Explaining Spectrograms in Machine Learning: A Study on Neural Networks for Speech Classification

0
Sign in to get full access
Overview
- Explains spectrograms, a visual representation of sound, and how they are used in machine learning for speech classification tasks
- Examines the performance and interpretability of neural networks trained on spectrogram data
- Provides a technical explanation of the research methods and findings, as well as a critical analysis of the approach
Plain English Explanation
Spectrograms are visual diagrams that show the different frequencies present in a sound over time. They are commonly used in speech recognition and audio analysis tasks. This paper explores how well neural networks, a type of machine learning model, can use spectrograms to classify different speech signals.
The researchers trained neural networks to recognize different spoken words or sounds based on their spectrogram representations. They found that the neural networks were generally able to achieve good classification accuracy, meaning they could correctly identify the speech samples.
However, the researchers also wanted to understand how the neural networks were making their decisions. They used techniques to "look inside" the neural networks and see which parts of the spectrogram were most influential in the classification process. This can help make the models more interpretable and allow researchers to better understand how the neural networks are processing the speech data.
Overall, this research provides insights into how machine learning models can leverage spectrograms for speech recognition, and highlights the importance of developing interpretable AI systems that can explain their reasoning.
Technical Explanation
The paper begins by providing background on spectrograms and their use in machine learning for speech classification tasks. Spectrograms are visual representations of the frequency spectrum of a sound signal over time, allowing researchers to analyze the different frequency components present.
The researchers evaluated the performance and interpretability of neural networks trained on spectrogram data for speech classification. They trained several neural network architectures, including convolutional neural networks (CNNs) and long short-term memory (LSTMs) networks, on spectrogram representations of speech samples. The models were tasked with classifying the speech samples into different categories, such as spoken words or phonemes.
The results showed that the neural networks were generally able to achieve high classification accuracy, demonstrating the potential of spectrograms as an effective input representation for speech recognition tasks. To further understand the models' decision-making process, the researchers utilized techniques like layer visualization and saliency maps to identify the most influential regions of the spectrograms for the neural networks' predictions.
These interpretability techniques revealed insights into how the neural networks were processing the spectrogram data. For example, the models were found to focus on specific frequency bands and temporal patterns that were most discriminative for the speech classification task.
Critical Analysis
The paper provides a comprehensive evaluation of neural networks' performance and interpretability when working with spectrogram data for speech classification. However, the researchers acknowledge several limitations and areas for further research:
- The experiments were conducted on a relatively small dataset, and it would be valuable to evaluate the models' performance on larger, more diverse speech datasets.
- The interpretability techniques used, while informative, may not fully capture the complex decision-making processes of the neural networks. Exploring additional interpretability approaches could provide further insights.
- The paper does not delve into the practical implications of this research, such as how the insights could be used to improve speech recognition systems or make them more transparent to users.
Additionally, one could question whether the focus on spectrogram-based models is the best approach for speech classification, or if other input representations (e.g., raw audio, mel-spectrograms) may be more effective. Comparing the proposed approach to alternative methods could provide a more holistic understanding of the trade-offs.
Conclusion
This paper offers a detailed investigation into the use of spectrograms as input for neural networks in speech classification tasks. The researchers demonstrate the potential of these models to achieve high accuracy, while also highlighting the importance of developing interpretable AI systems that can explain their decision-making process.
The insights gained from this work could contribute to the development of more robust and transparent speech recognition systems, which could have important applications in areas such as assistive technology, voice-based user interfaces, and audio-based interaction. By continuing to explore the interpretability of machine learning models, researchers can work toward building AI systems that are not only effective, but also understandable and trustworthy.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Explaining Spectrograms in Machine Learning: A Study on Neural Networks for Speech Classification
Jesin James, Balamurali B. T., Binu Abeysinghe, Junchen Liu
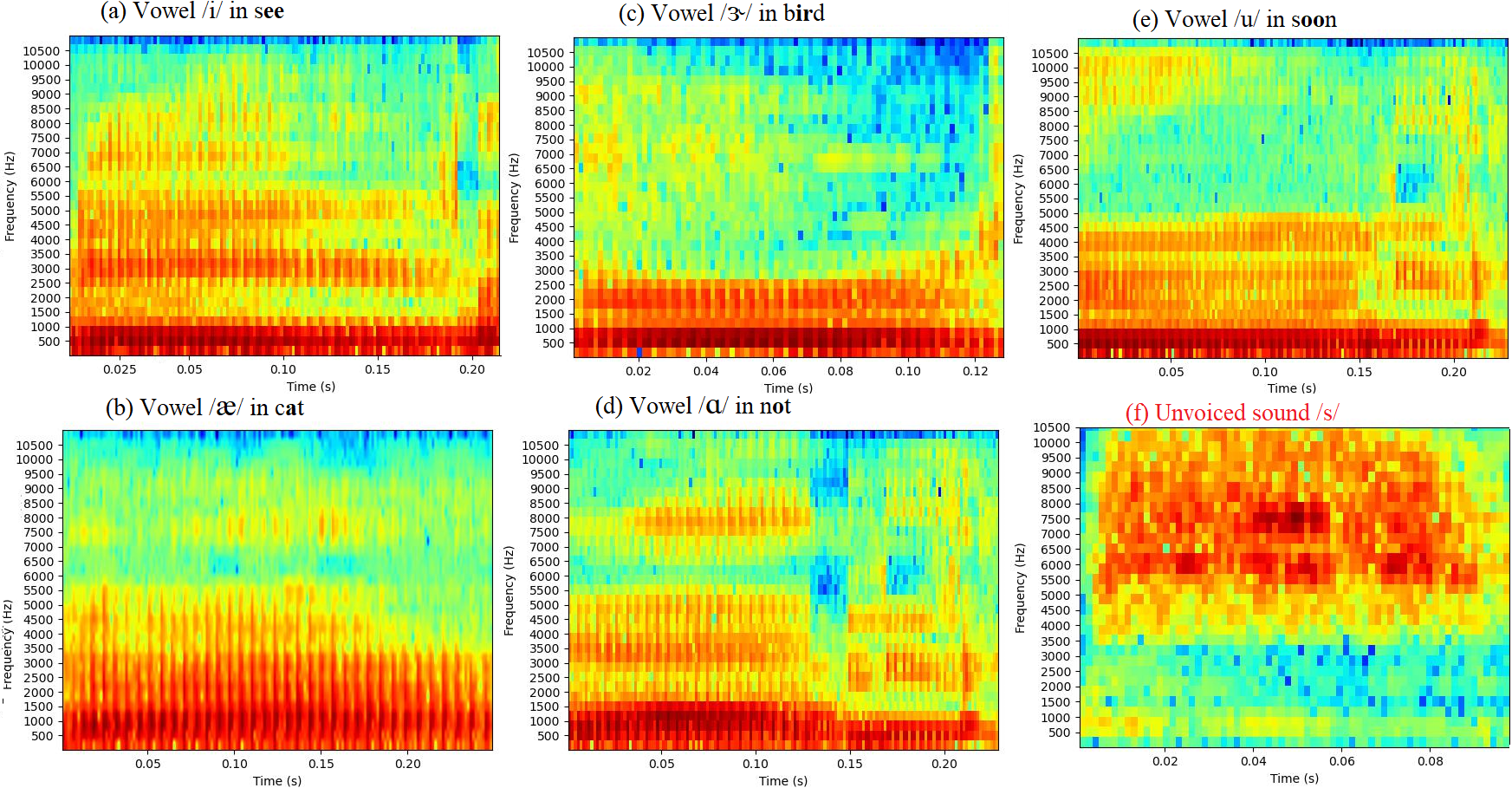
This study investigates discriminative patterns learned by neural networks for accurate speech classification, with a specific focus on vowel classification tasks. By examining the activations and features of neural networks for vowel classification, we gain insights into what the networks see in spectrograms. Through the use of class activation mapping, we identify the frequencies that contribute to vowel classification and compare these findings with linguistic knowledge. Experiments on a American English dataset of vowels showcases the explainability of neural networks and provides valuable insights into the causes of misclassifications and their characteristics when differentiating them from unvoiced speech. This study not only enhances our understanding of the underlying acoustic cues in vowel classification but also offers opportunities for improving speech recognition by bridging the gap between abstract representations in neural networks and established linguistic knowledge
Read more7/25/2024

