Transform then Explore: a Simple and Effective Technique for Exploratory Combinatorial Optimization with Reinforcement Learning
2404.04661
0
0
Abstract
Many complex problems encountered in both production and daily life can be conceptualized as combinatorial optimization problems (COPs) over graphs. Recent years, reinforcement learning (RL) based models have emerged as a promising direction, which treat the COPs solving as a heuristic learning problem. However, current finite-horizon-MDP based RL models have inherent limitations. They are not allowed to explore adquately for improving solutions at test time, which may be necessary given the complexity of NP-hard optimization tasks. Some recent attempts solve this issue by focusing on reward design and state feature engineering, which are tedious and ad-hoc. In this work, we instead propose a much simpler but more effective technique, named gauge transformation (GT). The technique is originated from physics, but is very effective in enabling RL agents to explore to continuously improve the solutions during test. Morever, GT is very simple, which can be implemented with less than 10 lines of Python codes, and can be applied to a vast majority of RL models. Experimentally, we show that traditional RL models with GT technique produce the state-of-the-art performances on the MaxCut problem. Furthermore, since GT is independent of any RL models, it can be seamlessly integrated into various RL frameworks, paving the way of these models for more effective explorations in the solving of general COPs.
Create account to get full access
Overview
- This paper presents a new technique called "Transform then Explore" for solving combinatorial optimization problems using reinforcement learning.
- The approach involves first transforming the original problem into a simpler, more tractable form, and then using reinforcement learning to explore and find solutions to the transformed problem.
- The authors claim this technique is simple, effective, and can outperform existing reinforcement learning approaches on a range of combinatorial optimization tasks.
Plain English Explanation
The paper introduces a new way to solve complex optimization problems using reinforcement learning. Optimization problems involve finding the best solution from a large set of possibilities, like planning the most efficient delivery route or scheduling tasks in a factory.
The key insight of this paper is to first transform the original problem into a simpler form that's easier to work with. Then, the researchers use reinforcement learning - a type of machine learning where an agent learns by interacting with an environment and getting feedback - to explore this transformed problem and find good solutions.
The authors show that this "Transform then Explore" approach outperforms previous reinforcement learning methods on a variety of optimization tasks. The simplicity of the transformation step coupled with the power of reinforcement learning to explore the problem space seems to be an effective combination.
This work could have implications for improving the performance of reinforcement learning on complex, real-world optimization problems, like improving IoT device intelligence or designing efficient hierarchical control systems.
Technical Explanation
The paper introduces a new reinforcement learning technique called "Transform then Explore" for solving combinatorial optimization problems. The core idea is to first transform the original, complex optimization problem into a simpler, more tractable form, and then use reinforcement learning to explore and find solutions to this transformed problem.
Specifically, the authors define a transformation function that maps the original problem instance to a simpler one, preserving key structural properties. They then use a reinforcement learning agent to explore the transformed problem space and identify high-performing solutions, which are then transformed back to the original problem domain.
The authors evaluate this "Transform then Explore" approach on a range of combinatorial optimization benchmarks, including the Traveling Salesman Problem, Job Shop Scheduling, and the Set Covering Problem. They show that this technique can outperform existing reinforcement learning methods, as well as traditional optimization algorithms, in terms of solution quality and computational efficiency.
The key advantages of this approach are its simplicity and generality. By decoupling the problem transformation and exploration phases, the authors are able to leverage the strengths of both classical optimization techniques and modern reinforcement learning methods. The transformation step can leverage domain-specific insights to make the problem more amenable to reinforcement learning, while the exploration phase can efficiently search the transformed problem space to find high-quality solutions.
Critical Analysis
One potential limitation of the "Transform then Explore" approach is the reliance on a well-designed transformation function. The authors acknowledge that the performance of this technique will depend on the quality of the transformation, and that finding an effective transformation may require domain expertise and problem-specific insights.
Additionally, the paper does not address how to automatically generate or learn the transformation function, which could limit the broader applicability of this technique. Developing methods to learn effective transformations in a more automated way could be an interesting direction for future research.
Another concern is the computational overhead of the transformation step, which could outweigh the benefits of the reinforcement learning exploration, particularly for small problem instances. The authors provide some analysis of the computational complexity, but more extensive empirical evaluation of the trade-offs between transformation cost and exploration efficiency would be valuable.
