Rethinking the Roles of Large Language Models in Chinese Grammatical Error Correction

0
💬
Sign in to get full access
Overview
- Large Language Models (LLMs) have been widely studied for their performance on various Natural Language Processing (NLP) tasks.
- Chinese Grammatical Error Correction (CGEC) is a fundamental NLP task that aims to correct grammatical errors in Chinese sentences.
- Previous studies have shown that LLMs' performance as correctors on CGEC remains unsatisfactory due to the challenging nature of the task.
- This research paper proposes a new approach to better utilize and explore the roles of LLMs in the CGEC task.
Plain English Explanation
The paper explores how Large Language Models (LLMs) can be used to improve the performance of Chinese Grammatical Error Correction (CGEC) systems. CGEC is a task in natural language processing where the goal is to automatically identify and correct grammatical errors in Chinese sentences.
The researchers found that while LLMs have a lot of grammatical knowledge and can understand language well, they don't perform very well when used directly as "correctors" for the CGEC task. To address this, the researchers propose two new ways to use LLMs in the CGEC process:
-
LLMs as Explainers: The researchers use LLMs to provide explanations and additional information to smaller, specialized CGEC models. This helps the CGEC models better understand the grammatical errors and make more accurate corrections.
-
LLMs as Evaluators: The researchers use LLMs to evaluate the quality of CGEC model outputs, providing more reasonable and consistent evaluations compared to human judgment, which can be subjective.
By using LLMs in these novel ways, the researchers were able to improve the overall performance of CGEC systems, making them better able to handle the challenges of this important natural language processing task.
Technical Explanation
The paper proposes a new approach to better utilize and explore the roles of Large Language Models (LLMs) in the Chinese Grammatical Error Correction (CGEC) task.
Specifically, the researchers make the following key contributions:
-
LLMs as Explainers: The researchers use LLMs to provide explanation information for smaller CGEC models during the error correction process. By leveraging the rich grammatical knowledge and powerful semantic understanding capabilities of LLMs, the CGEC models can better identify and correct grammatical errors.
-
LLMs as Evaluators: The researchers also use LLMs as evaluators to bring more reasonable and consistent CGEC evaluations, addressing the challenges posed by the subjectivity of human judgment in CGEC tasks.
-
Collaboration between LLMs and Small Models: The work explores how LLMs and smaller, specialized models can better collaborate in downstream NLP tasks, such as CGEC, to improve overall performance.
The researchers conducted extensive experiments and detailed analyses on widely used CGEC datasets to verify the effectiveness of their proposed methods. The results demonstrate the benefits of using LLMs as explainers and evaluators in the CGEC task, showing the potential for LLMs to be better utilized and explored in this and other NLP domains.
Critical Analysis
The paper presents a novel and promising approach to leveraging Large Language Models (LLMs) to improve the performance of Chinese Grammatical Error Correction (CGEC) systems.
One potential limitation of the research is that it focuses solely on the CGEC task and does not explore the broader applicability of using LLMs as explainers and evaluators for other NLP tasks. It would be interesting to see if the proposed methods can be generalized to other domains, such as evaluating mathematical reasoning in LLMs or detecting and correcting structured errors in language.
Additionally, the paper does not delve into the potential challenges or limitations of using LLMs in this way, such as the computational cost or the potential for biases or inconsistencies in the LLM-based evaluations. Further research could explore these aspects and ways to address them.
Overall, the paper presents a compelling and innovative approach to leveraging the strengths of LLMs to enhance the performance of specialized NLP models, and it serves as an important step in the ongoing efforts to rethink the roles of LLMs in various downstream tasks.
Conclusion
This research paper explores a novel approach to utilizing Large Language Models (LLMs) to improve the performance of Chinese Grammatical Error Correction (CGEC) systems. The key ideas are to use LLMs as explainers to provide additional information to CGEC models, and as evaluators to bring more reasonable and consistent assessments of CGEC model outputs.
