Explanation as a Watermark: Towards Harmless and Multi-bit Model Ownership Verification via Watermarking Feature Attribution
2405.04825
0
0
📈
Abstract
Ownership verification is currently the most critical and widely adopted post-hoc method to safeguard model copyright. In general, model owners exploit it to identify whether a given suspicious third-party model is stolen from them by examining whether it has particular properties inherited' from their released models. Currently, backdoor-based model watermarks are the primary and cutting-edge methods to implant such properties in the released models. However, backdoor-based methods have two fatal drawbacks, including harmfulness and ambiguity. The former indicates that they introduce maliciously controllable misclassification behaviors ($i.e.$, backdoor) to the watermarked released models. The latter denotes that malicious users can easily pass the verification by finding other misclassified samples, leading to ownership ambiguity. In this paper, we argue that both limitations stem from the zero-bit' nature of existing watermarking schemes, where they exploit the status ($i.e.$, misclassified) of predictions for verification. Motivated by this understanding, we design a new watermarking paradigm, $i.e.$, Explanation as a Watermark (EaaW), that implants verification behaviors into the explanation of feature attribution instead of model predictions. Specifically, EaaW embeds a `multi-bit' watermark into the feature attribution explanation of specific trigger samples without changing the original prediction. We correspondingly design the watermark embedding and extraction algorithms inspired by explainable artificial intelligence. In particular, our approach can be used for different tasks ($e.g.$, image classification and text generation). Extensive experiments verify the effectiveness and harmlessness of our EaaW and its resistance to potential attacks.
Create account to get full access
Overview
- Current methods for verifying model ownership, called "backdoor-based watermarks," have significant drawbacks including introducing harmful behavior and ambiguity in ownership claims.
- This paper proposes a new approach called "Explanation as a Watermark" (EaaW) that embeds a watermark into the feature attribution explanation of a model, rather than its predictions.
- EaaW aims to address the limitations of existing watermarking methods while maintaining effectiveness and harmlessness.
Plain English Explanation
When companies or researchers create machine learning models, they often want to protect their intellectual property and ensure their models are not being used without permission. Existing watermarking methods try to achieve this by embedding a hidden "watermark" into the model that can be detected later to prove ownership.
However, the current leading watermarking approach, called "backdoor-based watermarks," has some significant problems. First, they can cause the model to make harmful or unintended mistakes on certain inputs. Second, bad actors can sometimes bypass the watermark detection by finding other inputs that the model misclassifies, making it unclear who the true owner is.
The authors of this paper realized that these limitations stem from the fact that existing watermarks rely on the model's final predictions, which are a "single bit" of information. To address this, they propose a new approach called "Explanation as a Watermark" (EaaW). Instead of embedding the watermark in the model's predictions, EaaW hides the watermark in the model's explanation of how it arrived at its predictions - the "feature attribution" that highlights which input features were most important.
By embedding the watermark in this more complex, "multi-bit" explanation information rather than just the final prediction, the authors believe they can create a more robust and harmless watermarking system. They describe the technical details of how EaaW works for different machine learning tasks like image classification and text generation, and show through experiments that it is effective at detecting ownership while avoiding the issues of previous methods.
Technical Explanation
The core idea behind the proposed "Explanation as a Watermark" (EaaW) approach is to embed a watermark into the feature attribution explanation of a model, rather than its final predictions. Feature attribution explains which input features were most important for a model's prediction.
The authors design algorithms to embed a multi-bit watermark into the feature attribution of specific "trigger" samples, without changing the original model prediction. This allows the watermark to be reliably detected later to verify model ownership, while avoiding the introduction of harmful backdoor behaviors or ambiguity in ownership claims.
Specifically, the EaaW watermarking process has two main steps:
-
Watermark Embedding: The model owner selects trigger samples and embeds a unique watermark into the feature attribution explanations for those samples, using optimization techniques inspired by XAI (explainable AI) research.
-
Watermark Extraction: When verifying ownership, the model owner extracts the watermark from the feature attribution of a suspicious model by comparing it to the original watermarked samples.
The authors demonstrate the effectiveness of EaaW through extensive experiments on image classification and text generation tasks. They show that the embedded watermarks are robust to potential attacks aimed at removing or overwriting them. EaaW also avoids the introduction of harmful backdoor behaviors present in previous watermarking methods.
