An explainable three dimension framework to uncover learning patterns: A unified look in variable sulci recognition
2309.00903
0
0
👁️
Abstract
Detecting the significant features of the learning process of an artificial intelligence framework in the entire training and validation dataset can be determined as 'global' explanations. Studies in the literature lack of accurate, low-complexity, and three-dimensional (3D) global explanations which are crucial in neuroimaging, a field with a complex representational space that demands more than basic two-dimensional interpretations. To fill this gap, we developed a novel explainable artificial intelligence (XAI) 3D-Framework that provides robust, faithful, and low-complexity global explanations. We evaluated our framework on various 3D deep learning networks trained, validated, and tested on a well-annotated cohort of 596 subjects from the TOP-OSLO study. The focus was on the presence and absence of the paracingulate sulcus, a variable feature of brain morphology correlated with psychotic conditions. Our proposed 3D-Framework outperforms traditional XAI methods in terms of faithfulness for global explanations. As a result, we were able to use these robust explanations to uncover new patterns that not only enhance the credibility and reliability of the training process but also reveal promising new biomarkers and significantly related sub-regions. For the first time, our developed 3D-Framework proposes a way for the scientific community to utilize global explanations to discover novel patterns in this specific neuroscientific application and beyond. This study can helps improve the trustworthiness of AI training processes and push the boundaries of our understanding by revealing new patterns in neuroscience and beyond.
Create account to get full access
Overview
- This paper presents a novel explainable AI (XAI) framework called 3D-Framework that provides robust, faithful, and low-complexity global explanations for 3D deep learning models.
- The framework was evaluated on 3D deep learning networks trained to detect the presence or absence of the paracingulate sulcus, a brain feature correlated with psychotic conditions, in a dataset of 596 subjects.
- The 3D-Framework outperformed traditional XAI methods in terms of faithfulness for global explanations, allowing the researchers to uncover new patterns that enhance the credibility and reliability of the training process and reveal promising new biomarkers.
Plain English Explanation
The paper discusses a new way to understand how 3D deep learning models work. When you train an AI system, it's important to be able to explain how the system arrived at its decisions. This is particularly crucial in fields like neuroscience, where the brain's structure is complex and 3D.
The researchers developed a novel XAI framework called 3D-Framework that can provide detailed, 3D explanations of how a deep learning model makes its predictions. They tested this framework on a deep learning model trained to detect a specific brain feature called the paracingulate sulcus, which is linked to certain psychiatric conditions.
The 3D-Framework was able to generate explanations that were more accurate and easier to understand than traditional methods. This allowed the researchers to uncover new insights about the training process and identify promising new biomarkers that could be used to improve our understanding of the brain and mental health conditions.
Technical Explanation
The paper presents a novel 3D explainable AI (XAI) framework that can provide robust, faithful, and low-complexity global explanations for 3D deep learning models. The researchers evaluated their 3D-Framework on various 3D deep learning networks trained, validated, and tested on a dataset of 596 subjects from the TOP-OSLO study.
The deep learning models were tasked with detecting the presence or absence of the paracingulate sulcus, a variable feature of brain morphology that is correlated with psychotic conditions. The 3D-Framework was able to outperform traditional XAI methods in terms of faithfulness for these global explanations.
By using the robust explanations generated by the 3D-Framework, the researchers were able to uncover new patterns that not only enhance the credibility and reliability of the training process, but also reveal promising new biomarkers and significantly related sub-regions of the brain. This enables the discovery of novel patterns in this specific neuroscientific application and potentially beyond.
Critical Analysis
The researchers acknowledge that their 3D-Framework is limited to providing global explanations, and that local explanations, which focus on individual predictions, may also be valuable in certain contexts. Additionally, the paper does not provide a direct comparison to other 3D XAI methods, which would help to better situate the performance of the 3D-Framework.
While the 3D-Framework was able to uncover new patterns and potential biomarkers, the paper does not delve into the specific clinical or practical implications of these findings. Further research would be needed to assess the real-world impact and utility of the identified patterns.
Additionally, the paper does not address potential biases or limitations in the underlying dataset, which could affect the reliability and generalizability of the 3D-Framework's explanations. Considering the potential biases and limitations of the data is crucial for ensuring the trustworthiness and fairness of the AI system.