Finally, the paper focuses on a relatively narrow set of combinatorial optimization benchmarks. Examining the performance of "Transform then Explore" on a wider range of real-world optimization problems, including those with different problem structures and constraints, could provide a more comprehensive understanding of the technique's strengths and limitations.
Conclusion
The "Transform then Explore" technique presented in this paper offers a promising new approach for solving complex combinatorial optimization problems using reinforcement learning. By first transforming the original problem into a simpler form, the authors are able to leverage the strengths of both classical optimization methods and modern machine learning techniques.
The empirical results demonstrating the effectiveness of this approach on a range of benchmarks are encouraging, and the simplicity and generality of the technique suggest it could have broad applicability in areas like decision-making under partial observability and hierarchical control systems.
Further research to address the identified limitations, such as automated transformation generation and more extensive real-world evaluations, could help unlock the full potential of "Transform then Explore" and advance the state of the art in reinforcement learning-based combinatorial optimization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Enhancing Tabular Data Optimization with a Flexible Graph-based Reinforced Exploration Strategy
Xiaohan Huang, Dongjie Wang, Zhiyuan Ning, Ziyue Qiao, Qingqing Long, Haowei Zhu, Min Wu, Yuanchun Zhou, Meng Xiao
0
0
Tabular data optimization methods aim to automatically find an optimal feature transformation process that generates high-value features and improves the performance of downstream machine learning tasks. Current frameworks for automated feature transformation rely on iterative sequence generation tasks, optimizing decision strategies through performance feedback from downstream tasks. However, these approaches fail to effectively utilize historical decision-making experiences and overlook potential relationships among generated features, thus limiting the depth of knowledge extraction. Moreover, the granularity of the decision-making process lacks dynamic backtracking capabilities for individual features, leading to insufficient adaptability when encountering inefficient pathways, adversely affecting overall robustness and exploration efficiency. To address the limitations observed in current automatic feature engineering frameworks, we introduce a novel method that utilizes a feature-state transformation graph to effectively preserve the entire feature transformation journey, where each node represents a specific transformation state. During exploration, three cascading agents iteratively select nodes and idea mathematical operations to generate new transformation states. This strategy leverages the inherent properties of the graph structure, allowing for the preservation and reuse of valuable transformations. It also enables backtracking capabilities through graph pruning techniques, which can rectify inefficient transformation paths. To validate the efficacy and flexibility of our approach, we conducted comprehensive experiments and detailed case studies, demonstrating superior performance in diverse scenarios.
6/12/2024
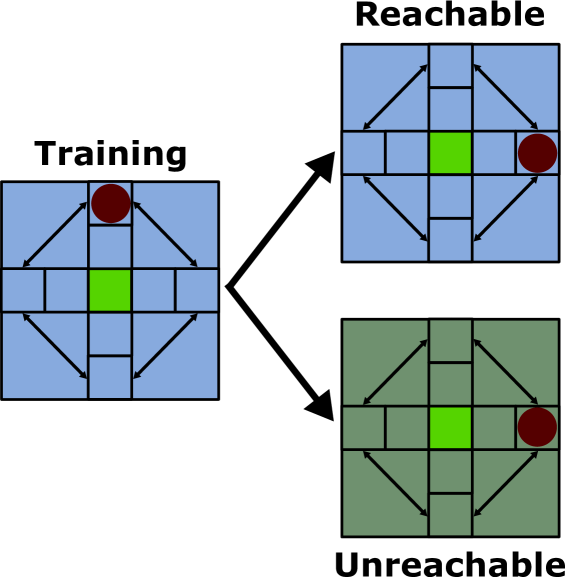
Explore-Go: Leveraging Exploration for Generalisation in Deep Reinforcement Learning
Max Weltevrede, Felix Kaubek, Matthijs T. J. Spaan, Wendelin Bohmer
0
0
One of the remaining challenges in reinforcement learning is to develop agents that can generalise to novel scenarios they might encounter once deployed. This challenge is often framed in a multi-task setting where agents train on a fixed set of tasks and have to generalise to new tasks. Recent work has shown that in this setting increased exploration during training can be leveraged to increase the generalisation performance of the agent. This makes sense when the states encountered during testing can actually be explored during training. In this paper, we provide intuition why exploration can also benefit generalisation to states that cannot be explicitly encountered during training. Additionally, we propose a novel method Explore-Go that exploits this intuition by increasing the number of states on which the agent trains. Explore-Go effectively increases the starting state distribution of the agent and as a result can be used in conjunction with most existing on-policy or off-policy reinforcement learning algorithms. We show empirically that our method can increase generalisation performance in an illustrative environment and on the Procgen benchmark.
