Beyond Model Collapse: Scaling Up with Synthesized Data Requires Reinforcement
2406.07515
0
0

Abstract
Synthesized data from generative models is increasingly considered as an alternative to human-annotated data for fine-tuning Large Language Models. This raises concerns about model collapse: a drop in performance of models fine-tuned on generated data. Considering that it is easier for both humans and machines to tell between good and bad examples than to generate high-quality samples, we investigate the use of feedback on synthesized data to prevent model collapse. We derive theoretical conditions under which a Gaussian mixture classification model can achieve asymptotically optimal performance when trained on feedback-augmented synthesized data, and provide supporting simulations for finite regimes. We illustrate our theoretical predictions on two practical problems: computing matrix eigenvalues with transformers and news summarization with large language models, which both undergo model collapse when trained on model-generated data. We show that training from feedback-augmented synthesized data, either by pruning incorrect predictions or by selecting the best of several guesses, can prevent model collapse, validating popular approaches like RLHF.
Create account to get full access
Overview
- This research paper explores the challenges of scaling up machine learning models by using synthesized data, and proposes a reinforcement-based approach to address the problem of "model collapse" - a phenomenon where the model fails to generalize beyond the training data.
- The paper highlights the importance of overcoming model collapse when training on large-scale synthetic data, as this is a critical step towards successfully deploying machine learning in real-world applications.
Plain English Explanation
When training machine learning models, there is often a problem called "model collapse" where the model becomes too specialized to the training data and fails to generalize well to new, unseen data. This can be a significant issue when using large-scale synthesized data to train models, as the model may simply memorize the synthetic data rather than learning broader patterns.
The researchers in this paper propose a reinforcement-based approach to address this problem. The key idea is to incorporate feedback signals during the training process to encourage the model to learn more robust and generalizable representations, rather than just overfitting to the synthetic data. This builds on prior work that has explored ways to break the "curse of recursion" in generative models and prevent model collapse.
By using reinforcement, the model can learn to not only generate synthetic data, but also to assess the quality of that data in a way that aligns with the desired task performance. This helps the model avoid collapsing onto a narrow set of patterns and instead discover more diverse and useful representations. The paper also discusses how model collapse can be understood as a change in the scaling behavior of the model, which the reinforcement-based approach helps to address.
Overall, this research highlights an important challenge in scaling up machine learning systems, and proposes a novel solution that could have significant implications for the field. The ideas build on prior work on the stability of iterative retraining in generative models and the use of supervised generative optimization for tabular data.
Technical Explanation
The paper presents a reinforcement-based approach to training generative models on large-scale synthesized data, with the goal of overcoming the problem of "model collapse". The key elements of the technical approach are:
-
Reinforcement Learning Framework: The researchers formulate the model training process as a reinforcement learning problem, where the model is rewarded for generating synthetic data that is both realistic and useful for the target task.
-
Critic Network: The model is trained alongside a "critic" network that evaluates the quality of the generated data. This critic network provides the reinforcement signals to guide the model toward more generalizable representations.
-
Iterative Training: The training process involves iteratively updating the generative model and the critic network, with the critic network becoming more sophisticated over time to better assess the quality of the synthetic data.
The key insights from the technical approach are:
- Reinforcement signals can help models avoid collapsing onto narrow patterns in the training data, and instead learn more diverse and useful representations.
- The critic network plays a critical role in shaping the objective function for the generative model, guiding it toward synthetic data that is both realistic and beneficial for the target task.
- Iterative training of the generative model and critic network leads to improved stability and performance, compared to training them in isolation.
The paper evaluates the proposed approach on several benchmark tasks, demonstrating its effectiveness in overcoming model collapse and improving the performance of downstream machine learning models trained on the synthesized data.
Critical Analysis
The paper presents a compelling approach to addressing the challenge of model collapse when training on large-scale synthetic data. The reinforcement-based framework is a novel and promising direction, building on prior work in areas like breaking the curse of recursion and understanding model collapse as a change in scaling behavior.
One potential limitation of the approach is the complexity and computational overhead of training both the generative model and the critic network in an iterative fashion. The authors acknowledge this and suggest further research into more efficient training algorithms or architectures that could alleviate this issue.
Additionally, the paper focuses primarily on synthetic data generation, but it would be interesting to see how the reinforcement-based approach could be extended to other data modalities or applications where model collapse is a concern, such as the stability of iterative retraining in generative models or supervised generative optimization for tabular data.
Overall, the research presented in this paper is a significant contribution to the field of machine learning, offering a novel solution to an important problem that has broad implications for the successful deployment of large-scale AI systems.
Conclusion
This research paper presents a reinforcement-based approach to training generative models on large-scale synthesized data, with the goal of overcoming the problem of "model collapse" - a phenomenon where the model fails to generalize beyond the training data.
