Language Model-Based Paired Variational Autoencoders for Robotic Language Learning
2201.06317
0
0
💬
Abstract
Human infants learn language while interacting with their environment in which their caregivers may describe the objects and actions they perform. Similar to human infants, artificial agents can learn language while interacting with their environment. In this work, first, we present a neural model that bidirectionally binds robot actions and their language descriptions in a simple object manipulation scenario. Building on our previous Paired Variational Autoencoders (PVAE) model, we demonstrate the superiority of the variational autoencoder over standard autoencoders by experimenting with cubes of different colours, and by enabling the production of alternative vocabularies. Additional experiments show that the model's channel-separated visual feature extraction module can cope with objects of different shapes. Next, we introduce PVAE-BERT, which equips the model with a pretrained large-scale language model, i.e., Bidirectional Encoder Representations from Transformers (BERT), enabling the model to go beyond comprehending only the predefined descriptions that the network has been trained on; the recognition of action descriptions generalises to unconstrained natural language as the model becomes capable of understanding unlimited variations of the same descriptions. Our experiments suggest that using a pretrained language model as the language encoder allows our approach to scale up for real-world scenarios with instructions from human users.
Create account to get full access
Overview
- This research paper presents a neural model that learns to bidirectionally bind robot actions and their language descriptions in a simple object manipulation scenario.
- The model, called Paired Variational Autoencoders (PVAE), demonstrates the superiority of variational autoencoders over standard autoencoders in this task.
- The paper also introduces PVAE-BERT, which equips the model with a pre-trained language model (BERT) to enable understanding of unconstrained natural language beyond the predefined descriptions used in training.
Plain English Explanation
The paper explores how artificial agents, similar to human infants, can learn language by interacting with their environment. The researchers developed a neural network model called Paired Variational Autoencoders (PVAE) that can learn to connect robot actions, like moving or manipulating objects, with the language used to describe those actions.
The PVAE model is built on the idea of a variational autoencoder, which is a type of neural network that can learn efficient representations of data. The researchers show that this variational approach outperforms standard autoencoders in this task, allowing the model to learn richer connections between actions and language.
The paper then introduces an enhanced version of the PVAE model, called PVAE-BERT, which incorporates a powerful pre-trained language model called BERT. This enables the model to understand a much wider range of natural language descriptions, beyond just the specific phrases it was trained on. The researchers demonstrate that this allows the model to scale up to real-world scenarios where it needs to comprehend language from human users.
Overall, this research explores how artificial agents can learn language in a grounded, interactive way, similar to how human infants acquire language skills. The innovations in the PVAE and PVAE-BERT models represent important steps towards building AI systems that can seamlessly communicate with and understand humans.
Technical Explanation
The paper first presents the Paired Variational Autoencoders (PVAE) model, which builds on the researchers' previous work. PVAE is a neural network that learns to bidirectionally link robot actions and their language descriptions in a simple object manipulation scenario.
The key idea behind PVAE is to use a variational autoencoder architecture, which the researchers show outperforms standard autoencoders in this task. The model consists of two channels: one for processing visual information about the robot's actions, and one for processing the corresponding language descriptions. These two channels are trained to learn a shared latent representation that captures the connection between the visual and linguistic modalities.
Through experiments with cubes of different colors, the researchers demonstrate that the PVAE model can handle variations in the visual features of the objects being manipulated. They also show that the model can generate alternative vocabularies for describing the same actions.
Building on PVAE, the paper then introduces PVAE-BERT, which integrates a pre-trained language model called BERT into the architecture. This allows the model to go beyond just comprehending the predefined descriptions it was trained on, and enables it to understand a much wider range of natural language. The researchers show that this BERT-based language encoder allows the approach to scale up to real-world scenarios with instructions from human users.
Critical Analysis
The paper makes several important contributions, but also acknowledges some limitations and areas for future research.
One key strength of the PVAE and PVAE-BERT models is their ability to learn rich, grounded representations of language and action through interactive, multimodal learning. This aligns with the way human infants acquire language skills and could have important implications for building more natural and intuitive AI systems.
However, the paper notes that the current experiments are still limited to a relatively simple object manipulation scenario. Scaling up to more complex, real-world tasks with varied environments and a broader range of actions and language will likely require further advancements.
Additionally, while the incorporation of BERT in PVAE-BERT represents an important step, the paper suggests that even more powerful language models or further architectural innovations may be needed to truly unlock the model's potential for understanding unconstrained natural language.
The paper also does not address potential safety or ethical concerns that may arise as these types of language-learning agents become more capable and are deployed in real-world settings. Careful consideration of these issues will be crucial as the research in this area progresses.
Overall, the PVAE and PVAE-BERT models presented in this paper make valuable contributions to the field of multimodal learning and language grounding. However, significant challenges remain in scaling these approaches to truly robust, general-purpose language understanding for artificial agents.
