Exploring Large Language Models to generate Easy to Read content

0

Sign in to get full access
Overview
- Explores using large language models (LLMs) to generate easy-to-read content
- Examines the potential of LLMs to improve text simplification and readability
- Focuses on generating content that is more accessible to a wider audience
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text. This research paper explores using LLMs to create content that is easier to read and understand. The goal is to make information more accessible to a wider range of people, including those with lower reading levels or disabilities.
The researchers investigate whether LLMs can be used to simplify complex text, making it more straightforward and comprehensible. They examine different approaches to text simplification and explore the potential benefits of using LLMs for this task. This could have important implications for making information more inclusive and accessible to diverse audiences.
Technical Explanation
The paper examines the use of LLMs for text simplification and readability improvement. The researchers explore various techniques, including:
- Automatic text simplification: Using LLMs to rephrase complex sentences in simpler language without changing the core meaning.
- Readability assessment: Leveraging LLMs to evaluate the reading difficulty of a given text and provide recommendations for improvement.
- Content generation: Employing LLMs to generate new content that is inherently easier to understand, targeting specific reading levels or accessibility needs.
The researchers conduct experiments to assess the effectiveness of these approaches, comparing the performance of LLMs to traditional text simplification methods. They also explore the limitations and potential challenges of using LLMs for these tasks, such as ensuring factual accuracy and maintaining the intended meaning of the original text.
Critical Analysis
The paper presents a promising approach to using LLMs for text simplification and readability improvement. However, the researchers acknowledge some potential caveats and areas for further research. For instance, they note the importance of ensuring the factual accuracy and semantic integrity of the simplified text, as LLMs can sometimes introduce errors or unintended changes.
Additionally, the researchers suggest exploring the use of LLMs in combination with other techniques, such as linguistic analysis and rule-based simplification, to leverage the strengths of both approaches. Further research is also needed to assess the scalability and real-world deployment of these LLM-based simplification methods.
Conclusion
This research paper presents a compelling exploration of using large language models to generate easy-to-read content. The findings suggest that LLMs have the potential to significantly improve text simplification and readability, making information more accessible to a wider audience. While there are still some challenges to address, this study opens up new possibilities for using advanced AI systems to enhance inclusivity and expand access to knowledge. The ongoing development of these techniques could have far-reaching implications for education, healthcare, and various other domains where clear and comprehensible communication is of utmost importance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Exploring Large Language Models to generate Easy to Read content
Paloma Mart'inez, Lourdes Moreno, Alberto Ramos
Ensuring text accessibility and understandability are essential goals, particularly for individuals with cognitive impairments and intellectual disabilities, who encounter challenges in accessing information across various mediums such as web pages, newspapers, administrative tasks, or health documents. Initiatives like Easy to Read and Plain Language guidelines aim to simplify complex texts; however, standardizing these guidelines remains challenging and often involves manual processes. This work presents an exploratory investigation into leveraging Artificial Intelligence (AI) and Natural Language Processing (NLP) approaches to systematically simplify Spanish texts into Easy to Read formats, with a focus on utilizing Large Language Models (LLMs) for simplifying texts, especially in generating Easy to Read content. The study contributes a parallel corpus of Spanish adapted for Easy To Read format, which serves as a valuable resource for training and testing text simplification systems. Additionally, several text simplification experiments using LLMs and the collected corpus are conducted, involving fine-tuning and testing a Llama2 model to generate Easy to Read content. A qualitative evaluation, guided by an expert in text adaptation for Easy to Read content, is carried out to assess the automatically simplified texts. This research contributes to advancing text accessibility for individuals with cognitive impairments, highlighting promising strategies for leveraging LLMs while responsibly managing energy usage.
Read more7/30/2024
🌐
0
Difficulty Estimation and Simplification of French Text Using LLMs
Henri Jamet, Yash Raj Shrestha, Michalis Vlachos
We leverage generative large language models for language learning applications, focusing on estimating the difficulty of foreign language texts and simplifying them to lower difficulty levels. We frame both tasks as prediction problems and develop a difficulty classification model using labeled examples, transfer learning, and large language models, demonstrating superior accuracy compared to previous approaches. For simplification, we evaluate the trade-off between simplification quality and meaning preservation, comparing zero-shot and fine-tuned performances of large language models. We show that meaningful text simplifications can be obtained with limited fine-tuning. Our experiments are conducted on French texts, but our methods are language-agnostic and directly applicable to other foreign languages.
Read more7/26/2024
0
Towards Efficient Large Language Models for Scientific Text: A Review
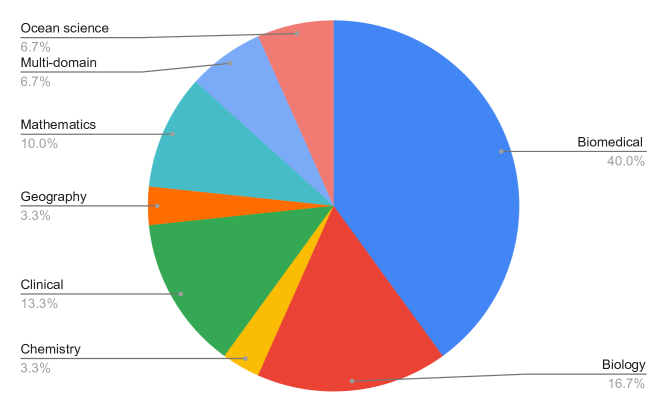
Huy Quoc To, Ming Liu, Guangyan Huang
Large language models (LLMs) have ushered in a new era for processing complex information in various fields, including science. The increasing amount of scientific literature allows these models to acquire and understand scientific knowledge effectively, thus improving their performance in a wide range of tasks. Due to the power of LLMs, they require extremely expensive computational resources, intense amounts of data, and training time. Therefore, in recent years, researchers have proposed various methodologies to make scientific LLMs more affordable. The most well-known approaches align in two directions. It can be either focusing on the size of the models or enhancing the quality of data. To date, a comprehensive review of these two families of methods has not yet been undertaken. In this paper, we (I) summarize the current advances in the emerging abilities of LLMs into more accessible AI solutions for science, and (II) investigate the challenges and opportunities of developing affordable solutions for scientific domains using LLMs.
