Explainable Biomedical Hypothesis Generation via Retrieval Augmented Generation enabled Large Language Models

0
🛸
Sign in to get full access
Overview
- Discusses the challenge of effectively processing the vast amount of biomedical information available today
- Introduces Large Language Models (LLMs) as powerful tools, but notes they can produce hallucinatory responses
- Presents RUGGED (Retrieval Under Graph-Guided Explainable disease Distinction), a workflow designed to support investigators with knowledge integration and hypothesis generation
- RUGGED leverages text-mining, association analysis, and explainable graph prediction models to identify validated paths and potential links among drugs and diseases
- The framework facilitates user-directed mechanism elucidation and hypothesis exploration through Retrieval Augmented Generation (RAG)-enabled LLMs
- A clinical use-case demonstrates RUGGED's ability to evaluate and recommend therapeutics for Arrhythmogenic Cardiomyopathy (ACM) and Dilated Cardiomyopathy (DCM)
Plain English Explanation
Researchers today have access to a vast amount of biomedical information, but it can be challenging to effectively process and understand all of these findings. Large Language Models (LLMs) have emerged as powerful tools to navigate this complex data landscape. However, LLMs can sometimes produce inaccurate or "hallucinatory" responses, which is why Retrieval Augmented Generation (RAG) is crucial for ensuring the information is reliable.
The researchers developed a system called RUGGED (Retrieval Under Graph-Guided Explainable disease Distinction) to help investigators integrate knowledge and generate hypotheses. RUGGED uses text-mining, association analysis, and graph-based models to identify potential connections between drugs and diseases. This information is then integrated into a framework that allows users to explore mechanisms and test hypotheses using RAG-enabled LLMs.
The researchers demonstrated RUGGED's capabilities by using it to evaluate and recommend potential treatments for two heart conditions, Arrhythmogenic Cardiomyopathy (ACM) and Diluted Cardiomyopathy (DCM). RUGGED was able to analyze existing drugs and their interactions, as well as suggest new potential uses for these medications. By minimizing LLM hallucinations and providing actionable insights, RUGGED aims to improve the investigation of novel therapeutics.
Technical Explanation
The researchers developed RUGGED, a comprehensive workflow to support investigators with knowledge integration and hypothesis generation. RUGGED leverages text-mining, association analysis, and explainable graph prediction models to review, integrate, and extract relevant biomedical information from publications and knowledge bases.
The workflow begins by identifying validated paths and potential links among drugs and diseases through text-mining association analysis and graph-based prediction models. These analyses, along with the original biomedical texts, are then integrated into a framework that facilitates user-directed mechanism elucidation and hypothesis exploration using RAG-enabled LLMs.
The researchers demonstrated RUGGED's capabilities through a clinical use-case evaluating therapeutics for Arrhythmogenic Cardiomyopathy (ACM) and Dilated Cardiomyopathy (DCM). RUGGED analyzed prescribed drugs for molecular interactions and unexplored uses, providing actionable insights and minimizing LLM hallucinations.
Critical Analysis
The researchers acknowledge that while RUGGED aims to minimize LLM hallucinations, there may still be some limitations in the accuracy and reliability of the information generated, as LLMs can sometimes produce biased or erroneous outputs. Additionally, the performance of the graph-based prediction models may be dependent on the quality and completeness of the underlying biomedical data, which can vary.
It would be valuable to see further research on the robustness and generalizability of RUGGED's performance across a wider range of biomedical domains and use-cases. Longitudinal studies tracking the real-world impact of RUGGED-generated insights on drug discovery and clinical decision-making would also help validate the system's practical utility.
Overall, RUGGED represents an intriguing approach to leveraging large language models and retrieval-augmented techniques to navigate the complex biomedical information landscape. As the field of AI-assisted biomedical research continues to evolve, systems like RUGGED may play an increasingly important role in supporting researchers and clinicians.
Conclusion
RUGGED is a comprehensive workflow designed to help investigators effectively process and understand the vast amount of biomedical information available today. By integrating text-mining, association analysis, and explainable graph prediction models, RUGGED identifies validated paths and potential links among drugs and diseases, facilitating knowledge integration and hypothesis generation.