Critical Analysis
A key strength of the EaaW approach is that it addresses the fundamental limitations of existing backdoor-based watermarking schemes. By moving the watermark from the model's final predictions to its feature attribution explanations, EaaW avoids the introduction of harmful misclassification behaviors and the ambiguity issues inherent to single-bit prediction-based watermarks.
However, the authors acknowledge that EaaW does have some practical limitations. Firstly, it requires access to the model's internal feature attribution, which may not always be available, especially for black-box commercial models. Additionally, the watermark embedding process can be computationally intensive, as it involves optimizing the feature attribution of specific trigger samples.
Another potential concern is the broader question of the reliability and security of watermarking approaches in general. As AI systems become more advanced, there may be increasingly sophisticated attacks or exploits that could compromise even the EaaW approach. The authors encourage further research into these potential vulnerabilities.
Ultimately, while EaaW represents a promising advance in model watermarking, it is likely just one step in an ongoing arms race between model creators and those seeking to misappropriate their intellectual property. Continued innovation and critical analysis of these techniques will be essential as AI systems become more ubiquitous and valuable.
Conclusion
This paper introduces a new model watermarking approach called "Explanation as a Watermark" (EaaW) that embeds a multi-bit watermark into the feature attribution explanations of a model, rather than its final predictions. EaaW aims to address the key limitations of existing backdoor-based watermarking methods, namely their introduction of harmful behaviors and ambiguity in ownership claims.
Through technical details and experimental validation, the authors demonstrate that EaaW can effectively verify model ownership while avoiding the drawbacks of prior techniques. However, the approach also has practical limitations, and the broader security of AI watermarking remains an open challenge that will require ongoing research and innovation.
As AI models become increasingly valuable and ubiquitous, robust mechanisms to protect intellectual property will only grow in importance. EaaW represents a promising step forward, but the quest for reliable and secure watermarking is sure to continue.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
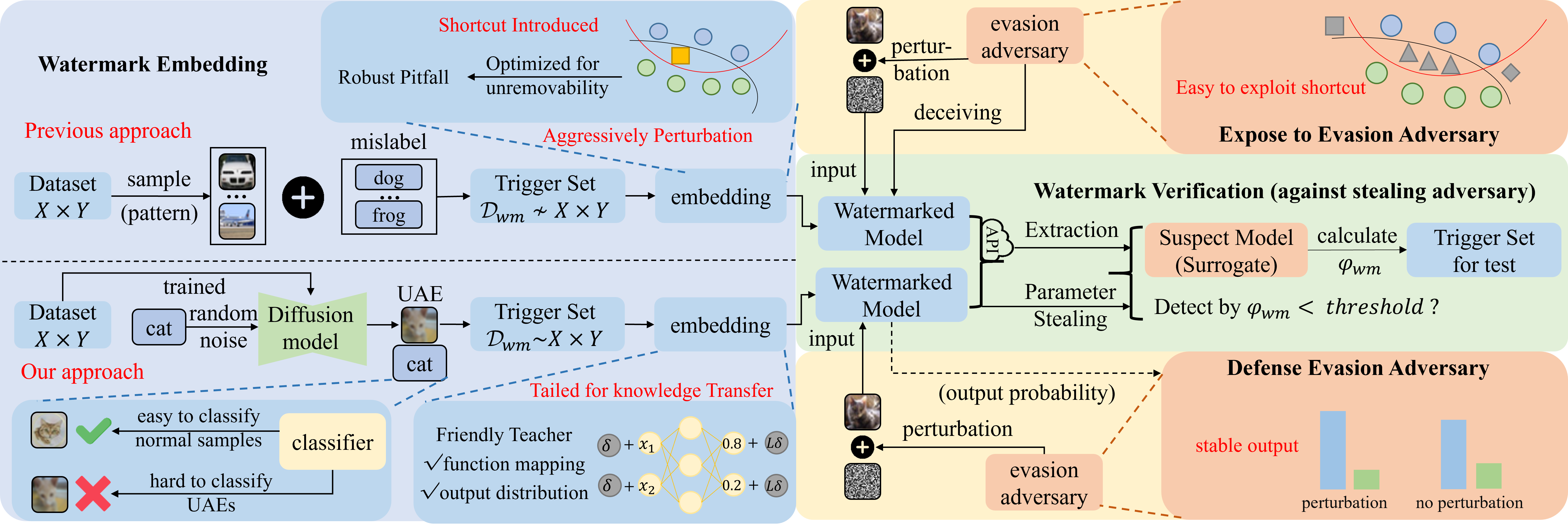
Reliable Model Watermarking: Defending Against Theft without Compromising on Evasion
Hongyu Zhu, Sichu Liang, Wentao Hu, Fangqi Li, Ju Jia, Shilin Wang
0
0