6/13/2024

Graph Reinforcement Learning for Combinatorial Optimization: A Survey and Unifying Perspective
Victor-Alexandru Darvariu, Stephen Hailes, Mirco Musolesi
0
0
Graphs are a natural representation for systems based on relations between connected entities. Combinatorial optimization problems, which arise when considering an objective function related to a process of interest on discrete structures, are often challenging due to the rapid growth of the solution space. The trial-and-error paradigm of Reinforcement Learning has recently emerged as a promising alternative to traditional methods, such as exact algorithms and (meta)heuristics, for discovering better decision-making strategies in a variety of disciplines including chemistry, computer science, and statistics. Despite the fact that they arose in markedly different fields, these techniques share significant commonalities. Therefore, we set out to synthesize this work in a unifying perspective that we term Graph Reinforcement Learning, interpreting it as a constructive decision-making method for graph problems. After covering the relevant technical background, we review works along the dividing line of whether the goal is to optimize graph structure given a process of interest, or to optimize the outcome of the process itself under fixed graph structure. Finally, we discuss the common challenges facing the field and open research questions. In contrast with other surveys, the present work focuses on non-canonical graph problems for which performant algorithms are typically not known and Reinforcement Learning is able to provide efficient and effective solutions.
4/10/2024
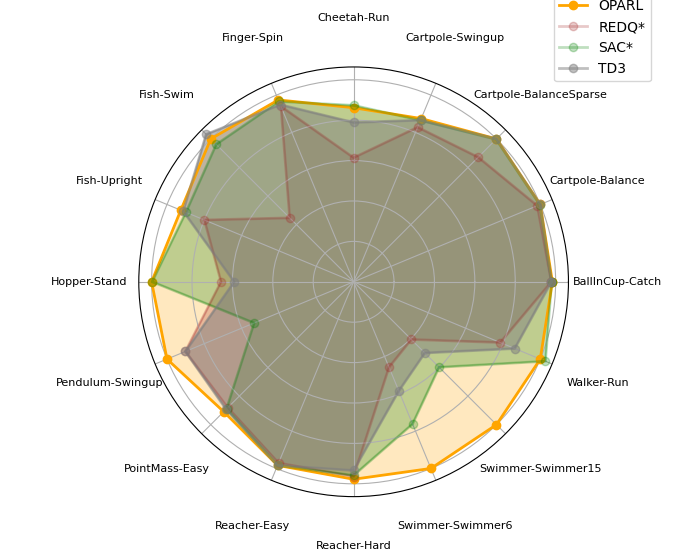
Efficient Reinforcement Learning via Decoupling Exploration and Utilization
Jingpu Yang, Helin Wang, Qirui Zhao, Zhecheng Shi, Zirui Song, Miao Fang
0
0
Reinforcement Learning (RL), recognized as an efficient learning approach, has achieved remarkable success across multiple fields and applications, including gaming, robotics, and autonomous vehicles. Classical single-agent reinforcement learning grapples with the imbalance of exploration and exploitation as well as limited generalization abilities. This methodology frequently leads to algorithms settling for suboptimal solutions that are tailored only to specific datasets. In this work, our aim is to train agent with efficient learning by decoupling exploration and utilization, so that agent can escaping the conundrum of suboptimal Solutions. In reinforcement learning, the previously imposed pessimistic punitive measures have deprived the model of its exploratory potential, resulting in diminished exploration capabilities. To address this, we have introduced an additional optimistic Actor to enhance the model's exploration ability, while employing a more constrained pessimistic Actor for performance evaluation. The above idea is implemented in the proposed OPARL (Optimistic and Pessimistic Actor Reinforcement Learning) algorithm. This unique amalgamation within the reinforcement learning paradigm fosters a more balanced and efficient approach. It facilitates the optimization of policies that concentrate on high-reward actions via pessimistic exploitation strategies while concurrently ensuring extensive state coverage through optimistic exploration. Empirical and theoretical investigations demonstrate that OPARL enhances agent capabilities in both utilization and exploration. In the most tasks of DMControl benchmark and Mujoco environment, OPARL performed better than state-of-the-art methods. Our code has released on https://github.com/yydsok/OPARL
5/13/2024