Exploiting Consistency-Preserving Loss and Perceptual Contrast Stretching to Boost SSL-based Speech Enhancement

0

Sign in to get full access
Overview
- This paper explores a novel approach to boosting speech enhancement performance using self-supervised learning (SSL) techniques.
- The key innovations are a consistency-preserving loss function and a perceptual contrast stretching method, which help the SSL-based model learn more effective representations for speech enhancement.
- The proposed methods are evaluated on a range of speech enhancement benchmarks, demonstrating improved performance compared to previous SSL-based approaches.
Plain English Explanation
The paper focuses on improving the performance of speech enhancement models, which are used to improve the quality of noisy or distorted speech recordings. The researchers leverage a technique called self-supervised learning (SSL), which allows models to learn useful representations of speech data without requiring manually labeled training data.
The main contributions of this work are:
-
Consistency-Preserving Loss: The researchers introduce a new loss function that encourages the SSL model to produce consistent output even when the input speech is slightly perturbed. This helps the model learn more robust and stable representations of clean speech.
-
Perceptual Contrast Stretching: To further boost the model's ability to distinguish clean speech from noise, the researchers apply a perceptual contrast stretching technique. This essentially exaggerates the differences between the clean speech and background noise, making it easier for the model to identify and enhance the speech.
By incorporating these two novel techniques, the researchers were able to demonstrate improved speech enhancement performance compared to previous SSL-based approaches. This is an important advancement, as SSL-based methods hold promise for improving speech enhancement in low-resource settings where labeled training data is scarce.
Technical Explanation
The paper proposes two key innovations to boost the performance of SSL-based speech enhancement models:
-
Consistency-Preserving Loss: The researchers introduce a new loss function that encourages the SSL model to produce consistent output even when the input speech is slightly perturbed. This is achieved by adding a consistency loss term to the standard SSL objective, which penalizes large differences in the model's predictions for the original and perturbed inputs. This helps the model learn more robust and stable representations of clean speech.
-
Perceptual Contrast Stretching: To further improve the model's ability to distinguish clean speech from background noise, the researchers apply a perceptual contrast stretching technique. This process exaggerates the perceptual differences between the clean speech and noise components in the input, making it easier for the model to identify and enhance the speech. The contrast stretching is performed in the spectrogram domain, which captures the human auditory perception.
The researchers evaluate the proposed techniques on a range of speech enhancement benchmarks, including the DNS Challenge, VoiceBank-DEMAND, and VCTK datasets. The results demonstrate that the combination of consistency-preserving loss and perceptual contrast stretching consistently outperforms previous SSL-based speech enhancement approaches, as well as some traditional supervised methods.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed techniques, using a range of benchmark datasets and comparing against multiple baselines. The authors acknowledge several limitations and areas for future research, such as the potential for the consistency-preserving loss to overly constrain the model's learning, and the need to explore more advanced contrast stretching methods.
One potential concern is the computational overhead introduced by the perceptual contrast stretching, which may limit the real-time applicability of the approach. Additionally, the paper does not provide a detailed analysis of the learned representations or the specific speech enhancement mechanisms, which could help understand the strengths and weaknesses of the approach.
Overall, the paper makes a valuable contribution to the field of SSL-based speech enhancement, demonstrating the potential benefits of incorporating consistency-preserving losses and perceptual contrast stretching. The proposed techniques could be further explored and refined to address the identified limitations and unlock even greater performance improvements.
Conclusion
This paper presents a novel approach to boosting the performance of SSL-based speech enhancement models. The key innovations are a consistency-preserving loss function and a perceptual contrast stretching method, which help the model learn more effective representations for distinguishing and enhancing clean speech from background noise.
The empirical results show that the proposed techniques consistently outperform previous SSL-based approaches and some traditional supervised methods on a range of speech enhancement benchmarks. This work represents an important step forward in leveraging self-supervised learning to improve speech enhancement, particularly in low-resource settings where labeled training data is scarce.