Conclusion
This research paper introduces a novel neural network model called Paired Variational Autoencoders (PVAE) that learns to bidirectionally connect robot actions and their language descriptions. The model's use of a variational autoencoder architecture is shown to outperform standard autoencoders in this task.
Building on PVAE, the researchers develop PVAE-BERT, which integrates a powerful pre-trained language model (BERT) to enable the system to understand a much wider range of natural language beyond just the predefined descriptions it was trained on. This represents an important step towards scaling up these types of language-learning agents for real-world applications with human-provided instructions.
The paper's findings contribute to the broader goal of developing artificial agents that can learn language in a grounded, interactive way, similar to how human infants acquire language skills. While significant challenges remain, this research points the way towards more natural and intuitive forms of human-AI communication and collaboration.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
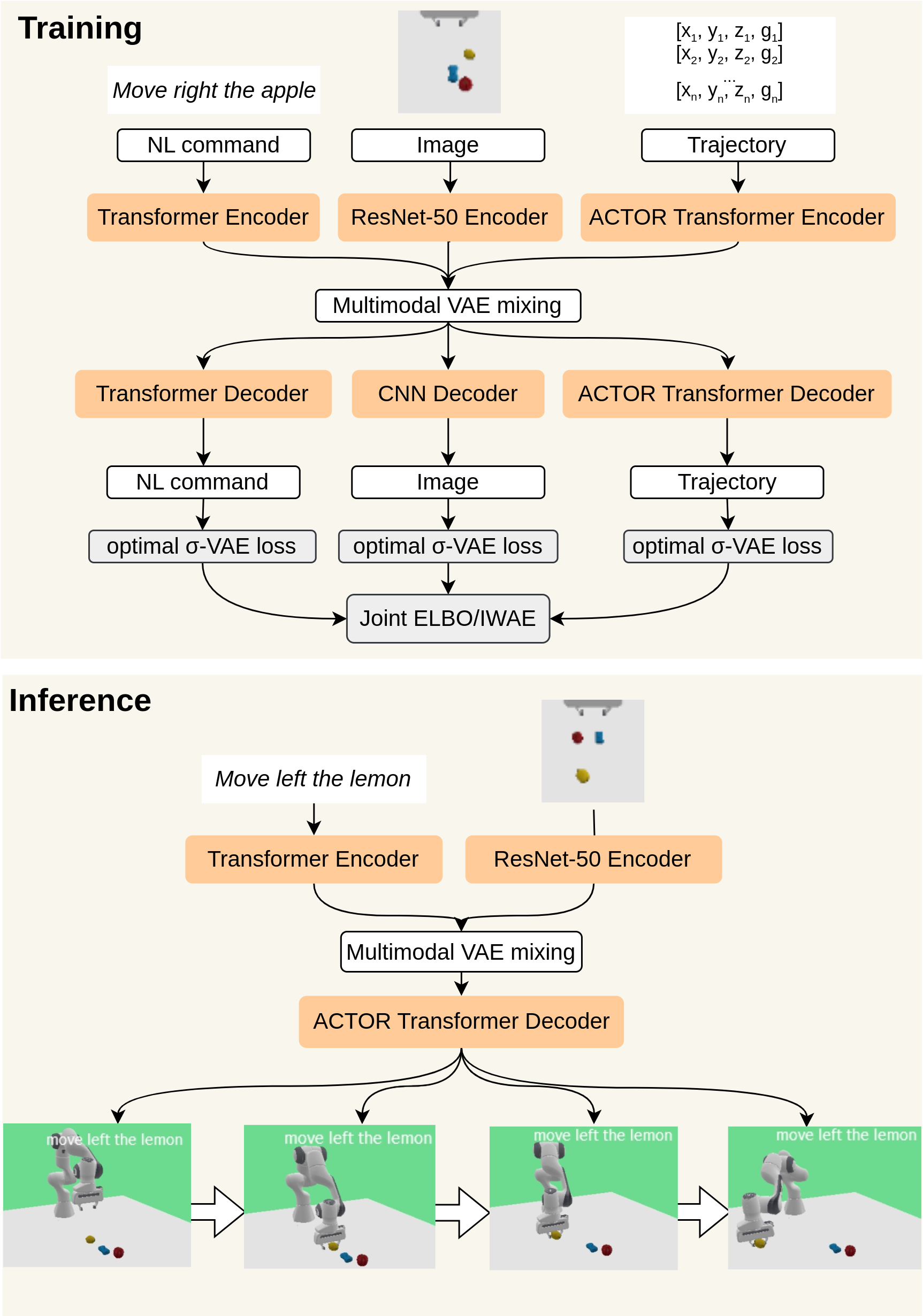
Bridging Language, Vision and Action: Multimodal VAEs in Robotic Manipulation Tasks
Gabriela Sejnova, Michal Vavrecka, Karla Stepanova
0
0
In this work, we focus on unsupervised vision-language-action mapping in the area of robotic manipulation. Recently, multiple approaches employing pre-trained large language and vision models have been proposed for this task. However, they are computationally demanding and require careful fine-tuning of the produced outputs. A more lightweight alternative would be the implementation of multimodal Variational Autoencoders (VAEs) which can extract the latent features of the data and integrate them into a joint representation, as has been demonstrated mostly on image-image or image-text data for the state-of-the-art models. Here we explore whether and how can multimodal VAEs be employed in unsupervised robotic manipulation tasks in a simulated environment. Based on the obtained results, we propose a model-invariant training alternative that improves the models' performance in a simulator by up to 55%. Moreover, we systematically evaluate the challenges raised by the individual tasks such as object or robot position variability, number of distractors or the task length. Our work thus also sheds light on the potential benefits and limitations of using the current multimodal VAEs for unsupervised learning of robotic motion trajectories based on vision and language.