Conclusion
In summary, this paper presents a novel 3D XAI framework that can generate robust, faithful, and low-complexity global explanations for 3D deep learning models. The researchers demonstrated the framework's capabilities on a 3D deep learning task related to brain morphology, uncovering new patterns and potential biomarkers that could enhance our understanding of the brain and mental health conditions.
While the 3D-Framework shows promise, further research is needed to address its limitations and explore the real-world implications of the insights it provides. Nonetheless, this work represents an important step forward in developing trustworthy and explainable AI systems that can enhance our scientific understanding and potentially lead to new breakthroughs in neuroscience and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
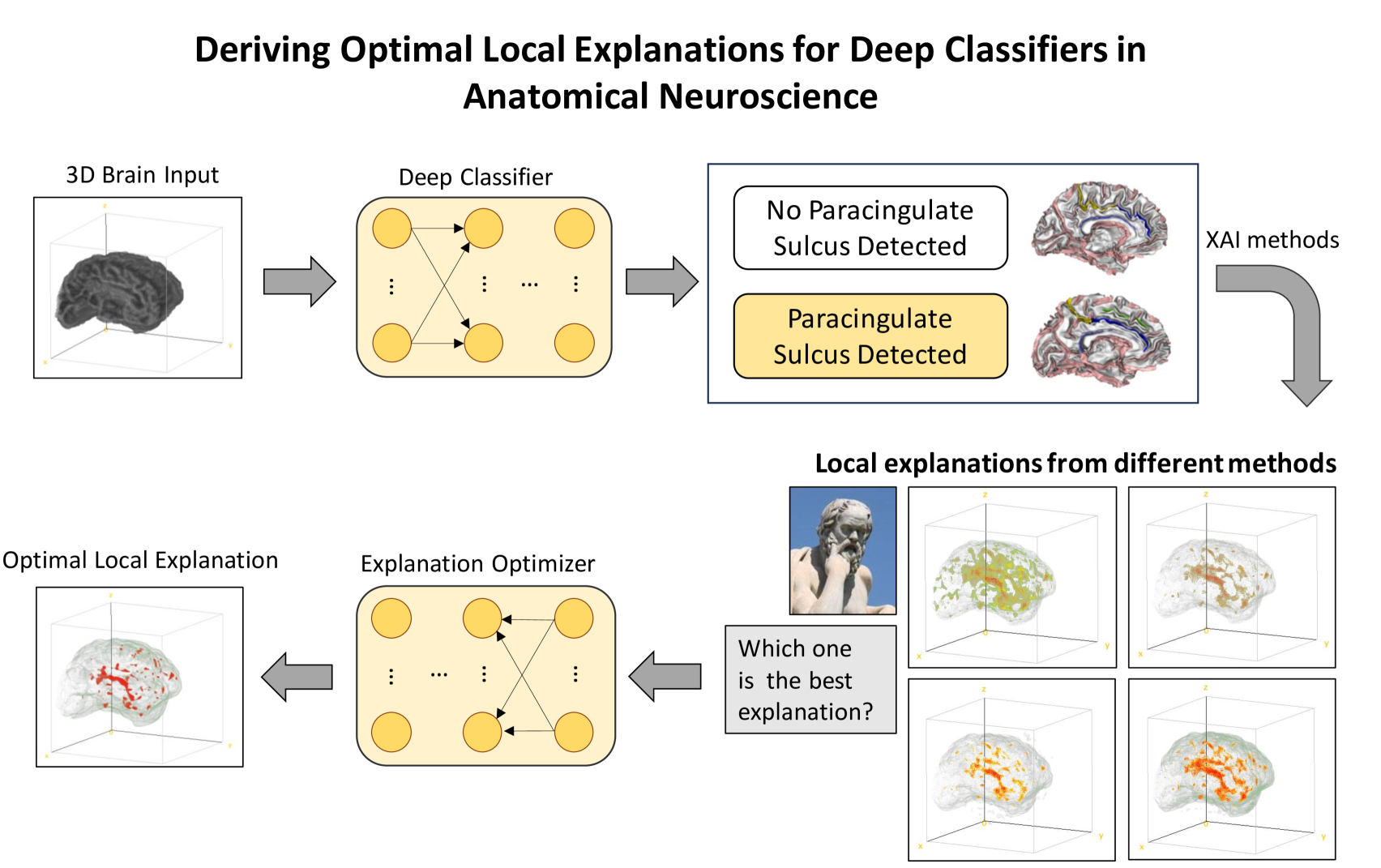
Solving the enigma: Deriving optimal explanations of deep networks
Michail Mamalakis, Antonios Mamalakis, Ingrid Agartz, Lynn Egeland M{o}rch-Johnsen, Graham Murray, John Suckling, Pietro Lio
0
0
The accelerated progress of artificial intelligence (AI) has popularized deep learning models across domains, yet their inherent opacity poses challenges, notably in critical fields like healthcare, medicine and the geosciences. Explainable AI (XAI) has emerged to shed light on these black box models, helping decipher their decision making process. Nevertheless, different XAI methods yield highly different explanations. This inter-method variability increases uncertainty and lowers trust in deep networks' predictions. In this study, for the first time, we propose a novel framework designed to enhance the explainability of deep networks, by maximizing both the accuracy and the comprehensibility of the explanations. Our framework integrates various explanations from established XAI methods and employs a non-linear explanation optimizer to construct a unique and optimal explanation. Through experiments on multi-class and binary classification tasks in 2D object and 3D neuroscience imaging, we validate the efficacy of our approach. Our explanation optimizer achieved superior faithfulness scores, averaging 155% and 63% higher than the best performing XAI method in the 3D and 2D applications, respectively. Additionally, our approach yielded lower complexity, increasing comprehensibility. Our results suggest that optimal explanations based on specific criteria are derivable and address the issue of inter-method variability in the current XAI literature.
