Explore-Go: Leveraging Exploration for Generalisation in Deep Reinforcement Learning
2406.08069
0
0
Abstract
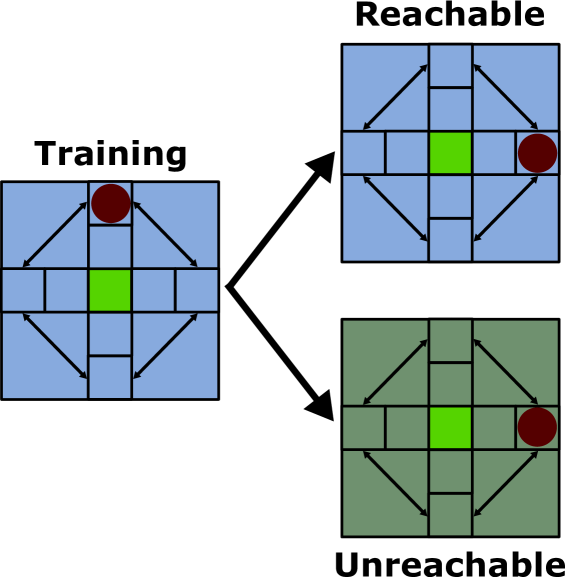
One of the remaining challenges in reinforcement learning is to develop agents that can generalise to novel scenarios they might encounter once deployed. This challenge is often framed in a multi-task setting where agents train on a fixed set of tasks and have to generalise to new tasks. Recent work has shown that in this setting increased exploration during training can be leveraged to increase the generalisation performance of the agent. This makes sense when the states encountered during testing can actually be explored during training. In this paper, we provide intuition why exploration can also benefit generalisation to states that cannot be explicitly encountered during training. Additionally, we propose a novel method Explore-Go that exploits this intuition by increasing the number of states on which the agent trains. Explore-Go effectively increases the starting state distribution of the agent and as a result can be used in conjunction with most existing on-policy or off-policy reinforcement learning algorithms. We show empirically that our method can increase generalisation performance in an illustrative environment and on the Procgen benchmark.
Create account to get full access
Overview
- This paper introduces a new approach called "Explore-Go" that aims to improve the ability of deep reinforcement learning agents to generalize their learned skills to new environments.
- The key idea is to leverage exploration, a fundamental aspect of reinforcement learning, to help agents better understand the structure of their environment and acquire more versatile and transferable skills.
- The authors demonstrate the effectiveness of Explore-Go on several challenging benchmark tasks, showing that it outperforms standard reinforcement learning methods in terms of generalization performance.
Plain English Explanation
The paper presents a new technique called "Explore-Go" that can help AI agents, like those used in video games or robotics, become better at adapting their skills to new situations. In reinforcement learning, agents learn by interacting with their environment and receiving rewards or penalties for their actions. However, this can sometimes lead to agents becoming specialized in the specific environment they were trained on, making it difficult for them to apply their knowledge to new scenarios.
The Explore-Go approach tries to address this by encouraging the agents to explore their environment more during the learning process. By exploring more, the agents can gain a better understanding of the underlying structure of the environment and acquire more versatile and transferable skills. This can help them perform better when faced with new situations that differ from the ones they were trained on.
The authors demonstrate the effectiveness of Explore-Go by testing it on several challenging benchmark tasks, such as video game environments or simulated robot control problems. The results show that Explore-Go outperforms standard reinforcement learning methods in terms of the agents' ability to generalize their skills to new scenarios.
Technical Explanation
The core idea of the Explore-Go approach is to leverage exploration, a fundamental aspect of reinforcement learning, to help agents acquire more generalizable skills. The authors propose a simple yet effective technique that encourages agents to explore their environment more during the learning process.
Specifically, the Explore-Go method introduces a novel exploration bonus that rewards the agent for visiting states that are different from the ones it has encountered before. This exploration bonus is combined with the standard reward signal from the environment, providing the agent with an incentive to explore and discover new aspects of the task.
The authors evaluate the Explore-Go approach on a range of benchmark tasks, including various video game environments and simulated robotic control problems. The results demonstrate that Explore-Go significantly outperforms standard reinforcement learning algorithms in terms of the agents' ability to generalize their skills to new, unseen scenarios.
Critical Analysis
The Explore-Go approach presents a promising direction for improving the generalization capabilities of deep reinforcement learning agents. By encouraging agents to explore their environment more during training, the method helps them acquire a more comprehensive understanding of the task structure, which can then be leveraged to perform better in novel situations.
However, the paper does not address several potential limitations of the approach. For example, the authors do not discuss how the exploration bonus might be tuned or scaled to balance the exploration-exploitation trade-off in different types of environments. Additionally, the paper does not explore how Explore-Go might perform in more complex, multi-agent scenarios or in the presence of partial observability.
Further research is needed to understand the broader applicability of the Explore-Go method and its potential limitations. Exploring these aspects could help refine the approach and make it more robust and versatile for a wider range of reinforcement learning problems.
Conclusion
The Explore-Go method presented in this paper offers a promising approach for improving the generalization capabilities of deep reinforcement learning agents. By encouraging agents to explore their environment more during the learning process, the technique helps them acquire more versatile and transferable skills, which can then be applied to novel scenarios.
