Example-Based Framework for Perceptually Guided Audio Texture Generation
2308.11859
0
0
🛸
Abstract
Controllable generation using StyleGANs is usually achieved by training the model using labeled data. For audio textures, however, there is currently a lack of large semantically labeled datasets. Therefore, to control generation, we develop a method for semantic control over an unconditionally trained StyleGAN in the absence of such labeled datasets. In this paper, we propose an example-based framework to determine guidance vectors for audio texture generation based on user-defined semantic attributes. Our approach leverages the semantically disentangled latent space of an unconditionally trained StyleGAN. By using a few synthetic examples to indicate the presence or absence of a semantic attribute, we infer the guidance vectors in the latent space of the StyleGAN to control that attribute during generation. Our results show that our framework can find user-defined and perceptually relevant guidance vectors for controllable generation for audio textures. Furthermore, we demonstrate an application of our framework to other tasks, such as selective semantic attribute transfer.
Create account to get full access
Overview
- The paper proposes a method for controlling the generation of audio textures using an unconditionally trained StyleGAN model.
- The method leverages the semantically disentangled latent space of the StyleGAN to allow for user-defined semantic control over the generated audio textures.
- The approach uses a few synthetic examples to infer guidance vectors in the latent space that can be used to control specific semantic attributes during generation.
- The paper demonstrates the effectiveness of this framework for controllable audio texture generation and shows how it can be applied to other tasks like selective semantic attribute transfer.
Plain English Explanation
The paper is about a way to control the generation of audio textures, which are like the background sounds you might hear in a video game or movie. Normally, to get this kind of control, you need to train the model on a lot of labeled data, which can be hard to come by for audio textures.
Instead, the researchers developed a method that allows you to control the generation of audio textures even if you don't have a lot of labeled data. The key is that they use a pre-trained StyleGAN model, which has learned a latent space that's organized in a way that makes the different aspects of the audio textures easy to control.
The researchers show that by giving the model just a few examples of what you want, it can figure out how to adjust the latent space to generate audio textures with the specific characteristics you're looking for. This means you can create audio textures with the exact properties you need, without having to gather a huge dataset first.
The paper also demonstrates how this framework can be used for other tasks, like selectively transferring certain attributes from one audio texture to another. Overall, it's a clever way to get fine-grained control over audio texture generation without needing a lot of labeled data.
Technical Explanation
The paper proposes an example-based framework to determine guidance vectors for controlling the generation of audio textures using an unconditionally trained StyleGAN model.
The key insight is that the latent space of an unconditionally trained StyleGAN is semantically disentangled, meaning different dimensions of the latent space correspond to different semantic attributes of the generated output. The researchers leverage this property to infer guidance vectors in the latent space that can be used to control specific semantic attributes during audio texture generation.
To do this, the researchers use a few synthetic examples that indicate the presence or absence of a desired semantic attribute. They then use these examples to find the guidance vectors in the latent space that correspond to that attribute. These guidance vectors can then be used to steer the generation of new audio textures towards the desired semantic properties.
The paper demonstrates the effectiveness of this framework through experiments on controllable audio texture generation. Furthermore, the researchers show how this approach can be applied to other tasks, such as selective semantic attribute transfer, where certain attributes of one audio texture are transferred to another.
Critical Analysis
The paper presents a novel and interesting approach to the challenge of controlling audio texture generation in the absence of large semantically labeled datasets. The use of a pre-trained, semantically disentangled StyleGAN model is a clever way to sidestep the data scarcity problem and enable fine-grained control over the generated outputs.
However, the paper does not extensively discuss the limitations of this approach. For example, it's unclear how well the method would scale to controlling a large number of semantic attributes, or how robust the inferred guidance vectors would be to changes in the underlying StyleGAN model. Additionally, the paper does not explore the potential biases or artifacts that may be introduced by the synthetic examples used to determine the guidance vectors.
Furthermore, the paper does not compare its approach to other weakly supervised or unsupervised methods for controllable audio texture generation. It would be informative to understand how this framework performs relative to other techniques in terms of control, quality, and generalization.