0
Toward end-to-end interpretable convolutional neural networks for waveform signals
Linh Vu, Thu Tran, Wern-Han Lim, Raphael Phan
This paper introduces a novel convolutional neural networks (CNN) framework tailored for end-to-end audio deep learning models, presenting advancements in efficiency and explainability. By benchmarking experiments on three standard speech emotion recognition datasets with five-fold cross-validation, our framework outperforms Mel spectrogram features by up to seven percent. It can potentially replace the Mel-Frequency Cepstral Coefficients (MFCC) while remaining lightweight. Furthermore, we demonstrate the efficiency and interpretability of the front-end layer using the PhysioNet Heart Sound Database, illustrating its ability to handle and capture intricate long waveform patterns. Our contributions offer a portable solution for building efficient and interpretable models for raw waveform data.
Read more5/6/2024

0
Improving Robustness of Spectrogram Classifiers with Neural Stochastic Differential Equations
Joel Brogan, Olivera Kotevska, Anibely Torres, Sumit Jha, Mark Adams
Signal analysis and classification is fraught with high levels of noise and perturbation. Computer-vision-based deep learning models applied to spectrograms have proven useful in the field of signal classification and detection; however, these methods aren't designed to handle the low signal-to-noise ratios inherent within non-vision signal processing tasks. While they are powerful, they are currently not the method of choice in the inherently noisy and dynamic critical infrastructure domain, such as smart-grid sensing, anomaly detection, and non-intrusive load monitoring.
Read more9/4/2024
🌐
0
Automatic Assessment of Dysarthria Using Audio-visual Vowel Graph Attention Network
Xiaokang Liu, Xiaoxia Du, Juan Liu, Rongfeng Su, Manwa Lawrence Ng, Yumei Zhang, Yudong Yang, Shaofeng Zhao, Lan Wang, Nan Yan
Automatic assessment of dysarthria remains a highly challenging task due to high variability in acoustic signals and the limited data. Currently, research on the automatic assessment of dysarthria primarily focuses on two approaches: one that utilizes expert features combined with machine learning, and the other that employs data-driven deep learning methods to extract representations. Research has demonstrated that expert features are effective in representing pathological characteristics, while deep learning methods excel at uncovering latent features. Therefore, integrating the advantages of expert features and deep learning to construct a neural network architecture based on expert knowledge may be beneficial for interpretability and assessment performance. In this context, the present paper proposes a vowel graph attention network based on audio-visual information, which effectively integrates the strengths of expert knowledges and deep learning. Firstly, various features were combined as inputs, including knowledge based acoustical features and deep learning based pre-trained representations. Secondly, the graph network structure based on vowel space theory was designed, allowing for a deep exploration of spatial correlations among vowels. Finally, visual information was incorporated into the model to further enhance its robustness and generalizability. The method exhibited superior performance in regression experiments targeting Frenchay scores compared to existing approaches.
Read more5/8/2024