The critical analysis highlights some potential limitations and areas for further research, such as the computational overhead of the contrast stretching and the need for a deeper understanding of the learned representations. Addressing these challenges could lead to even more powerful and efficient SSL-based speech enhancement solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Exploiting Consistency-Preserving Loss and Perceptual Contrast Stretching to Boost SSL-based Speech Enhancement
Muhammad Salman Khan, Moreno La Quatra, Kuo-Hsuan Hung, Szu-Wei Fu, Sabato Marco Siniscalchi, Yu Tsao
Self-supervised representation learning (SSL) has attained SOTA results on several downstream speech tasks, but SSL-based speech enhancement (SE) solutions still lag behind. To address this issue, we exploit three main ideas: (i) Transformer-based masking generation, (ii) consistency-preserving loss, and (iii) perceptual contrast stretching (PCS). In detail, conformer layers, leveraging an attention mechanism, are introduced to effectively model frame-level representations and obtain the Ideal Ratio Mask (IRM) for SE. Moreover, we incorporate consistency in the loss function, which processes the input to account for the inconsistency effects of signal reconstruction from the spectrogram. Finally, PCS is employed to improve the contrast of input and target features according to perceptual importance. Evaluated on the VoiceBank-DEMAND task, the proposed solution outperforms previously SSL-based SE solutions when tested on several objective metrics, attaining a SOTA PESQ score of 3.54.
Read more8/12/2024

0
Exploring Self-Supervised Multi-view Contrastive Learning for Speech Emotion Recognition with Limited Annotations
Bulat Khaertdinov, Pedro Jeuris, Annanda Sousa, Enrique Hortal
Recent advancements in Deep and Self-Supervised Learning (SSL) have led to substantial improvements in Speech Emotion Recognition (SER) performance, reaching unprecedented levels. However, obtaining sufficient amounts of accurately labeled data for training or fine-tuning the models remains a costly and challenging task. In this paper, we propose a multi-view SSL pre-training technique that can be applied to various representations of speech, including the ones generated by large speech models, to improve SER performance in scenarios where annotations are limited. Our experiments, based on wav2vec 2.0, spectral and paralinguistic features, demonstrate that the proposed framework boosts the SER performance, by up to 10% in Unweighted Average Recall, in settings with extremely sparse data annotations.
Read more6/13/2024

0
Progressive Residual Extraction based Pre-training for Speech Representation Learning
Tianrui Wang, Jin Li, Ziyang Ma, Rui Cao, Xie Chen, Longbiao Wang, Meng Ge, Xiaobao Wang, Yuguang Wang, Jianwu Dang, Nyima Tashi
Self-supervised learning (SSL) has garnered significant attention in speech processing, excelling in linguistic tasks such as speech recognition. However, jointly improving the performance of pre-trained models on various downstream tasks, each requiring different speech information, poses significant challenges. To this purpose, we propose a progressive residual extraction based self-supervised learning method, named ProgRE. Specifically, we introduce two lightweight and specialized task modules into an encoder-style SSL backbone to enhance its ability to extract pitch variation and speaker information from speech. Furthermore, to prevent the interference of reinforced pitch variation and speaker information with irrelevant content information learning, we residually remove the information extracted by these two modules from the main branch. The main branch is then trained using HuBERT's speech masking prediction to ensure the performance of the Transformer's deep-layer features on content tasks. In this way, we can progressively extract pitch variation, speaker, and content representations from the input speech. Finally, we can combine multiple representations with diverse speech information using different layer weights to obtain task-specific representations for various downstream tasks. Experimental results indicate that our proposed method achieves joint performance improvements on various tasks, such as speaker identification, speech recognition, emotion recognition, speech enhancement, and voice conversion, compared to excellent SSL methods such as wav2vec2.0, HuBERT, and WavLM.
