Emergence of Collective Open-Ended Exploration from Decentralized Meta-Reinforcement Learning
2311.00651
0
0
🤯
Abstract
Recent works have proven that intricate cooperative behaviors can emerge in agents trained using meta reinforcement learning on open ended task distributions using self-play. While the results are impressive, we argue that self-play and other centralized training techniques do not accurately reflect how general collective exploration strategies emerge in the natural world: through decentralized training and over an open-ended distribution of tasks. In this work we therefore investigate the emergence of collective exploration strategies, where several agents meta-learn independent recurrent policies on an open ended distribution of tasks. To this end we introduce a novel environment with an open ended procedurally generated task space which dynamically combines multiple subtasks sampled from five diverse task types to form a vast distribution of task trees. We show that decentralized agents trained in our environment exhibit strong generalization abilities when confronted with novel objects at test time. Additionally, despite never being forced to cooperate during training the agents learn collective exploration strategies which allow them to solve novel tasks never encountered during training. We further find that the agents learned collective exploration strategies extend to an open ended task setting, allowing them to solve task trees of twice the depth compared to the ones seen during training. Our open source code as well as videos of the agents can be found on our companion website.
Create account to get full access
Overview
- Researchers demonstrate that complex cooperative behaviors can emerge in agents trained using meta-reinforcement learning on open-ended task distributions through self-play.
- However, the authors argue that self-play and other centralized training techniques do not accurately reflect how collective exploration strategies develop in the natural world, which is through decentralized training over an open-ended range of tasks.
- This work investigates the emergence of collective exploration strategies where multiple independent agents meta-learn recurrent policies on an open-ended task distribution.
Plain English Explanation
The paper shows that agents trained using meta-reinforcement learning on a wide variety of tasks can develop complex cooperative behaviors by playing against each other (self-play). However, the researchers believe this doesn't reflect how cooperation naturally arises, which is through independent agents learning on their own over many different tasks.
So in this study, they create a new environment with an endless variety of tasks that the agents have to learn to solve. The agents are trained independently, without being forced to work together. Despite this, the agents end up developing strategies to explore and solve these tasks collectively, even when faced with completely new challenges they haven't seen before.
The key finding is that these decentralized, independently-trained agents can learn powerful collaborative exploration strategies that allow them to tackle increasingly complex tasks, going beyond what they were exposed to during training. This suggests that real-world cooperation may emerge more naturally through independent learning rather than top-down coordination.
Technical Explanation
The paper introduces a novel environment with a procedurally generated, open-ended task space that dynamically combines multiple subtasks from five diverse categories. This creates a vast distribution of "task trees" that the agents must learn to solve.
The researchers train multiple independent agents, each with their own recurrent neural network policy, on this open-ended task distribution using meta-reinforcement learning. Crucially, the agents are not explicitly trained to cooperate - they learn collective exploration strategies on their own through the decentralized training process.
The results show that these independently-trained agents develop strong generalization capabilities, allowing them to solve novel tasks involving previously unseen objects. Furthermore, the agents exhibit emergent cooperative behaviors that enable them to tackle task trees of significantly greater complexity than those encountered during training.
Critical Analysis
While the findings are impressive, the paper does not fully address how the learned cooperative strategies would scale to even larger and more complex task distributions. The open-ended nature of the environment is a strength, but it also raises questions about the limits of this approach and how it would translate to real-world scenarios with an effectively infinite number of possible tasks.
Additionally, the paper does not explore potential downsides or unintended consequences of these self-organizing cooperative behaviors. For example, how might such strategies be exploited or misused, and what safeguards would be needed to ensure the agents' behaviors remain aligned with intended objectives?
Further research is needed to better understand the generalization capabilities of these decentralized, meta-learning agents, as well as to investigate the broader implications of this approach for artificial intelligence and multi-agent systems.
Conclusion
This paper presents a novel approach to multi-agent learning that allows for the emergence of complex cooperative behaviors through decentralized training on an open-ended task distribution. By eschewing centralized coordination in favor of independent agent learning, the researchers demonstrate that powerful collaborative exploration strategies can arise organically.
