovery by Unifying Data and Background Knowledge with AI Hilbert
Ryan Cory-Wright, Cristina Cornelio, Sanjeeb Dash, Bachir El Khadir, Lior Horesh
The discovery of scientific formulae that parsimoniously explain natural phenomena and align with existing background theory is a key goal in science. Historically, scientists have derived natural laws by manipulating equations based on existing knowledge, forming new equations, and verifying them experimentally. In recent years, data-driven scientific discovery has emerged as a viable competitor in settings with large amounts of experimental data. Unfortunately, data-driven methods often fail to discover valid laws when data is noisy or scarce. Accordingly, recent works combine regression and reasoning to eliminate formulae inconsistent with background theory. However, the problem of searching over the space of formulae consistent with background theory to find one that best fits the data is not well-solved. We propose a solution to this problem when all axioms and scientific laws are expressible via polynomial equalities and inequalities and argue that our approach is widely applicable. We model notions of minimal complexity using binary variables and logical constraints, solve polynomial optimization problems via mixed-integer linear or semidefinite optimization, and prove the validity of our scientific discoveries in a principled manner using Positivstellensatz certificates. The optimization techniques leveraged in this paper allow our approach to run in polynomial time with fully correct background theory under an assumption that the complexity of our derivation is bounded), or non-deterministic polynomial (NP) time with partially correct background theory. We demonstrate that some famous scientific laws, including Kepler's Third Law of Planetary Motion, the Hagen-Poiseuille Equation, and the Radiated Gravitational Wave Power equation, can be derived in a principled manner from axioms and experimental data.
Read more4/30/2024
0
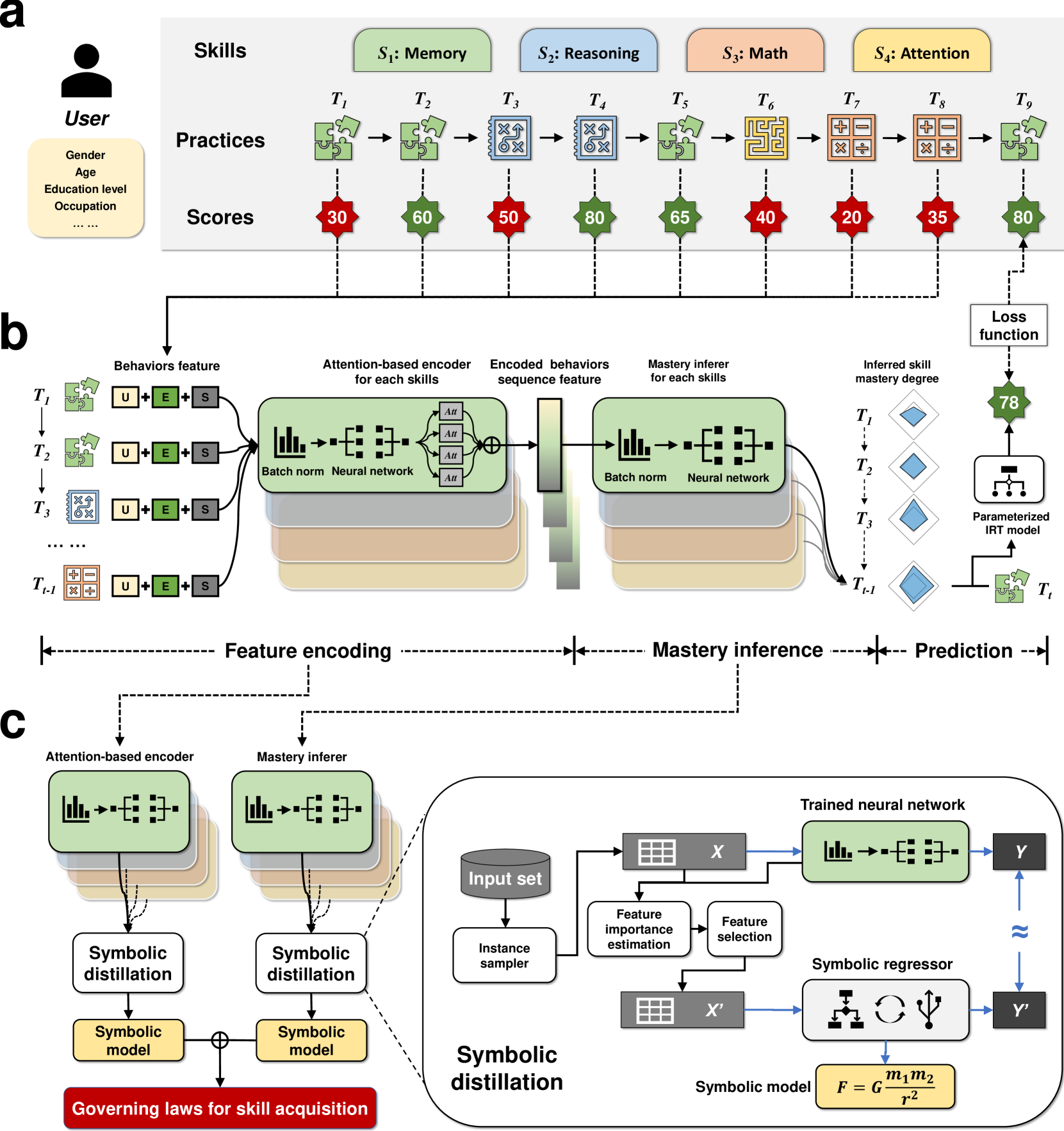
Automated discovery of symbolic laws governing skill acquisition from naturally occurring data
Sannyuya Liu, Qing Li, Xiaoxuan Shen, Jianwen Sun, Zongkai Yang
Skill acquisition is a key area of research in cognitive psychology as it encompasses multiple psychological processes. The laws discovered under experimental paradigms are controversial and lack generalizability. This paper aims to unearth the laws of skill learning from large-scale training log data. A two-stage algorithm was developed to tackle the issues of unobservable cognitive states and algorithmic explosion in searching. Initially a deep learning model is employed to determine the learner's cognitive state and assess the feature importance. Subsequently, symbolic regression algorithms are utilized to parse the neural network model into algebraic equations. Experimental results show the algorithm can accurately restore preset laws within a noise range in continuous feedback settings. When applied to Lumosity training data, the method outperforms traditional and recent models in fitness terms. The study reveals two new forms of skill acquisition laws and reaffirms some previous findings.
Read more5/28/2024

0
LLM-SR: Scientific Equation Discovery via Programming with Large Language Models
Parshin Shojaee, Kazem Meidani, Shashank Gupta, Amir Barati Farimani, Chandan K Reddy