The clinical use-case demonstrated RUGGED's ability to evaluate and recommend therapeutics for Arrhythmogenic Cardiomyopathy (ACM) and Dilated Cardiomyopathy (DCM), analyzing prescribed drugs and suggesting new potential uses. While RUGGED aims to minimize LLM hallucinations, further research is needed to assess its robustness and generalizability across different biomedical domains. As the field of AI-assisted biomedical research continues to evolve, systems like RUGGED may play an increasingly important role in supporting researchers and clinicians in their quest to develop novel therapeutics and improve patient outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
0
Explainable Biomedical Hypothesis Generation via Retrieval Augmented Generation enabled Large Language Models
Alexander R. Pelletier, Joseph Ramirez, Irsyad Adam, Simha Sankar, Yu Yan, Ding Wang, Dylan Steinecke, Wei Wang, Peipei Ping
The vast amount of biomedical information available today presents a significant challenge for investigators seeking to digest, process, and understand these findings effectively. Large Language Models (LLMs) have emerged as powerful tools to navigate this complex and challenging data landscape. However, LLMs may lead to hallucinatory responses, making Retrieval Augmented Generation (RAG) crucial for achieving accurate information. In this protocol, we present RUGGED (Retrieval Under Graph-Guided Explainable disease Distinction), a comprehensive workflow designed to support investigators with knowledge integration and hypothesis generation, identifying validated paths forward. Relevant biomedical information from publications and knowledge bases are reviewed, integrated, and extracted via text-mining association analysis and explainable graph prediction models on disease nodes, forecasting potential links among drugs and diseases. These analyses, along with biomedical texts, are integrated into a framework that facilitates user-directed mechanism elucidation as well as hypothesis exploration through RAG-enabled LLMs. A clinical use-case demonstrates RUGGED's ability to evaluate and recommend therapeutics for Arrhythmogenic Cardiomyopathy (ACM) and Dilated Cardiomyopathy (DCM), analyzing prescribed drugs for molecular interactions and unexplored uses. The platform minimizes LLM hallucinations, offers actionable insights, and improves the investigation of novel therapeutics.
Read more7/19/2024
0
Tool Calling: Enhancing Medication Consultation via Retrieval-Augmented Large Language Models
Zhongzhen Huang, Kui Xue, Yongqi Fan, Linjie Mu, Ruoyu Liu, Tong Ruan, Shaoting Zhang, Xiaofan Zhang
Large-scale language models (LLMs) have achieved remarkable success across various language tasks but suffer from hallucinations and temporal misalignment. To mitigate these shortcomings, Retrieval-augmented generation (RAG) has been utilized to provide external knowledge to facilitate the answer generation. However, applying such models to the medical domain faces several challenges due to the lack of domain-specific knowledge and the intricacy of real-world scenarios. In this study, we explore LLMs with RAG framework for knowledge-intensive tasks in the medical field. To evaluate the capabilities of LLMs, we introduce MedicineQA, a multi-round dialogue benchmark that simulates the real-world medication consultation scenario and requires LLMs to answer with retrieved evidence from the medicine database. MedicineQA contains 300 multi-round question-answering pairs, each embedded within a detailed dialogue history, highlighting the challenge posed by this knowledge-intensive task to current LLMs. We further propose a new textit{Distill-Retrieve-Read} framework instead of the previous textit{Retrieve-then-Read}. Specifically, the distillation and retrieval process utilizes a tool calling mechanism to formulate search queries that emulate the keyword-based inquiries used by search engines. With experimental results, we show that our framework brings notable performance improvements and surpasses the previous counterparts in the evidence retrieval process in terms of evidence retrieval accuracy. This advancement sheds light on applying RAG to the medical domain.