Read more9/4/2024
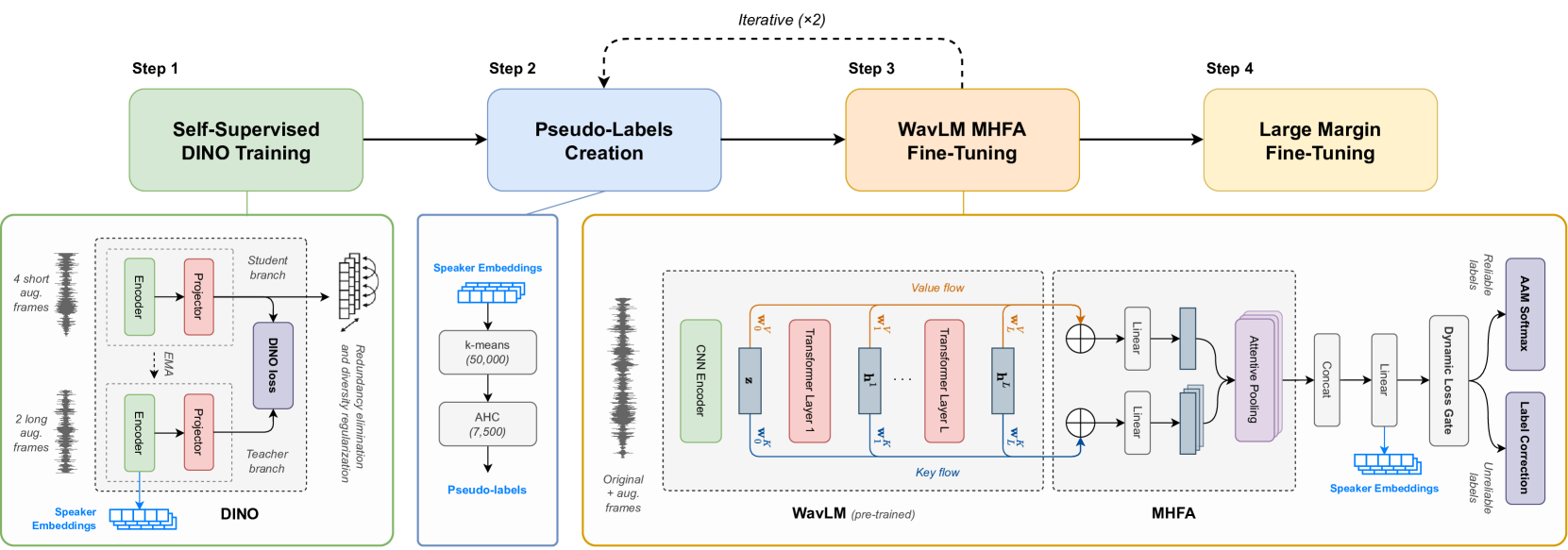
0
Towards Supervised Performance on Speaker Verification with Self-Supervised Learning by Leveraging Large-Scale ASR Models
Victor Miara, Theo Lepage, Reda Dehak
Recent advancements in Self-Supervised Learning (SSL) have shown promising results in Speaker Verification (SV). However, narrowing the performance gap with supervised systems remains an ongoing challenge. Several studies have observed that speech representations from large-scale ASR models contain valuable speaker information. This work explores the limitations of fine-tuning these models for SV using an SSL contrastive objective in an end-to-end approach. Then, we propose a framework to learn speaker representations in an SSL context by fine-tuning a pre-trained WavLM with a supervised loss using pseudo-labels. Initial pseudo-labels are derived from an SSL DINO-based model and are iteratively refined by clustering the model embeddings. Our method achieves 0.99% EER on VoxCeleb1-O, establishing the new state-of-the-art on self-supervised SV. As this performance is close to our supervised baseline of 0.94% EER, this contribution is a step towards supervised performance on SV with SSL.
Read more6/5/2024