The findings challenge traditional assumptions about the necessity of top-down control or explicit cooperation mechanisms in multi-agent systems. Instead, they suggest that fostering independent learning and self-organization may be a more natural path to developing robust and flexible collective intelligence. This has important implications for the design of future AI systems, where the ability to adapt and cooperate in unpredictable environments will be increasingly crucial.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
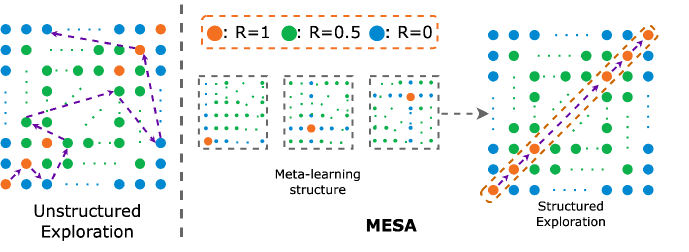
MESA: Cooperative Meta-Exploration in Multi-Agent Learning through Exploiting State-Action Space Structure
Zhicheng Zhang, Yancheng Liang, Yi Wu, Fei Fang
0
0
Multi-agent reinforcement learning (MARL) algorithms often struggle to find strategies close to Pareto optimal Nash Equilibrium, owing largely to the lack of efficient exploration. The problem is exacerbated in sparse-reward settings, caused by the larger variance exhibited in policy learning. This paper introduces MESA, a novel meta-exploration method for cooperative multi-agent learning. It learns to explore by first identifying the agents' high-rewarding joint state-action subspace from training tasks and then learning a set of diverse exploration policies to cover the subspace. These trained exploration policies can be integrated with any off-policy MARL algorithm for test-time tasks. We first showcase MESA's advantage in a multi-step matrix game. Furthermore, experiments show that with learned exploration policies, MESA achieves significantly better performance in sparse-reward tasks in several multi-agent particle environments and multi-agent MuJoCo environments, and exhibits the ability to generalize to more challenging tasks at test time.
5/3/2024
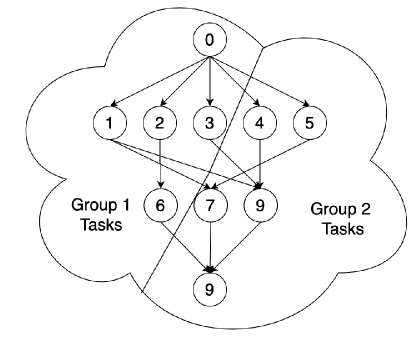
Cooperative Task Execution in Multi-Agent Systems
Karishma, Shrisha Rao
0
0
We propose a multi-agent system that enables groups of agents to collaborate and work autonomously to execute tasks. Groups can work in a decentralized manner and can adapt to dynamic changes in the environment. Groups of agents solve assigned tasks by exploring the solution space cooperatively based on the highest reward first. The tasks have a dependency structure associated with them. We rigorously evaluated the performance of the system and the individual group performance using centralized and decentralized control approaches for task distribution. Based on the results, the centralized approach is more efficient for systems with a less-dependent system $G_{18}$ (a well-known program graph that contains $18$ nodes with few links), while the decentralized approach performs better for systems with a highly-dependent system $G_{40}$ (a program graph that contains $40$ highly interlinked nodes). We also evaluated task allocation to groups that do not have interdependence. Our findings reveal that there was significantly less difference in the number of tasks allocated to each group in a less-dependent system than in a highly-dependent one. The experimental results showed that a large number of small-size cooperative groups of agents unequivocally improved the system's performance compared to a small number of large-size cooperative groups of agents. Therefore, it is essential to identify the optimal group size for a system to enhance its performance.
