Global Concept Explanations for Graphs by Contrastive Learning
2404.16532
0
0
🚀
Abstract
Beyond improving trust and validating model fairness, xAI practices also have the potential to recover valuable scientific insights in application domains where little to no prior human intuition exists. To that end, we propose a method to extract global concept explanations from the predictions of graph neural networks to develop a deeper understanding of the tasks underlying structure-property relationships. We identify concept explanations as dense clusters in the self-explaining Megan models subgraph latent space. For each concept, we optimize a representative prototype graph and optionally use GPT-4 to provide hypotheses about why each structure has a certain effect on the prediction. We conduct computational experiments on synthetic and real-world graph property prediction tasks. For the synthetic tasks we find that our method correctly reproduces the structural rules by which they were created. For real-world molecular property regression and classification tasks, we find that our method rediscovers established rules of thumb. More specifically, our results for molecular mutagenicity prediction indicate more fine-grained resolution of structural details than existing explainability methods, consistent with previous results from chemistry literature. Overall, our results show promising capability to extract the underlying structure-property relationships for complex graph property prediction tasks.
Create account to get full access
Overview
- The paper proposes a method to extract global concept explanations from the predictions of graph neural networks (GNNs) to develop a deeper understanding of the tasks underlying structure-property relationships.
- The method identifies concept explanations as dense clusters in the self-explaining Megan models subgraph latent space and optimizes a representative prototype graph for each concept.
- The authors conduct experiments on synthetic and real-world graph property prediction tasks, finding that the method correctly reproduces the structural rules for synthetic tasks and rediscovers established rules of thumb for real-world molecular property prediction.
Plain English Explanation
The paper explores a way to better understand how graph neural networks (GNNs) make predictions on tasks related to the properties of graphs, such as molecules. GNNs are a type of machine learning model that can analyze the structure of a graph, like the connections between atoms in a molecule, and use that information to predict properties of the graph, like whether a molecule is toxic.
The researchers propose a method that can identify the key "concepts" or patterns in the graph structure that the GNN model is using to make its predictions. This is done by looking at the internal representations the model learns and finding clusters of similar representations that correspond to important structural features. For each of these concept clusters, the method finds a representative "prototype" graph that best exemplifies that concept.
The authors test this method on both synthetic tasks, where they know the underlying rules the data was generated from, and real-world tasks like predicting the toxicity of molecules. For the synthetic tasks, they find that the method correctly identifies the structural rules used to create the data. For the real-world molecular tasks, the method uncovers patterns that match established knowledge from chemistry, but with more detailed insights than previous explainability techniques.
The goal of this work is to go beyond just validating the fairness and trustworthiness of the GNN models, and actually recover valuable scientific insights about the underlying structure-property relationships in the data. The authors believe this approach has promise for application domains where little human intuition about the task exists, allowing the method to potentially uncover new scientific discoveries.
Technical Explanation
The paper proposes a method to extract global concept explanations from the predictions of graph neural networks (GNNs) in order to develop a deeper understanding of the tasks underlying structure-property relationships. The key steps of the method are:
-
Identifying Concept Explanations: The authors identify concept explanations as dense clusters in the self-explaining Megan models subgraph latent space. This latent space represents the internal representations learned by the GNN model.
-
Optimizing Prototype Graphs: For each concept cluster, the method optimizes a representative "prototype" graph that best exemplifies that concept. This prototype serves as a concrete explanation for the concept.
-
Generating Hypotheses: Optionally, the authors use the GPT-4 language model to provide hypotheses about why each prototype structure has a certain effect on the model's predictions.
The authors conduct experiments on both synthetic and real-world graph property prediction tasks. For the synthetic tasks, they find that the method correctly reproduces the structural rules by which the data was created. For real-world molecular property regression and classification tasks, the method rediscovers established rules of thumb from the chemistry literature, but with more fine-grained resolution of structural details than existing explainability methods.
The key insight from this work is that by extracting these global concept explanations, the method can provide valuable scientific insights into the underlying structure-property relationships, even in domains where little prior human intuition exists. This goes beyond just improving trust and validating model fairness, which are important but more limited applications of explainable AI techniques.
Critical Analysis
The paper presents a promising approach for uncovering the structural patterns that drive the predictions of graph neural networks. However, there are a few potential limitations and areas for further research:
-
Dependence on Self-Explaining Models: The method relies on using Megan, a self-explaining GNN model, as the underlying architecture. It's unclear how well the approach would generalize to other GNN models that do not have this built-in explainability.
-
Scalability of Prototype Optimization: The process of optimizing a representative prototype graph for each concept cluster may become computationally expensive as the task complexity and number of concepts increase. Improvements to the optimization process could help make the method more scalable.