4/3/2024
🤖
A Survey on Vision-Language-Action Models for Embodied AI
Yueen Ma, Zixing Song, Yuzheng Zhuang, Jianye Hao, Irwin King
0
0
Deep learning has demonstrated remarkable success across many domains, including computer vision, natural language processing, and reinforcement learning. Representative artificial neural networks in these fields span convolutional neural networks, Transformers, and deep Q-networks. Built upon unimodal neural networks, numerous multi-modal models have been introduced to address a range of tasks such as visual question answering, image captioning, and speech recognition. The rise of instruction-following robotic policies in embodied AI has spurred the development of a novel category of multi-modal models known as vision-language-action models (VLAs). Their multi-modality capability has become a foundational element in robot learning. Various methods have been proposed to enhance traits such as versatility, dexterity, and generalizability. Some models focus on refining specific components through pretraining. Others aim to develop control policies adept at predicting low-level actions. Certain VLAs serve as high-level task planners capable of decomposing long-horizon tasks into executable subtasks. Over the past few years, a myriad of VLAs have emerged, reflecting the rapid advancement of embodied AI. Therefore, it is imperative to capture the evolving landscape through a comprehensive survey.
5/24/2024

Exploring Latent Pathways: Enhancing the Interpretability of Autonomous Driving with a Variational Autoencoder
Anass Bairouk, Mirjana Maras, Simon Herlin, Alexander Amini, Marc Blanchon, Ramin Hasani, Patrick Chareyre, Daniela Rus
0
0
Autonomous driving presents a complex challenge, which is usually addressed with artificial intelligence models that are end-to-end or modular in nature. Within the landscape of modular approaches, a bio-inspired neural circuit policy model has emerged as an innovative control module, offering a compact and inherently interpretable system to infer a steering wheel command from abstract visual features. Here, we take a leap forward by integrating a variational autoencoder with the neural circuit policy controller, forming a solution that directly generates steering commands from input camera images. By substituting the traditional convolutional neural network approach to feature extraction with a variational autoencoder, we enhance the system's interpretability, enabling a more transparent and understandable decision-making process. In addition to the architectural shift toward a variational autoencoder, this study introduces the automatic latent perturbation tool, a novel contribution designed to probe and elucidate the latent features within the variational autoencoder. The automatic latent perturbation tool automates the interpretability process, offering granular insights into how specific latent variables influence the overall model's behavior. Through a series of numerical experiments, we demonstrate the interpretative power of the variational autoencoder-neural circuit policy model and the utility of the automatic latent perturbation tool in making the inner workings of autonomous driving systems more transparent.
4/3/2024
🔎
Poisson Variational Autoencoder
Hadi Vafaii, Dekel Galor, Jacob L. Yates
0
0
Variational autoencoders (VAE) employ Bayesian inference to interpret sensory inputs, mirroring processes that occur in primate vision across both ventral (Higgins et al., 2021) and dorsal (Vafaii et al., 2023) pathways. Despite their success, traditional VAEs rely on continuous latent variables, which deviates sharply from the discrete nature of biological neurons. Here, we developed the Poisson VAE (P-VAE), a novel architecture that combines principles of predictive coding with a VAE that encodes inputs into discrete spike counts. Combining Poisson-distributed latent variables with predictive coding introduces a metabolic cost term in the model loss function, suggesting a relationship with sparse coding which we verify empirically. Additionally, we analyze the geometry of learned representations, contrasting the P-VAE to alternative VAE models. We find that the P-VAEencodes its inputs in relatively higher dimensions, facilitating linear separability of categories in a downstream classification task with a much better (5x) sample efficiency. Our work provides an interpretable computational framework to study brain-like sensory processing and paves the way for a deeper understanding of perception as an inferential process.
5/24/2024