Doing Experiments and Revising Rules with Natural Language and Probabilistic Reasoning
2402.06025
0
0
Abstract
We build a computational model of how humans actively infer hidden rules by doing experiments. The basic principles behind the model is that, even if the rule is deterministic, the learner considers a broader space of fuzzy probabilistic rules, which it represents in natural language, and updates its hypotheses online after each experiment according to approximately Bayesian principles. In the same framework we also model experiment design according to information-theoretic criteria. We find that the combination of these three principles -- explicit hypotheses, probabilistic rules, and online updates -- can explain human performance on a Zendo-style task, and that removing any of these components leaves the model unable to account for the data.
Create account to get full access
Overview
- Explores using natural language and probabilistic reasoning to conduct experiments and revise rules
- Focuses on the Zendo domain, which involves discovering the underlying rules of a game through trial and error
- Proposes a model that can learn and update rules based on player interactions and feedback
Plain English Explanation
This research paper explores using natural language and probabilistic reasoning to help people conduct experiments and revise rules. The researchers focused on a game called Zendo, where players try to discover the underlying rules by making guesses and getting feedback.
The key idea is to develop a model that can learn and update rules based on player interactions and feedback. The model uses natural language to understand the player's guesses and the feedback provided, and then updates its understanding of the rules in a probabilistic way.
By combining natural language processing and probabilistic reasoning, the researchers aim to create a system that can more effectively help players discover the rules of Zendo, or potentially other complex domains. This could be useful in learning symbolic laws that govern skill acquisition or automatically extracting linguistic descriptions from fuzzy rules.
Technical Explanation
The researchers developed a model that consists of three main components:
-
Natural Language Understanding: This component uses language models to interpret the player's natural language guesses and the feedback provided by the game. It extracts relevant information about the rules being tested.
-
Probabilistic Rule Tracking: This component maintains a probabilistic representation of the current state of the rules, updating it based on the player's guesses and the feedback received.
-
Experiment Planning: This component decides what experiments (i.e., guesses) the player should try next, in order to most effectively narrow down the space of possible rules.
The model was evaluated on a dataset of human-played Zendo games, where it demonstrated the ability to learn and update rules over time, and to propose informative experiments for players.
Critical Analysis
The paper presents a compelling approach to combining natural language processing and probabilistic reasoning for the task of rule discovery. However, the researchers acknowledge several limitations and areas for future work:
- The model was only tested on the relatively simple Zendo domain, and its performance on more complex rule discovery tasks is unclear.
- The natural language understanding component relies on pre-trained language models, which may have biases or limitations that could impact the model's performance.
- The experiment planning component uses a relatively simple heuristic to decide on the next guess, and more sophisticated planning algorithms could potentially improve its efficiency.
Additionally, one could question whether the model's approach to rule discovery is truly generalizable, or if it is too closely tied to the specific mechanics of the Zendo game. Further research is needed to learn from failure and fine-tune language models for broader trial-and-error reasoning.
Conclusion
This research paper presents a novel approach to using natural language and probabilistic reasoning for the task of rule discovery, as demonstrated in the Zendo domain. The proposed model shows promise in its ability to learn and update rules over time, and to guide players towards informative experiments.
While the model has some limitations, the core ideas of combining language understanding and probabilistic reasoning could have broader implications for [systems that need to systematically compare human and language model reasoning or extract linguistic descriptions from fuzzy rules. Further research in this direction could lead to more versatile and effective systems for rule discovery and knowledge acquisition.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧪
Phenomenal Yet Puzzling: Testing Inductive Reasoning Capabilities of Language Models with Hypothesis Refinement
Linlu Qiu, Liwei Jiang, Ximing Lu, Melanie Sclar, Valentina Pyatkin, Chandra Bhagavatula, Bailin Wang, Yoon Kim, Yejin Choi, Nouha Dziri, Xiang Ren
0
0
The ability to derive underlying principles from a handful of observations and then generalize to novel situations -- known as inductive reasoning -- is central to human intelligence. Prior work suggests that language models (LMs) often fall short on inductive reasoning, despite achieving impressive success on research benchmarks. In this work, we conduct a systematic study of the inductive reasoning capabilities of LMs through iterative hypothesis refinement, a technique that more closely mirrors the human inductive process than standard input-output prompting. Iterative hypothesis refinement employs a three-step process: proposing, selecting, and refining hypotheses in the form of textual rules. By examining the intermediate rules, we observe that LMs are phenomenal hypothesis proposers (i.e., generating candidate rules), and when coupled with a (task-specific) symbolic interpreter that is able to systematically filter the proposed set of rules, this hybrid approach achieves strong results across inductive reasoning benchmarks that require inducing causal relations, language-like instructions, and symbolic concepts. However, they also behave as puzzling inductive reasoners, showing notable performance gaps between rule induction (i.e., identifying plausible rules) and rule application (i.e., applying proposed rules to instances), suggesting that LMs are proposing hypotheses without being able to actually apply the rules. Through empirical and human analyses, we further reveal several discrepancies between the inductive reasoning processes of LMs and humans, shedding light on both the potentials and limitations of using LMs in inductive reasoning tasks.