Read more4/30/2024
0
Improving Medical Reasoning through Retrieval and Self-Reflection with Retrieval-Augmented Large Language Models
Minbyul Jeong, Jiwoong Sohn, Mujeen Sung, Jaewoo Kang
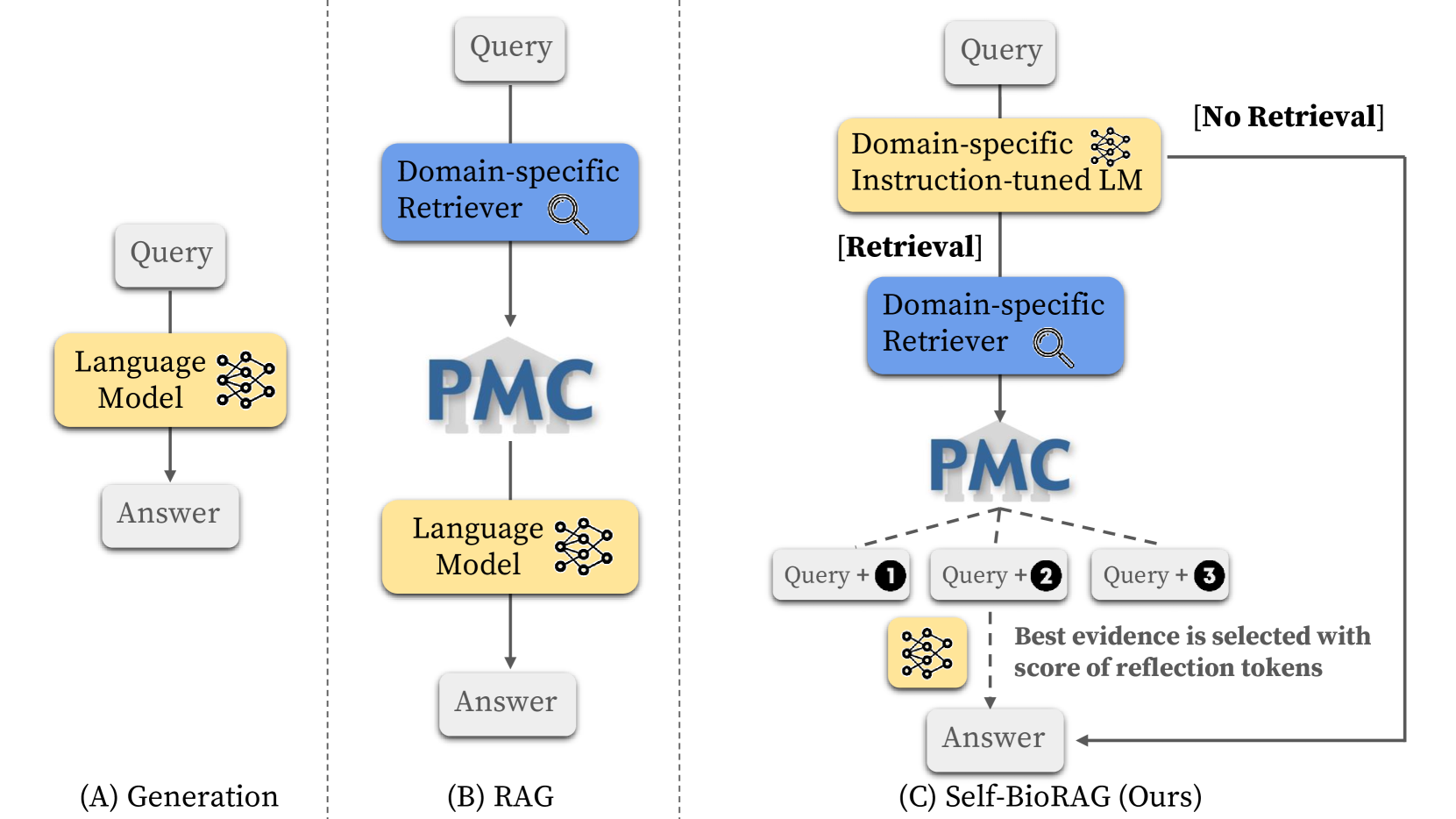
Recent proprietary large language models (LLMs), such as GPT-4, have achieved a milestone in tackling diverse challenges in the biomedical domain, ranging from multiple-choice questions to long-form generations. To address challenges that still cannot be handled with the encoded knowledge of LLMs, various retrieval-augmented generation (RAG) methods have been developed by searching documents from the knowledge corpus and appending them unconditionally or selectively to the input of LLMs for generation. However, when applying existing methods to different domain-specific problems, poor generalization becomes apparent, leading to fetching incorrect documents or making inaccurate judgments. In this paper, we introduce Self-BioRAG, a framework reliable for biomedical text that specializes in generating explanations, retrieving domain-specific documents, and self-reflecting generated responses. We utilize 84k filtered biomedical instruction sets to train Self-BioRAG that can assess its generated explanations with customized reflective tokens. Our work proves that domain-specific components, such as a retriever, domain-related document corpus, and instruction sets are necessary for adhering to domain-related instructions. Using three major medical question-answering benchmark datasets, experimental results of Self-BioRAG demonstrate significant performance gains by achieving a 7.2% absolute improvement on average over the state-of-the-art open-foundation model with a parameter size of 7B or less. Overall, we analyze that Self-BioRAG finds the clues in the question, retrieves relevant documents if needed, and understands how to answer with information from retrieved documents and encoded knowledge as a medical expert does. We release our data and code for training our framework components and model weights (7B and 13B) to enhance capabilities in biomedical and clinical domains.
Read more6/19/2024
💬
0
BiomedRAG: A Retrieval Augmented Large Language Model for Biomedicine
Mingchen Li, Halil Kilicoglu, Hua Xu, Rui Zhang
Large Language Models (LLMs) have swiftly emerged as vital resources for different applications in the biomedical and healthcare domains; however, these models encounter issues such as generating inaccurate information or hallucinations. Retrieval-augmented generation provided a solution for these models to update knowledge and enhance their performance. In contrast to previous retrieval-augmented LMs, which utilize specialized cross-attention mechanisms to help LLM encode retrieved text, BiomedRAG adopts a simpler approach by directly inputting the retrieved chunk-based documents into the LLM. This straightforward design is easily applicable to existing retrieval and language models, effectively bypassing noise information in retrieved documents, particularly in noise-intensive tasks. Moreover, we demonstrate the potential for utilizing the LLM to supervise the retrieval model in the biomedical domain, enabling it to retrieve the document that assists the LM in improving its predictions. Our experiments reveal that with the tuned scorer,textsc{ BiomedRAG} attains superior performance across 5 biomedical NLP tasks, encompassing information extraction (triple extraction, relation extraction), text classification, link prediction, and question-answering, leveraging over 9 datasets. For instance, in the triple extraction task, textsc{BiomedRAG} outperforms other triple extraction systems with micro-F1 scores of 81.42 and 88.83 on GIT and ChemProt corpora, respectively.
Read more5/6/2024