-
Validation of Generated Hypotheses: While the use of GPT-4 to generate hypotheses about the concepts is an interesting addition, the paper does not provide a rigorous evaluation of the quality and usefulness of these hypotheses. Further research is needed to understand the limitations and potential pitfalls of this aspect of the method.
-
Generalization to Other Domains: The experiments in this paper are focused on molecular property prediction tasks. It would be valuable to see how well the method performs on a wider range of graph-based prediction problems, such as those found in social networks, recommendation systems, or knowledge graph reasoning.
Overall, the paper presents an interesting and potentially impactful approach for extracting scientific insights from the predictions of graph neural networks. The authors have demonstrated promising results, and further research to address the limitations could help strengthen the concept activation vector methodology and its applications.
Conclusion
This paper proposes a method to extract global concept explanations from the predictions of graph neural networks, with the goal of developing a deeper understanding of the underlying structure-property relationships in the data. The key steps involve identifying concept explanations as dense clusters in the model's latent space, optimizing representative prototype graphs for each concept, and optionally generating hypotheses about the structural reasons for the concepts' effects.
The authors demonstrate the effectiveness of this approach on both synthetic and real-world molecular property prediction tasks, showing that the method can correctly reproduce structural rules and uncover established rules of thumb from chemistry, while providing more fine-grained insights than previous explainability techniques. This work goes beyond simply validating model fairness and trustworthiness, instead aiming to recover valuable scientific insights in domains where little prior human intuition exists.
While the method shows promise, the authors identify potential limitations around the dependence on self-explaining models, the scalability of the prototype optimization, and the need for further validation of the generated hypotheses. Expanding the evaluation to a wider range of graph-based prediction tasks could also help strengthen the generalizability of the approach. Overall, this research represents an exciting step towards leveraging the power of explainable AI to drive scientific discovery in complex, data-rich domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Global Human-guided Counterfactual Explanations for Molecular Properties via Reinforcement Learning
Danqing Wang, Antonis Antoniades, Kha-Dinh Luong, Edwin Zhang, Mert Kosan, Jiachen Li, Ambuj Singh, William Yang Wang, Lei Li
0
0
Counterfactual explanations of Graph Neural Networks (GNNs) offer a powerful way to understand data that can naturally be represented by a graph structure. Furthermore, in many domains, it is highly desirable to derive data-driven global explanations or rules that can better explain the high-level properties of the models and data in question. However, evaluating global counterfactual explanations is hard in real-world datasets due to a lack of human-annotated ground truth, which limits their use in areas like molecular sciences. Additionally, the increasing scale of these datasets provides a challenge for random search-based methods. In this paper, we develop a novel global explanation model RLHEX for molecular property prediction. It aligns the counterfactual explanations with human-defined principles, making the explanations more interpretable and easy for experts to evaluate. RLHEX includes a VAE-based graph generator to generate global explanations and an adapter to adjust the latent representation space to human-defined principles. Optimized by Proximal Policy Optimization (PPO), the global explanations produced by RLHEX cover 4.12% more input graphs and reduce the distance between the counterfactual explanation set and the input set by 0.47% on average across three molecular datasets. RLHEX provides a flexible framework to incorporate different human-designed principles into the counterfactual explanation generation process, aligning these explanations with domain expertise. The code and data are released at https://github.com/dqwang122/RLHEX.
6/21/2024

Knowledge graphs for empirical concept retrieval
Lenka Tv{e}tkov'a, Teresa Karen Scheidt, Maria Mandrup Fogh, Ellen Marie Gaunby J{o}rgensen, Finn {AA}rup Nielsen, Lars Kai Hansen
0
0
Concept-based explainable AI is promising as a tool to improve the understanding of complex models at the premises of a given user, viz. as a tool for personalized explainability. An important class of concept-based explainability methods is constructed with empirically defined concepts, indirectly defined through a set of positive and negative examples, as in the TCAV approach (Kim et al., 2018). While it is appealing to the user to avoid formal definitions of concepts and their operationalization, it can be challenging to establish relevant concept datasets. Here, we address this challenge using general knowledge graphs (such as, e.g., Wikidata or WordNet) for comprehensive concept definition and present a workflow for user-driven data collection in both text and image domains. The concepts derived from knowledge graphs are defined interactively, providing an opportunity for personalization and ensuring that the concepts reflect the user's intentions. We test the retrieved concept datasets on two concept-based explainability methods, namely concept activation vectors (CAVs) and concept activation regions (CARs) (Crabbe and van der Schaar, 2022). We show that CAVs and CARs based on these empirical concept datasets provide robust and accurate explanations. Importantly, we also find good alignment between the models' representations of concepts and the structure of knowledge graphs, i.e., human representations. This supports our conclusion that knowledge graph-based concepts are relevant for XAI.