5/24/2024
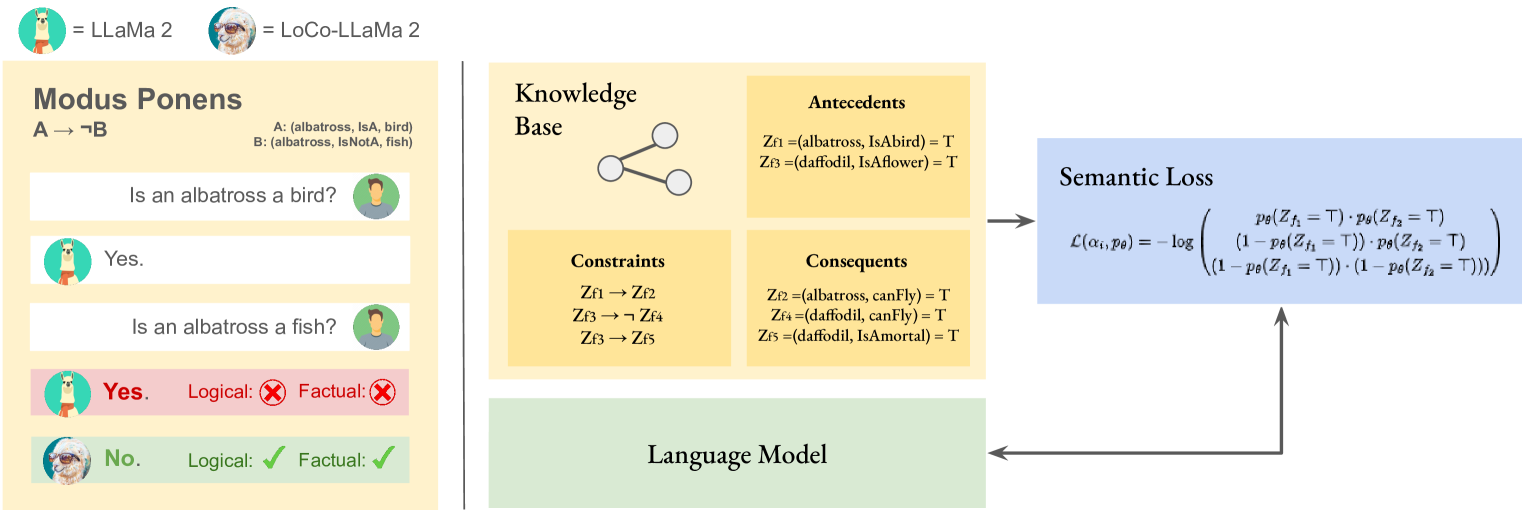
Towards Logically Consistent Language Models via Probabilistic Reasoning
Diego Calanzone, Stefano Teso, Antonio Vergari
0
0
Large language models (LLMs) are a promising venue for natural language understanding and generation tasks. However, current LLMs are far from reliable: they are prone to generate non-factual information and, more crucially, to contradict themselves when prompted to reason about beliefs of the world. These problems are currently addressed with large scale fine-tuning or by delegating consistent reasoning to external tools. In this work, we strive for a middle ground and introduce a training objective based on principled probabilistic reasoning that teaches a LLM to be consistent with external knowledge in the form of a set of facts and rules. Fine-tuning with our loss on a limited set of facts enables our LLMs to be more logically consistent than previous baselines and allows them to extrapolate to unseen but semantically similar factual knowledge more systematically.