Overall, the paper presents a promising approach, but further research is needed to fully understand its strengths, weaknesses, and potential applications within the broader context of controllable audio generation.
Conclusion
This paper introduces an innovative framework for enabling semantic control over the generation of audio textures, even in the absence of large labeled datasets. By leveraging the disentangled latent space of a pre-trained StyleGAN model, the researchers demonstrate a way to infer guidance vectors that can steer the generation process towards user-defined attributes.
The results show the effectiveness of this approach for controllable audio texture generation, and the researchers also highlight its potential for other applications, such as selective attribute transfer. While the paper does not fully address the limitations of the method, it offers a compelling solution to a challenging problem in the field of generative audio modeling. Further exploration and comparison with other techniques could help to further refine and validate this framework, potentially leading to new advancements in the state of the art for controllable audio generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
ICGAN: An implicit conditioning method for interpretable feature control of neural audio synthesis
Yunyi Liu, Craig Jin
0
0
Neural audio synthesis methods can achieve high-fidelity and realistic sound generation by utilizing deep generative models. Such models typically rely on external labels which are often discrete as conditioning information to achieve guided sound generation. However, it remains difficult to control the subtle changes in sounds without appropriate and descriptive labels, especially given a limited dataset. This paper proposes an implicit conditioning method for neural audio synthesis using generative adversarial networks that allows for interpretable control of the acoustic features of synthesized sounds. Our technique creates a continuous conditioning space that enables timbre manipulation without relying on explicit labels. We further introduce an evaluation metric to explore controllability and demonstrate that our approach is effective in enabling a degree of controlled variation of different synthesized sound effects for in-domain and cross-domain sounds.
6/12/2024
🛸
AudioLDM 2: Learning Holistic Audio Generation with Self-supervised Pretraining
Haohe Liu, Yi Yuan, Xubo Liu, Xinhao Mei, Qiuqiang Kong, Qiao Tian, Yuping Wang, Wenwu Wang, Yuxuan Wang, Mark D. Plumbley
0
0
Although audio generation shares commonalities across different types of audio, such as speech, music, and sound effects, designing models for each type requires careful consideration of specific objectives and biases that can significantly differ from those of other types. To bring us closer to a unified perspective of audio generation, this paper proposes a framework that utilizes the same learning method for speech, music, and sound effect generation. Our framework introduces a general representation of audio, called language of audio (LOA). Any audio can be translated into LOA based on AudioMAE, a self-supervised pre-trained representation learning model. In the generation process, we translate any modalities into LOA by using a GPT-2 model, and we perform self-supervised audio generation learning with a latent diffusion model conditioned on LOA. The proposed framework naturally brings advantages such as in-context learning abilities and reusable self-supervised pretrained AudioMAE and latent diffusion models. Experiments on the major benchmarks of text-to-audio, text-to-music, and text-to-speech demonstrate state-of-the-art or competitive performance against previous approaches. Our code, pretrained model, and demo are available at https://audioldm.github.io/audioldm2.