Read more8/21/2024
0
Automatic Generation and Evaluation of Reading Comprehension Test Items with Large Language Models
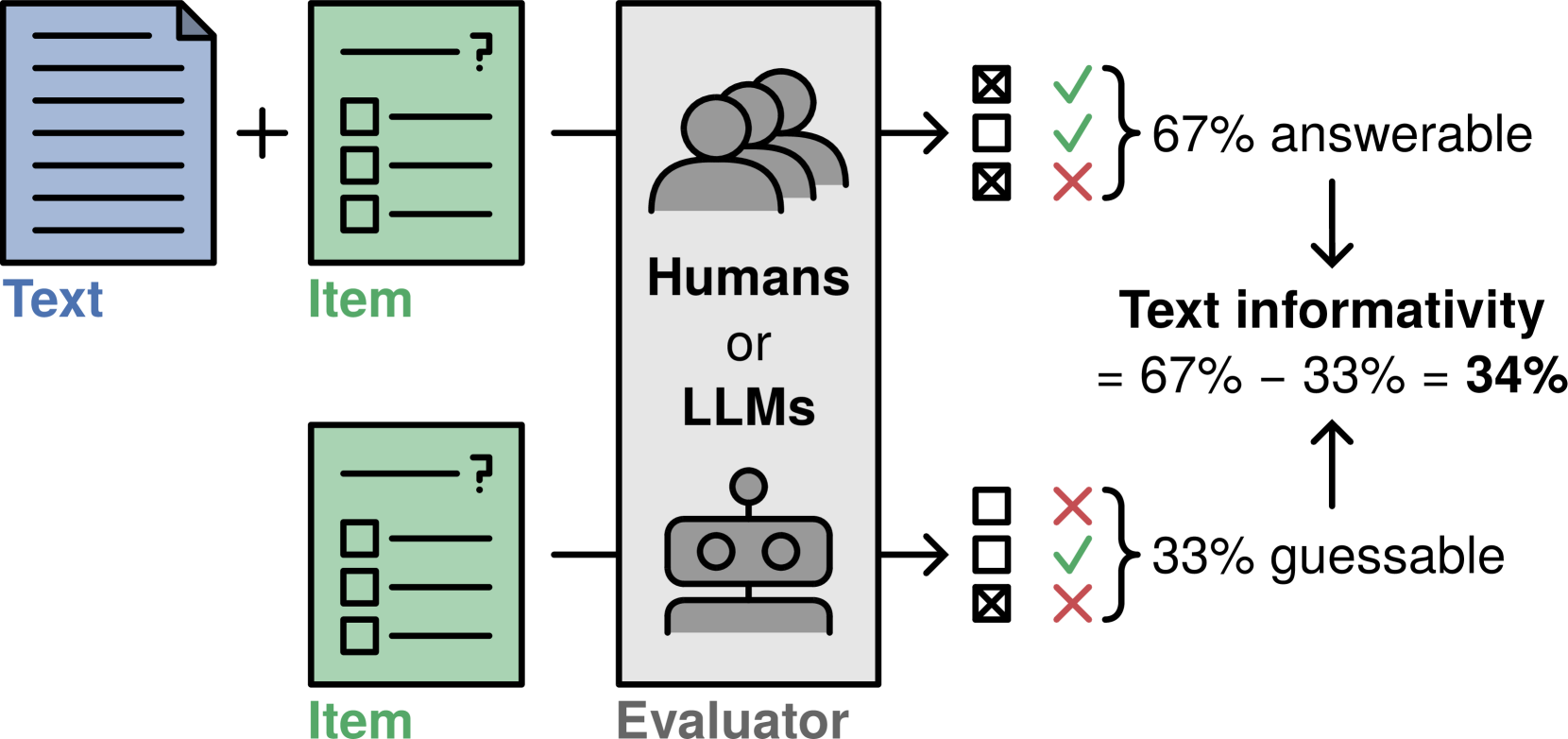
Andreas Sauberli, Simon Clematide
Reading comprehension tests are used in a variety of applications, reaching from education to assessing the comprehensibility of simplified texts. However, creating such tests manually and ensuring their quality is difficult and time-consuming. In this paper, we explore how large language models (LLMs) can be used to generate and evaluate multiple-choice reading comprehension items. To this end, we compiled a dataset of German reading comprehension items and developed a new protocol for human and automatic evaluation, including a metric we call text informativity, which is based on guessability and answerability. We then used this protocol and the dataset to evaluate the quality of items generated by Llama 2 and GPT-4. Our results suggest that both models are capable of generating items of acceptable quality in a zero-shot setting, but GPT-4 clearly outperforms Llama 2. We also show that LLMs can be used for automatic evaluation by eliciting item reponses from them. In this scenario, evaluation results with GPT-4 were the most similar to human annotators. Overall, zero-shot generation with LLMs is a promising approach for generating and evaluating reading comprehension test items, in particular for languages without large amounts of available data.
Read more5/22/2024