4/22/2024
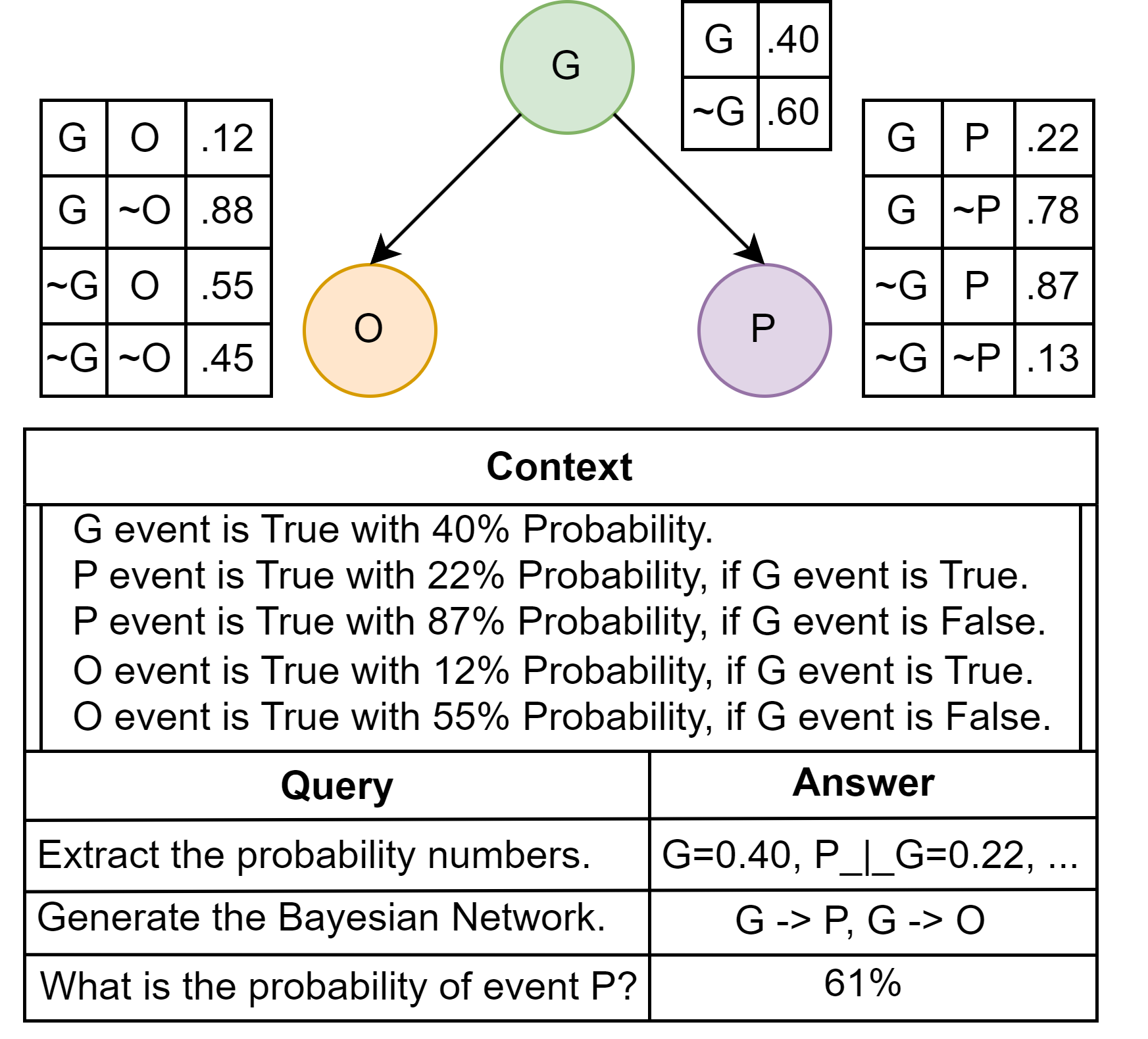
Probabilistic Reasoning in Generative Large Language Models
Aliakbar Nafar, Kristen Brent Venable, Parisa Kordjamshidi
0
0
This paper considers the challenges Large Language Models (LLMs) face when reasoning over text that includes information involving uncertainty explicitly quantified via probability values. This type of reasoning is relevant to a variety of contexts ranging from everyday conversations to medical decision-making. Despite improvements in the mathematical reasoning capabilities of LLMs, they still exhibit significant difficulties when it comes to probabilistic reasoning. To deal with this problem, we introduce the Bayesian Linguistic Inference Dataset (BLInD), a new dataset specifically designed to test the probabilistic reasoning capabilities of LLMs. We use BLInD to find out the limitations of LLMs for tasks involving probabilistic reasoning. In addition, we present several prompting strategies that map the problem to different formal representations, including Python code, probabilistic algorithms, and probabilistic logical programming. We conclude by providing an evaluation of our methods on BLInD and an adaptation of a causal reasoning question-answering dataset. Our empirical results highlight the effectiveness of our proposed strategies for multiple LLMs.
6/18/2024
💬
A Systematic Comparison of Syllogistic Reasoning in Humans and Language Models
Tiwalayo Eisape, MH Tessler, Ishita Dasgupta, Fei Sha, Sjoerd van Steenkiste, Tal Linzen
0
0
A central component of rational behavior is logical inference: the process of determining which conclusions follow from a set of premises. Psychologists have documented several ways in which humans' inferences deviate from the rules of logic. Do language models, which are trained on text generated by humans, replicate such human biases, or are they able to overcome them? Focusing on the case of syllogisms -- inferences from two simple premises -- we show that, within the PaLM2 family of transformer language models, larger models are more logical than smaller ones, and also more logical than humans. At the same time, even the largest models make systematic errors, some of which mirror human reasoning biases: they show sensitivity to the (irrelevant) ordering of the variables in the syllogism, and draw confident but incorrect inferences from particular syllogisms (syllogistic fallacies). Overall, we find that language models often mimic the human biases included in their training data, but are able to overcome them in some cases.
4/12/2024