4/11/2024
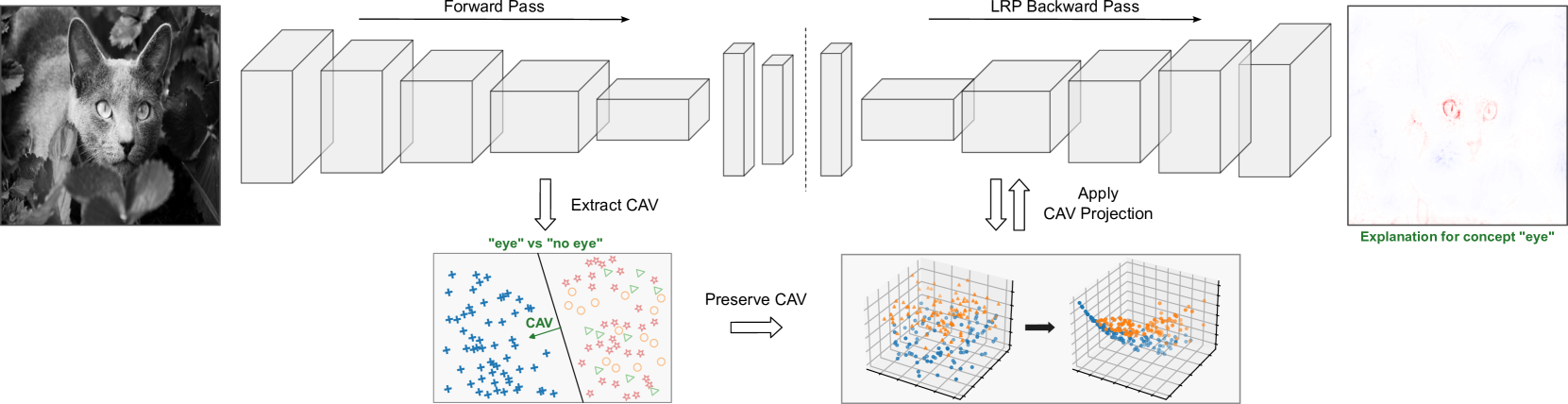
Locally Testing Model Detections for Semantic Global Concepts
Franz Motzkus, Georgii Mikriukov, Christian Hellert, Ute Schmid
0
0
Ensuring the quality of black-box Deep Neural Networks (DNNs) has become ever more significant, especially in safety-critical domains such as automated driving. While global concept encodings generally enable a user to test a model for a specific concept, linking global concept encodings to the local processing of single network inputs reveals their strengths and limitations. Our proposed framework global-to-local Concept Attribution (glCA) uses approaches from local (why a specific prediction originates) and global (how a model works generally) eXplainable Artificial Intelligence (xAI) to test DNNs for a predefined semantical concept locally. The approach allows for conditioning local, post-hoc explanations on predefined semantic concepts encoded as linear directions in the model's latent space. Pixel-exact scoring concerning the global concept usage assists the tester in further understanding the model processing of single data points for the selected concept. Our approach has the advantage of fully covering the model-internal encoding of the semantic concept and allowing the localization of relevant concept-related information. The results show major differences in the local perception and usage of individual global concept encodings and demand for further investigations regarding obtaining thorough semantic concept encodings.
5/30/2024
🤔
Understanding the (Extra-)Ordinary: Validating Deep Model Decisions with Prototypical Concept-based Explanations
Maximilian Dreyer, Reduan Achtibat, Wojciech Samek, Sebastian Lapuschkin
0
0
Ensuring both transparency and safety is critical when deploying Deep Neural Networks (DNNs) in high-risk applications, such as medicine. The field of explainable AI (XAI) has proposed various methods to comprehend the decision-making processes of opaque DNNs. However, only few XAI methods are suitable of ensuring safety in practice as they heavily rely on repeated labor-intensive and possibly biased human assessment. In this work, we present a novel post-hoc concept-based XAI framework that conveys besides instance-wise (local) also class-wise (global) decision-making strategies via prototypes. What sets our approach apart is the combination of local and global strategies, enabling a clearer understanding of the (dis-)similarities in model decisions compared to the expected (prototypical) concept use, ultimately reducing the dependence on human long-term assessment. Quantifying the deviation from prototypical behavior not only allows to associate predictions with specific model sub-strategies but also to detect outlier behavior. As such, our approach constitutes an intuitive and explainable tool for model validation. We demonstrate the effectiveness of our approach in identifying out-of-distribution samples, spurious model behavior and data quality issues across three datasets (ImageNet, CUB-200, and CIFAR-10) utilizing VGG, ResNet, and EfficientNet architectures. Code is available on https://github.com/maxdreyer/pcx.
4/30/2024