5/21/2024
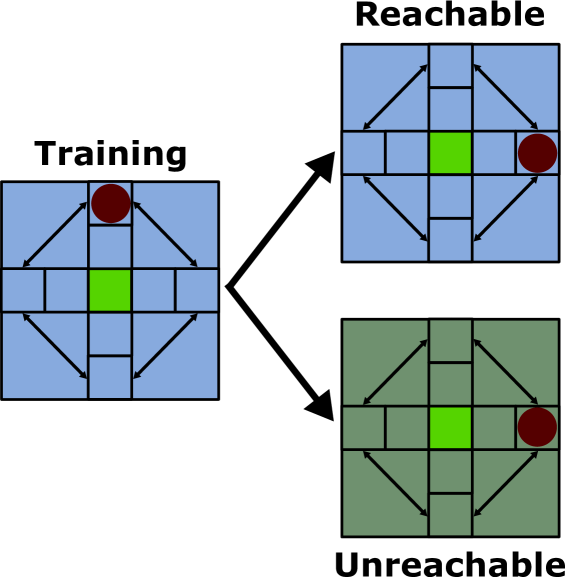
Explore-Go: Leveraging Exploration for Generalisation in Deep Reinforcement Learning
Max Weltevrede, Felix Kaubek, Matthijs T. J. Spaan, Wendelin Bohmer
0
0
One of the remaining challenges in reinforcement learning is to develop agents that can generalise to novel scenarios they might encounter once deployed. This challenge is often framed in a multi-task setting where agents train on a fixed set of tasks and have to generalise to new tasks. Recent work has shown that in this setting increased exploration during training can be leveraged to increase the generalisation performance of the agent. This makes sense when the states encountered during testing can actually be explored during training. In this paper, we provide intuition why exploration can also benefit generalisation to states that cannot be explicitly encountered during training. Additionally, we propose a novel method Explore-Go that exploits this intuition by increasing the number of states on which the agent trains. Explore-Go effectively increases the starting state distribution of the agent and as a result can be used in conjunction with most existing on-policy or off-policy reinforcement learning algorithms. We show empirically that our method can increase generalisation performance in an illustrative environment and on the Procgen benchmark.
6/13/2024
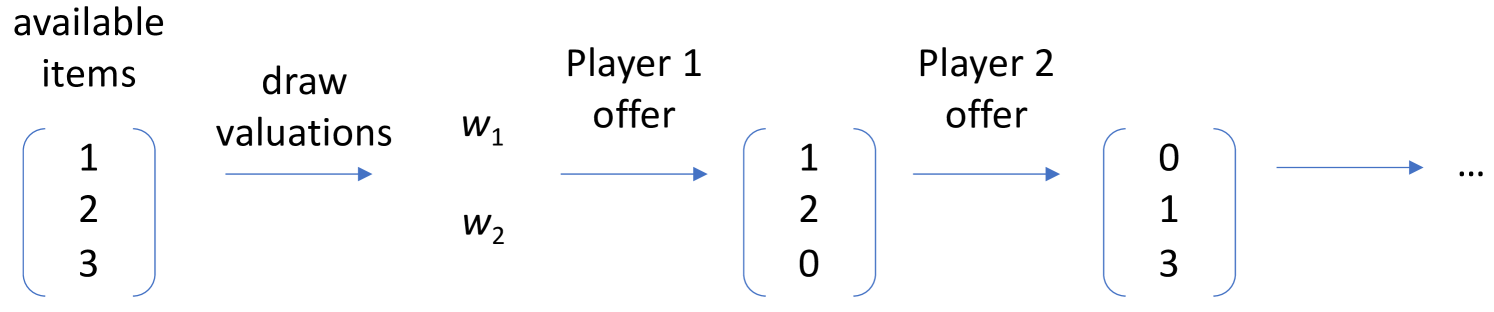
A Meta-Game Evaluation Framework for Deep Multiagent Reinforcement Learning
Zun Li, Michael P. Wellman
0
0
Evaluating deep multiagent reinforcement learning (MARL) algorithms is complicated by stochasticity in training and sensitivity of agent performance to the behavior of other agents. We propose a meta-game evaluation framework for deep MARL, by framing each MARL algorithm as a meta-strategy, and repeatedly sampling normal-form empirical games over combinations of meta-strategies resulting from different random seeds. Each empirical game captures both self-play and cross-play factors across seeds. These empirical games provide the basis for constructing a sampling distribution, using bootstrapping, over a variety of game analysis statistics. We use this approach to evaluate state-of-the-art deep MARL algorithms on a class of negotiation games. From statistics on individual payoffs, social welfare, and empirical best-response graphs, we uncover strategic relationships among self-play, population-based, model-free, and model-based MARL methods.We also investigate the effect of run-time search as a meta-strategy operator, and find via meta-game analysis that the search version of a meta-strategy generally leads to improved performance.
5/2/2024