5/17/2024
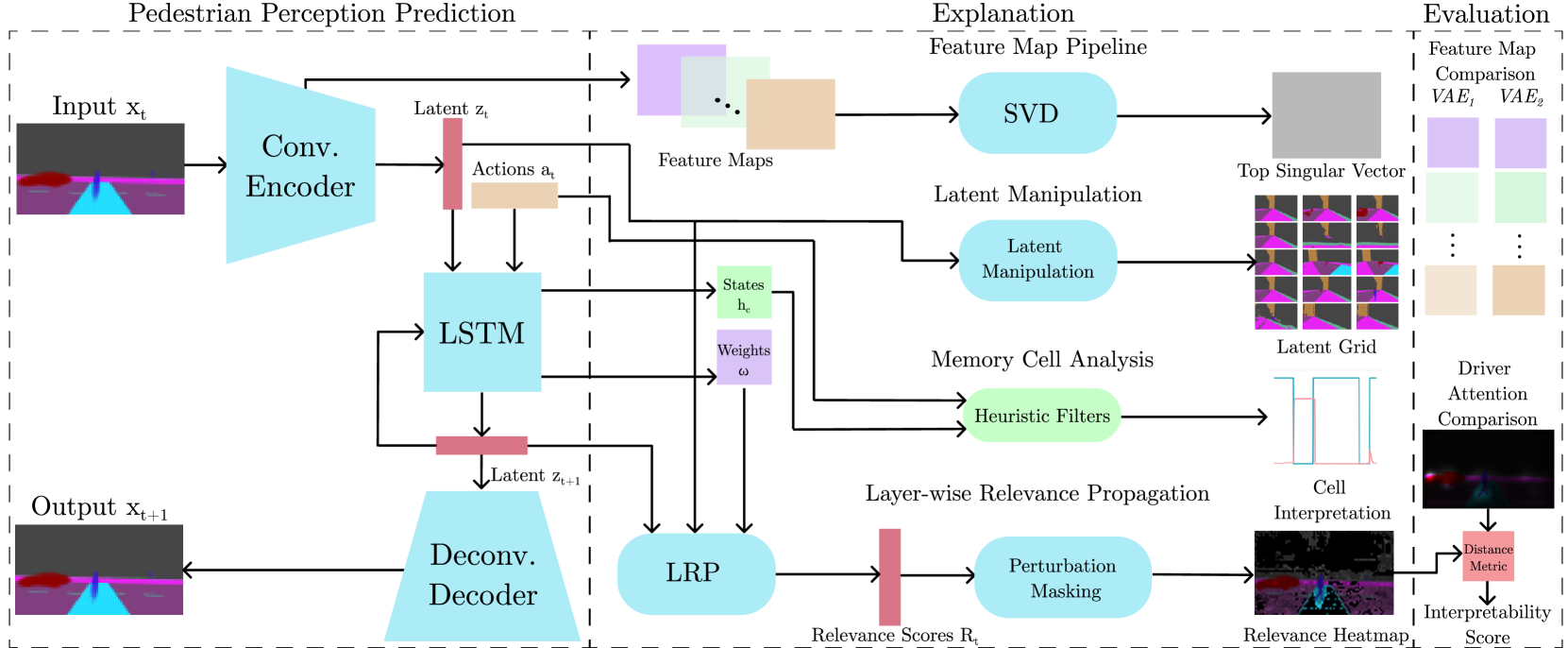
On the Road to Clarity: Exploring Explainable AI for World Models in a Driver Assistance System
Mohamed Roshdi, Julian Petzold, Mostafa Wahby, Hussein Ebrahim, Mladen Berekovic, Heiko Hamann
0
0
In Autonomous Driving (AD) transparency and safety are paramount, as mistakes are costly. However, neural networks used in AD systems are generally considered black boxes. As a countermeasure, we have methods of explainable AI (XAI), such as feature relevance estimation and dimensionality reduction. Coarse graining techniques can also help reduce dimensionality and find interpretable global patterns. A specific coarse graining method is Renormalization Groups from statistical physics. It has previously been applied to Restricted Boltzmann Machines (RBMs) to interpret unsupervised learning. We refine this technique by building a transparent backbone model for convolutional variational autoencoders (VAE) that allows mapping latent values to input features and has performance comparable to trained black box VAEs. Moreover, we propose a custom feature map visualization technique to analyze the internal convolutional layers in the VAE to explain internal causes of poor reconstruction that may lead to dangerous traffic scenarios in AD applications. In a second key contribution, we propose explanation and evaluation techniques for the internal dynamics and feature relevance of prediction networks. We test a long short-term memory (LSTM) network in the computer vision domain to evaluate the predictability and in future applications potentially safety of prediction models. We showcase our methods by analyzing a VAE-LSTM world model that predicts pedestrian perception in an urban traffic situation.
4/29/2024

Exploring Commonalities in Explanation Frameworks: A Multi-Domain Survey Analysis
Eduard Barbu, Marharytha Domnich, Raul Vicente, Nikos Sakkas, Andr'e Morim
0
0
This study presents insights gathered from surveys and discussions with specialists in three domains, aiming to find essential elements for a universal explanation framework that could be applied to these and other similar use cases. The insights are incorporated into a software tool that utilizes GP algorithms, known for their interpretability. The applications