The key innovation is the use of a critic network that provides reinforcement signals to guide the generative model toward more diverse and useful representations, rather than collapsing onto narrow patterns in the training data. The iterative training process allows the critic network to become more sophisticated over time, further improving the quality and utility of the synthetic data.
The proposed approach has the potential to significantly advance the state of the art in machine learning, enabling the successful deployment of AI systems that can leverage large-scale synthetic data without succumbing to the pitfalls of model collapse. This research builds on and extends important prior work in areas like breaking the curse of recursion, understanding model collapse as a change in scaling behavior, and exploring the stability of iterative retraining in generative models.
While the approach presented in this paper is technically complex, the underlying ideas are conceptually straightforward and could have far-reaching implications for the field of machine learning as a whole.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

How Bad is Training on Synthetic Data? A Statistical Analysis of Language Model Collapse
Mohamed El Amine Seddik, Suei-Wen Chen, Soufiane Hayou, Pierre Youssef, Merouane Debbah
0
0
The phenomenon of model collapse, introduced in (Shumailov et al., 2023), refers to the deterioration in performance that occurs when new models are trained on synthetic data generated from previously trained models. This recursive training loop makes the tails of the original distribution disappear, thereby making future-generation models forget about the initial (real) distribution. With the aim of rigorously understanding model collapse in language models, we consider in this paper a statistical model that allows us to characterize the impact of various recursive training scenarios. Specifically, we demonstrate that model collapse cannot be avoided when training solely on synthetic data. However, when mixing both real and synthetic data, we provide an estimate of a maximal amount of synthetic data below which model collapse can eventually be avoided. Our theoretical conclusions are further supported by empirical validations.
4/9/2024
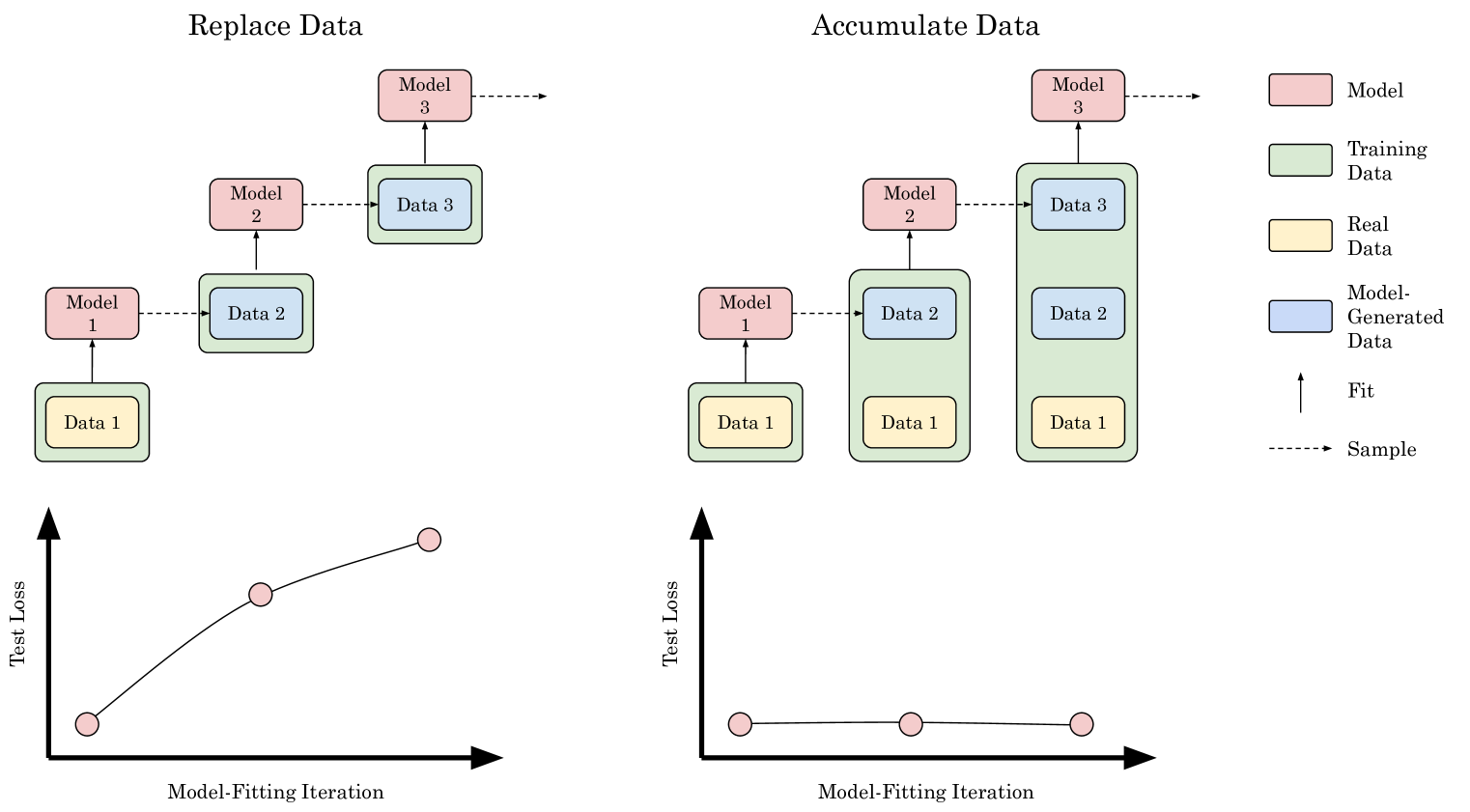
Is Model Collapse Inevitable? Breaking the Curse of Recursion by Accumulating Real and Synthetic Data
Matthias Gerstgrasser, Rylan Schaeffer, Apratim Dey, Rafael Rafailov, Henry Sleight, John Hughes, Tomasz Korbak, Rajashree Agrawal, Dhruv Pai, Andrey Gromov, Daniel A. Roberts, Diyi Yang, David L. Donoho, Sanmi Koyejo
0
0
The proliferation of generative models, combined with pretraining on web-scale data, raises a timely question: what happens when these models are trained on their own generated outputs? Recent investigations into model-data feedback loops proposed that such loops would lead to a phenomenon termed model collapse, under which performance progressively degrades with each model-data feedback iteration until fitted models become useless. However, those studies largely assumed that new data replace old data over time, where an arguably more realistic assumption is that data accumulate over time. In this paper, we ask: what effect does accumulating data have on model collapse? We empirically study this question by pretraining sequences of language models on text corpora. We confirm that replacing the original real data by each generation's synthetic data does indeed tend towards model collapse, then