The researchers' extensive experiments and analyses demonstrate the effectiveness of their proposed methods, highlighting the potential for LLMs to be better utilized and explored in CGEC and other NLP domains. This work represents an important step towards enhancing the collaboration between LLMs and smaller, specialized models to tackle complex language processing challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Rethinking the Roles of Large Language Models in Chinese Grammatical Error Correction
Yinghui Li, Shang Qin, Haojing Huang, Yangning Li, Libo Qin, Xuming Hu, Wenhao Jiang, Hai-Tao Zheng, Philip S. Yu
Recently, Large Language Models (LLMs) have been widely studied by researchers for their roles in various downstream NLP tasks. As a fundamental task in the NLP field, Chinese Grammatical Error Correction (CGEC) aims to correct all potential grammatical errors in the input sentences. Previous studies have shown that LLMs' performance as correctors on CGEC remains unsatisfactory due to its challenging task focus. To promote the CGEC field to better adapt to the era of LLMs, we rethink the roles of LLMs in the CGEC task so that they can be better utilized and explored in CGEC. Considering the rich grammatical knowledge stored in LLMs and their powerful semantic understanding capabilities, we utilize LLMs as explainers to provide explanation information for the CGEC small models during error correction to enhance performance. We also use LLMs as evaluators to bring more reasonable CGEC evaluations, thus alleviating the troubles caused by the subjectivity of the CGEC task. In particular, our work is also an active exploration of how LLMs and small models better collaborate in downstream tasks. Extensive experiments and detailed analyses on widely used datasets verify the effectiveness of our thinking intuition and the proposed methods.
Read more9/20/2024
0
Large Language Models Are State-of-the-Art Evaluator for Grammatical Error Correction
Masamune Kobayashi, Masato Mita, Mamoru Komachi
Large Language Models (LLMs) have been reported to outperform existing automatic evaluation metrics in some tasks, such as text summarization and machine translation. However, there has been a lack of research on LLMs as evaluators in grammatical error correction (GEC). In this study, we investigate the performance of LLMs in GEC evaluation by employing prompts designed to incorporate various evaluation criteria inspired by previous research. Our extensive experimental results demonstrate that GPT-4 achieved Kendall's rank correlation of 0.662 with human judgments, surpassing all existing methods. Furthermore, in recent GEC evaluations, we have underscored the significance of the LLMs scale and particularly emphasized the importance of fluency among evaluation criteria.