Mathematical equations have been unreasonably effective in describing complex natural phenomena across various scientific disciplines. However, discovering such insightful equations from data presents significant challenges due to the necessity of navigating extremely high-dimensional combinatorial and nonlinear hypothesis spaces. Traditional methods of equation discovery, commonly known as symbolic regression, largely focus on extracting equations from data alone, often neglecting the rich domain-specific prior knowledge that scientists typically depend on. To bridge this gap, we introduce LLM-SR, a novel approach that leverages the extensive scientific knowledge and robust code generation capabilities of Large Language Models (LLMs) to discover scientific equations from data in an efficient manner. Specifically, LLM-SR treats equations as programs with mathematical operators and combines LLMs' scientific priors with evolutionary search over equation programs. The LLM iteratively proposes new equation skeleton hypotheses, drawing from its physical understanding, which are then optimized against data to estimate skeleton parameters. We demonstrate LLM-SR's effectiveness across three diverse scientific domains, where it discovers physically accurate equations that provide significantly better fits to in-domain and out-of-domain data compared to the well-established symbolic regression baselines. Incorporating scientific prior knowledge also enables LLM-SR to search the equation space more efficiently than baselines. Code is available at: https://github.com/deep-symbolic-mathematics/LLM-SR
Read more6/4/2024
💬
3
LLM4ED: Large Language Models for Automatic Equation Discovery
Mengge Du, Yuntian Chen, Zhongzheng Wang, Longfeng Nie, Dongxiao Zhang
Equation discovery is aimed at directly extracting physical laws from data and has emerged as a pivotal research domain. Previous methods based on symbolic mathematics have achieved substantial advancements, but often require the design of implementation of complex algorithms. In this paper, we introduce a new framework that utilizes natural language-based prompts to guide large language models (LLMs) in automatically mining governing equations from data. Specifically, we first utilize the generation capability of LLMs to generate diverse equations in string form, and then evaluate the generated equations based on observations. In the optimization phase, we propose two alternately iterated strategies to optimize generated equations collaboratively. The first strategy is to take LLMs as a black-box optimizer and achieve equation self-improvement based on historical samples and their performance. The second strategy is to instruct LLMs to perform evolutionary operators for global search. Experiments are extensively conducted on both partial differential equations and ordinary differential equations. Results demonstrate that our framework can discover effective equations to reveal the underlying physical laws under various nonlinear dynamic systems. Further comparisons are made with state-of-the-art models, demonstrating good stability and usability. Our framework substantially lowers the barriers to learning and applying equation discovery techniques, demonstrating the application potential of LLMs in the field of knowledge discovery.
Read more7/23/2024