demonstrate that accumulating the successive generations of synthetic data alongside the original real data avoids model collapse; these results hold across a range of model sizes, architectures, and hyperparameters. We obtain similar results for deep generative models on other types of real data: diffusion models for molecule conformation generation and variational autoencoders for image generation. To understand why accumulating data can avoid model collapse, we use an analytically tractable framework introduced by prior work in which a sequence of linear models are fit to the previous models' outputs. Previous work used this framework to show that if data are replaced, the test error increases with the number of model-fitting iterations; we extend this argument to prove that if data instead accumulate, the test error has a finite upper bound independent of the number of iterations, meaning model collapse no longer occurs.
5/1/2024

A Tale of Tails: Model Collapse as a Change of Scaling Laws
Elvis Dohmatob, Yunzhen Feng, Pu Yang, Francois Charton, Julia Kempe
0
0
As AI model size grows, neural scaling laws have become a crucial tool to predict the improvements of large models when increasing capacity and the size of original (human or natural) training data. Yet, the widespread use of popular models means that the ecosystem of online data and text will co-evolve to progressively contain increased amounts of synthesized data. In this paper we ask: How will the scaling laws change in the inevitable regime where synthetic data makes its way into the training corpus? Will future models, still improve, or be doomed to degenerate up to total (model) collapse? We develop a theoretical framework of model collapse through the lens of scaling laws. We discover a wide range of decay phenomena, analyzing loss of scaling, shifted scaling with number of generations, the ''un-learning of skills, and grokking when mixing human and synthesized data. Our theory is validated by large-scale experiments with a transformer on an arithmetic task and text generation using the large language model Llama2.
6/3/2024
📊
On the Stability of Iterative Retraining of Generative Models on their own Data
Quentin Bertrand, Avishek Joey Bose, Alexandre Duplessis, Marco Jiralerspong, Gauthier Gidel
0
0
Deep generative models have made tremendous progress in modeling complex data, often exhibiting generation quality that surpasses a typical human's ability to discern the authenticity of samples. Undeniably, a key driver of this success is enabled by the massive amounts of web-scale data consumed by these models. Due to these models' striking performance and ease of availability, the web will inevitably be increasingly populated with synthetic content. Such a fact directly implies that future iterations of generative models will be trained on both clean and artificially generated data from past models. In this paper, we develop a framework to rigorously study the impact of training generative models on mixed datasets -- from classical training on real data to self-consuming generative models trained on purely synthetic data. We first prove the stability of iterative training under the condition that the initial generative models approximate the data distribution well enough and the proportion of clean training data (w.r.t. synthetic data) is large enough. We empirically validate our theory on both synthetic and natural images by iteratively training normalizing flows and state-of-the-art diffusion models on CIFAR10 and FFHQ.
4/3/2024