The results demonstrate the effectiveness of Explore-Go on several challenging benchmark tasks, suggesting that it could have significant implications for the development of more robust and adaptable AI systems. While the paper does not address all potential limitations of the approach, it represents an important step forward in the field of reinforcement learning and highlights the value of leveraging exploration for better generalization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
An approach to improve agent learning via guaranteeing goal reaching in all episodes
Pavel Osinenko, Grigory Yaremenko, Georgiy Malaniya, Anton Bolychev
0
0
Reinforcement learning is commonly concerned with problems of maximizing accumulated rewards in Markov decision processes. Oftentimes, a certain goal state or a subset of the state space attain maximal reward. In such a case, the environment may be considered solved when the goal is reached. Whereas numerous techniques, learning or non-learning based, exist for solving environments, doing so optimally is the biggest challenge. Say, one may choose a reward rate which penalizes the action effort. Reinforcement learning is currently among the most actively developed frameworks for solving environments optimally by virtue of maximizing accumulated reward, in other words, returns. Yet, tuning agents is a notoriously hard task as reported in a series of works. Our aim here is to help the agent learn a near-optimal policy efficiently while ensuring a goal reaching property of some basis policy that merely solves the environment. We suggest an algorithm, which is fairly flexible, and can be used to augment practically any agent as long as it comprises of a critic. A formal proof of a goal reaching property is provided. Simulation experiments on six problems under five agents, including the benchmarked one, provided an empirical evidence that the learning can indeed be boosted while ensuring goal reaching property.
5/30/2024
Transform then Explore: a Simple and Effective Technique for Exploratory Combinatorial Optimization with Reinforcement Learning
Tianle Pu, Changjun Fan, Mutian Shen, Yizhou Lu, Li Zeng, Zohar Nussinov, Chao Chen, Zhong Liu
0
0
Many complex problems encountered in both production and daily life can be conceptualized as combinatorial optimization problems (COPs) over graphs. Recent years, reinforcement learning (RL) based models have emerged as a promising direction, which treat the COPs solving as a heuristic learning problem. However, current finite-horizon-MDP based RL models have inherent limitations. They are not allowed to explore adquately for improving solutions at test time, which may be necessary given the complexity of NP-hard optimization tasks. Some recent attempts solve this issue by focusing on reward design and state feature engineering, which are tedious and ad-hoc. In this work, we instead propose a much simpler but more effective technique, named gauge transformation (GT). The technique is originated from physics, but is very effective in enabling RL agents to explore to continuously improve the solutions during test. Morever, GT is very simple, which can be implemented with less than 10 lines of Python codes, and can be applied to a vast majority of RL models. Experimentally, we show that traditional RL models with GT technique produce the state-of-the-art performances on the MaxCut problem. Furthermore, since GT is independent of any RL models, it can be seamlessly integrated into various RL frameworks, paving the way of these models for more effective explorations in the solving of general COPs.
4/9/2024
🤯
Emergence of Collective Open-Ended Exploration from Decentralized Meta-Reinforcement Learning
Richard Bornemann, Gautier Hamon, Eleni Nisioti, Cl'ement Moulin-Frier
0
0
Recent works have proven that intricate cooperative behaviors can emerge in agents trained using meta reinforcement learning on open ended task distributions using self-play. While the results are impressive, we argue that self-play and other centralized training techniques do not accurately reflect how general collective exploration strategies emerge in the natural world: through decentralized training and over an open-ended distribution of tasks. In this work we therefore investigate the emergence of collective exploration strategies, where several agents meta-learn independent recurrent policies on an open ended distribution of tasks. To this end we introduce a novel environment with an open ended procedurally generated task space which dynamically combines multiple subtasks sampled from five diverse task types to form a vast distribution of task trees. We show that decentralized agents trained in our environment exhibit strong generalization abilities when confronted with novel objects at test time. Additionally, despite never being forced to cooperate during training the agents learn collective exploration strategies which allow them to solve novel tasks never encountered during training. We further find that the agents learned collective exploration strategies extend to an open ended task setting, allowing them to solve task trees of twice the depth compared to the ones seen during training. Our open source code as well as videos of the agents can be found on our companion website.
5/8/2024
📊
Improving Generalization in Game Agents with Data Augmentation in Imitation Learning
Derek Yadgaroff, Alessandro Sestini, Konrad Tollmar, Ayca Ozcelikkale, Linus Gissl'en
0
0
Imitation learning is an effective approach for training game-playing agents and, consequently, for efficient game production. However, generalization - the ability to perform well in related but unseen scenarios - is an essential requirement that remains an unsolved challenge for game AI. Generalization is difficult for imitation learning agents because it requires the algorithm to take meaningful actions outside of the training distribution. In this paper we propose a solution to this challenge. Inspired by the success of data augmentation in supervised learning, we augment the training data so the distribution of states and actions in the dataset better represents the real state-action distribution. This study evaluates methods for combining and applying data augmentations to observations, to improve generalization of imitation learning agents. It also provides a performance benchmark of these augmentations across several 3D environments. These results demonstrate that data augmentation is a promising framework for improving generalization in imitation learning agents.
4/9/2024