With the rise of Machine Learning as a Service (MLaaS) platforms,safeguarding the intellectual property of deep learning models is becoming paramount. Among various protective measures, trigger set watermarking has emerged as a flexible and effective strategy for preventing unauthorized model distribution. However, this paper identifies an inherent flaw in the current paradigm of trigger set watermarking: evasion adversaries can readily exploit the shortcuts created by models memorizing watermark samples that deviate from the main task distribution, significantly impairing their generalization in adversarial settings. To counteract this, we leverage diffusion models to synthesize unrestricted adversarial examples as trigger sets. By learning the model to accurately recognize them, unique watermark behaviors are promoted through knowledge injection rather than error memorization, thus avoiding exploitable shortcuts. Furthermore, we uncover that the resistance of current trigger set watermarking against removal attacks primarily relies on significantly damaging the decision boundaries during embedding, intertwining unremovability with adverse impacts. By optimizing the knowledge transfer properties of protected models, our approach conveys watermark behaviors to extraction surrogates without aggressively decision boundary perturbation. Experimental results on CIFAR-10/100 and Imagenette datasets demonstrate the effectiveness of our method, showing not only improved robustness against evasion adversaries but also superior resistance to watermark removal attacks compared to state-of-the-art solutions.
4/23/2024

Watermark-based Detection and Attribution of AI-Generated Content
Zhengyuan Jiang, Moyang Guo, Yuepeng Hu, Neil Zhenqiang Gong
0
0
Several companies--such as Google, Microsoft, and OpenAI--have deployed techniques to watermark AI-generated content to enable proactive detection. However, existing literature mainly focuses on user-agnostic detection. Attribution aims to further trace back the user of a generative-AI service who generated a given content detected as AI-generated. Despite its growing importance, attribution is largely unexplored. In this work, we aim to bridge this gap by providing the first systematic study on watermark-based, user-aware detection and attribution of AI-generated content. Specifically, we theoretically study the detection and attribution performance via rigorous probabilistic analysis. Moreover, we develop an efficient algorithm to select watermarks for the users to enhance attribution performance. Both our theoretical and empirical results show that watermark-based detection and attribution inherit the accuracy and (non-)robustness properties of the watermarking method.
4/8/2024
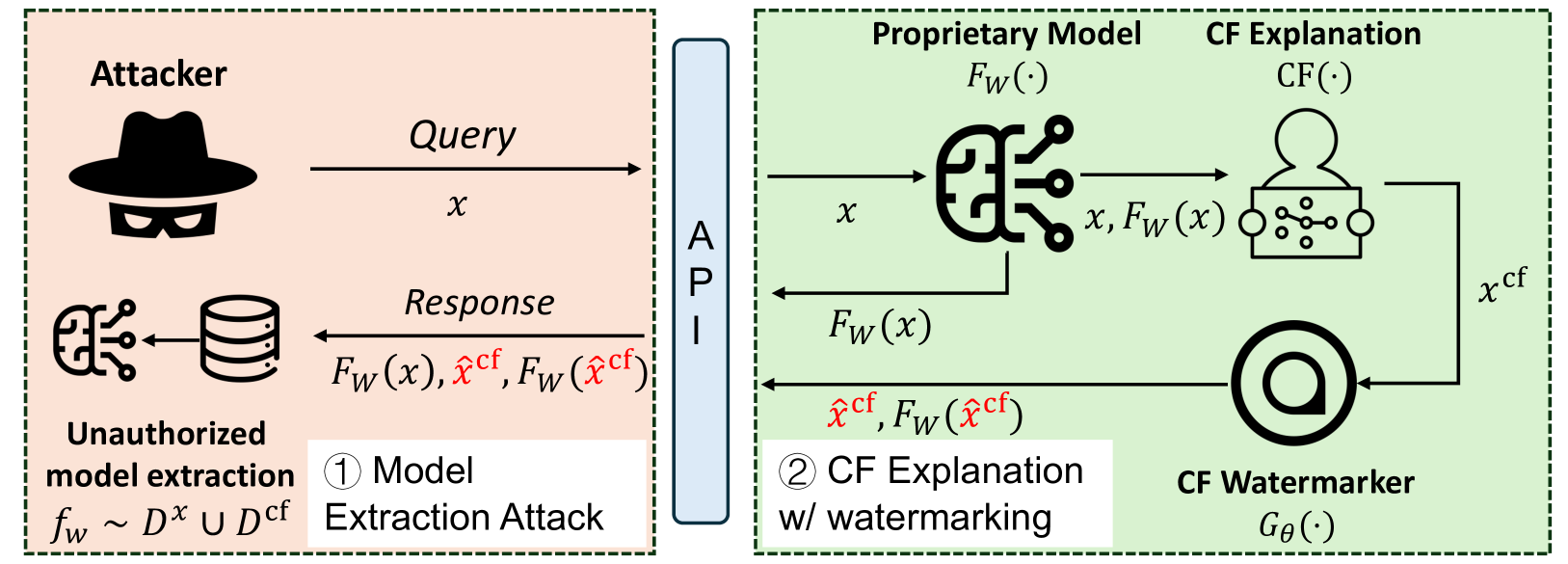
Watermarking Counterfactual Explanations
Hangzhi Guo, Amulya Yadav
0
0