5/14/2024
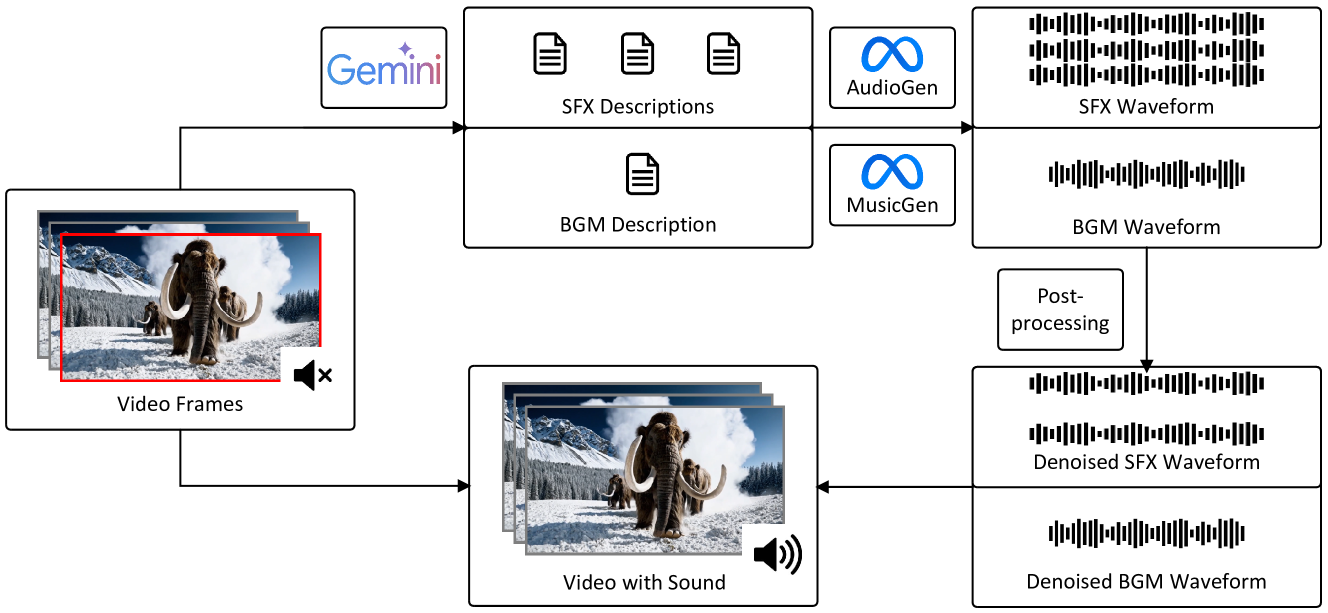
Semantically consistent Video-to-Audio Generation using Multimodal Language Large Model
Gehui Chen, Guan'an Wang, Xiaowen Huang, Jitao Sang
0
0
Existing works have made strides in video generation, but the lack of sound effects (SFX) and background music (BGM) hinders a complete and immersive viewer experience. We introduce a novel semantically consistent v ideo-to-audio generation framework, namely SVA, which automatically generates audio semantically consistent with the given video content. The framework harnesses the power of multimodal large language model (MLLM) to understand video semantics from a key frame and generate creative audio schemes, which are then utilized as prompts for text-to-audio models, resulting in video-to-audio generation with natural language as an interface. We show the satisfactory performance of SVA through case study and discuss the limitations along with the future research direction. The project page is available at https://huiz-a.github.io/audio4video.github.io/.
4/29/2024
Visual Echoes: A Simple Unified Transformer for Audio-Visual Generation
Shiqi Yang, Zhi Zhong, Mengjie Zhao, Shusuke Takahashi, Masato Ishii, Takashi Shibuya, Yuki Mitsufuji
0
0
In recent years, with the realistic generation results and a wide range of personalized applications, diffusion-based generative models gain huge attention in both visual and audio generation areas. Compared to the considerable advancements of text2image or text2audio generation, research in audio2visual or visual2audio generation has been relatively slow. The recent audio-visual generation methods usually resort to huge large language model or composable diffusion models. Instead of designing another giant model for audio-visual generation, in this paper we take a step back showing a simple and lightweight generative transformer, which is not fully investigated in multi-modal generation, can achieve excellent results on image2audio generation. The transformer operates in the discrete audio and visual Vector-Quantized GAN space, and is trained in the mask denoising manner. After training, the classifier-free guidance could be deployed off-the-shelf achieving better performance, without any extra training or modification. Since the transformer model is modality symmetrical, it could also be directly deployed for audio2image generation and co-generation. In the experiments, we show that our simple method surpasses recent image2audio generation methods. Generated audio samples can be found at https://docs.google.com/presentation/d/1ZtC0SeblKkut4XJcRaDsSTuCRIXB3ypxmSi7HTY3IyQ/
5/27/2024