analyzed include a medical scenario (involving predictive ML), a retail use case (involving prescriptive ML), and an energy use case (also involving predictive ML). We interviewed professionals from each sector, transcribing their conversations for further analysis. Additionally, experts and non-experts in these fields filled out questionnaires designed to probe various dimensions of explanatory methods. The findings indicate a universal preference for sacrificing a degree of accuracy in favor of greater explainability. Additionally, we highlight the significance of feature importance and counterfactual explanations as critical components of such a framework. Our questionnaires are publicly available to facilitate the dissemination of knowledge in the field of XAI.
5/21/2024
🤔
Understanding the (Extra-)Ordinary: Validating Deep Model Decisions with Prototypical Concept-based Explanations
Maximilian Dreyer, Reduan Achtibat, Wojciech Samek, Sebastian Lapuschkin
0
0
Ensuring both transparency and safety is critical when deploying Deep Neural Networks (DNNs) in high-risk applications, such as medicine. The field of explainable AI (XAI) has proposed various methods to comprehend the decision-making processes of opaque DNNs. However, only few XAI methods are suitable of ensuring safety in practice as they heavily rely on repeated labor-intensive and possibly biased human assessment. In this work, we present a novel post-hoc concept-based XAI framework that conveys besides instance-wise (local) also class-wise (global) decision-making strategies via prototypes. What sets our approach apart is the combination of local and global strategies, enabling a clearer understanding of the (dis-)similarities in model decisions compared to the expected (prototypical) concept use, ultimately reducing the dependence on human long-term assessment. Quantifying the deviation from prototypical behavior not only allows to associate predictions with specific model sub-strategies but also to detect outlier behavior. As such, our approach constitutes an intuitive and explainable tool for model validation. We demonstrate the effectiveness of our approach in identifying out-of-distribution samples, spurious model behavior and data quality issues across three datasets (ImageNet, CUB-200, and CIFAR-10) utilizing VGG, ResNet, and EfficientNet architectures. Code is available on https://github.com/maxdreyer/pcx.
4/30/2024