Read more5/28/2024
0
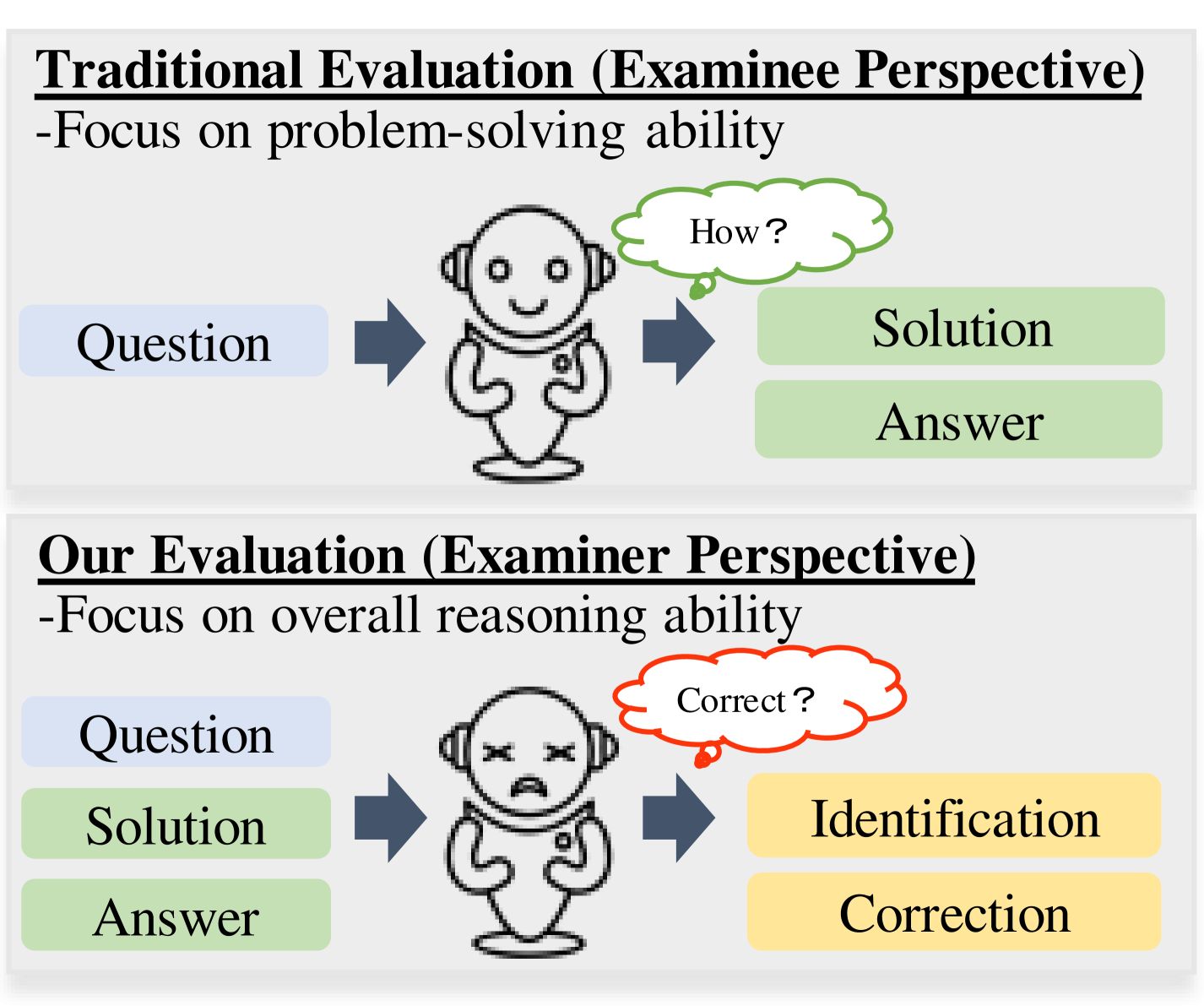
Evaluating Mathematical Reasoning of Large Language Models: A Focus on Error Identification and Correction
Xiaoyuan Li, Wenjie Wang, Moxin Li, Junrong Guo, Yang Zhang, Fuli Feng
The rapid advancement of Large Language Models (LLMs) in the realm of mathematical reasoning necessitates comprehensive evaluations to gauge progress and inspire future directions. Existing assessments predominantly focus on problem-solving from the examinee perspective, overlooking a dual perspective of examiner regarding error identification and correction. From the examiner perspective, we define four evaluation tasks for error identification and correction along with a new dataset with annotated error types and steps. We also design diverse prompts to thoroughly evaluate eleven representative LLMs. Our principal findings indicate that GPT-4 outperforms all models, while open-source model LLaMA-2-7B demonstrates comparable abilities to closed-source models GPT-3.5 and Gemini Pro. Notably, calculation error proves the most challenging error type. Moreover, prompting LLMs with the error types can improve the average correction accuracy by 47.9%. These results reveal potential directions for developing the mathematical reasoning abilities of LLMs. Our code and dataset is available on https://github.com/LittleCirc1e/EIC.
Read more6/4/2024
💬
0
Pillars of Grammatical Error Correction: Comprehensive Inspection Of Contemporary Approaches In The Era of Large Language Models
Kostiantyn Omelianchuk, Andrii Liubonko, Oleksandr Skurzhanskyi, Artem Chernodub, Oleksandr Korniienko, Igor Samokhin
In this paper, we carry out experimental research on Grammatical Error Correction, delving into the nuances of single-model systems, comparing the efficiency of ensembling and ranking methods, and exploring the application of large language models to GEC as single-model systems, as parts of ensembles, and as ranking methods. We set new state-of-the-art performance with F_0.5 scores of 72.8 on CoNLL-2014-test and 81.4 on BEA-test, respectively. To support further advancements in GEC and ensure the reproducibility of our research, we make our code, trained models, and systems' outputs publicly available.
Read more4/24/2024