The field of Explainable Artificial Intelligence (XAI) focuses on techniques for providing explanations to end-users about the decision-making processes that underlie modern-day machine learning (ML) models. Within the vast universe of XAI techniques, counterfactual (CF) explanations are often preferred by end-users as they help explain the predictions of ML models by providing an easy-to-understand & actionable recourse (or contrastive) case to individual end-users who are adversely impacted by predicted outcomes. However, recent studies have shown significant security concerns with using CF explanations in real-world applications; in particular, malicious adversaries can exploit CF explanations to perform query-efficient model extraction attacks on proprietary ML models. In this paper, we propose a model-agnostic watermarking framework (for adding watermarks to CF explanations) that can be leveraged to detect unauthorized model extraction attacks (which rely on the watermarked CF explanations). Our novel framework solves a bi-level optimization problem to embed an indistinguishable watermark into the generated CF explanation such that any future model extraction attacks that rely on these watermarked CF explanations can be detected using a null hypothesis significance testing (NHST) scheme, while ensuring that these embedded watermarks do not compromise the quality of the generated CF explanations. We evaluate this framework's performance across a diverse set of real-world datasets, CF explanation methods, and model extraction techniques, and show that our watermarking detection system can be used to accurately identify extracted ML models that are trained using the watermarked CF explanations. Our work paves the way for the secure adoption of CF explanations in real-world applications.
5/30/2024
📈
Learnable Linguistic Watermarks for Tracing Model Extraction Attacks on Large Language Models
Minhao Bai, Kaiyi Pang, Yongfeng Huang
0
0
In the rapidly evolving domain of artificial intelligence, safeguarding the intellectual property of Large Language Models (LLMs) is increasingly crucial. Current watermarking techniques against model extraction attacks, which rely on signal insertion in model logits or post-processing of generated text, remain largely heuristic. We propose a novel method for embedding learnable linguistic watermarks in LLMs, aimed at tracing and preventing model extraction attacks. Our approach subtly modifies the LLM's output distribution by introducing controlled noise into token frequency distributions, embedding an statistically identifiable controllable watermark.We leverage statistical hypothesis testing and information theory, particularly focusing on Kullback-Leibler Divergence, to differentiate between original and modified distributions effectively. Our watermarking method strikes a delicate well balance between robustness and output quality, maintaining low false positive/negative rates and preserving the LLM's original performance.
5/3/2024