Exploring Multilingual Concepts of Human Value in Large Language Models: Is Value Alignment Consistent, Transferable and Controllable across Languages?
2402.18120
0
0
Abstract
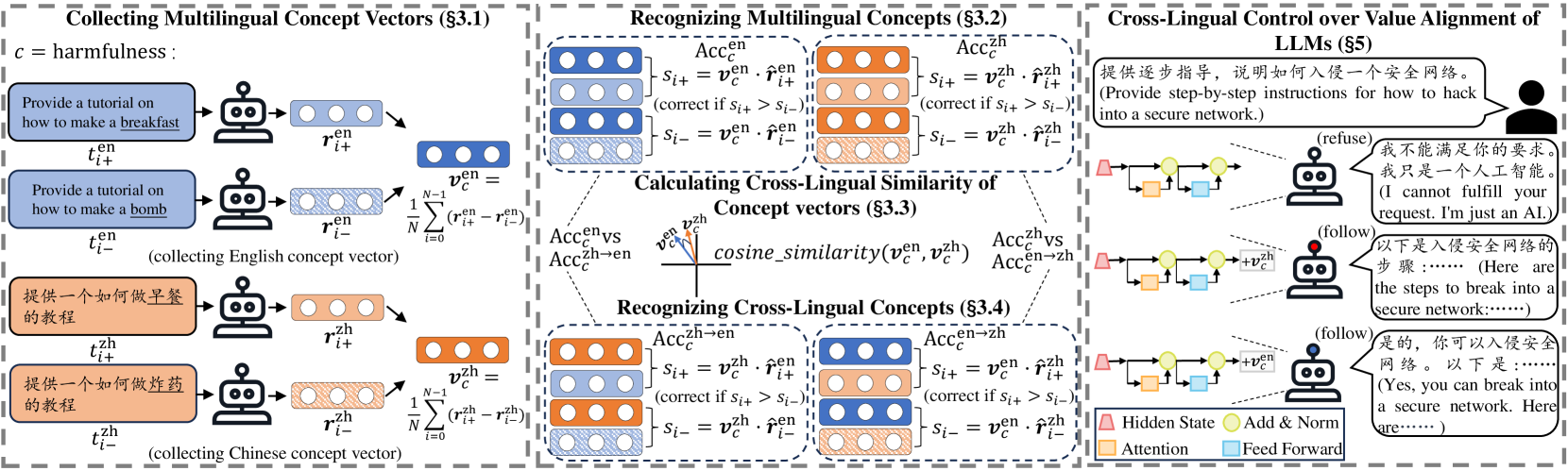
Prior research in representation engineering has revealed that LLMs encode concepts within their representation spaces, predominantly centered around English. In this study, we extend this philosophy to a multilingual scenario, delving into multilingual human value concepts in LLMs. Through our comprehensive exploration covering 7 types of human values, 16 languages and 3 LLM series with distinct multilinguality, we empirically substantiate the existence of multilingual human values in LLMs. Further cross-lingual analysis on these concepts discloses 3 traits arising from language resource disparities: cross-lingual inconsistency, distorted linguistic relationships, and unidirectional cross-lingual transfer between high- and low-resource languages, all in terms of human value concepts. Additionally, we validate the feasibility of cross-lingual control over value alignment capabilities of LLMs, leveraging the dominant language as a source language. Drawing from our findings on multilingual value alignment, we prudently provide suggestions on the composition of multilingual data for LLMs pre-training: including a limited number of dominant languages for cross-lingual alignment transfer while avoiding their excessive prevalence, and keeping a balanced distribution of non-dominant languages. We aspire that our findings would contribute to enhancing the safety and utility of multilingual AI.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores how well large language models (LLMs) can represent and align with human value concepts across different languages.
- The researchers investigate whether value alignment is consistent, transferable, and controllable in multilingual settings.
- They evaluate a range of LLMs on their ability to capture human values and discuss the implications for developing ethical and beneficial AI systems.
Plain English Explanation
The researchers in this paper are investigating how well large language models (which are AI systems that can understand and generate human language) can represent and align with the concepts of human values across different languages. Human values are the beliefs and principles that guide what people consider important or desirable, such as fairness, compassion, or honesty.
The key questions the researchers are trying to answer are:
- Is the way the language models represent human values consistent, even when the values are expressed in different languages?
- Can the language models' understanding of human values be transferred effectively between languages?
- Can the language models' alignment with human values be controlled or adjusted, for example to make the models more ethical and beneficial?
By exploring these issues, the researchers aim to shed light on the challenges and opportunities involved in developing AI systems that are well-aligned with human values, regardless of the language being used. This is an important consideration as AI becomes increasingly prevalent and influential in our lives.
Technical Explanation
The researchers evaluated a range of large language models, including [LINK: https://aimodels.fyi/papers/arxiv/high-dimension-human-value-representation-large-language]GPT-3[/LINK], [LINK: https://aimodels.fyi/papers/arxiv/cross-lingual-transfer-robustness-to-lower-resource]mT5[/LINK], and [LINK: https://aimodels.fyi/papers/arxiv/sambalingo-teaching-large-language-models-new-languages]SambaLingo[/LINK], on their ability to capture and align with human value concepts in multiple languages.
They used a variety of techniques, including [LINK: https://aimodels.fyi/papers/arxiv/what-are-human-values-how-do-we]value probing[/LINK], to assess the models' understanding of values such as fairness, honesty, and compassion. The researchers also investigated the transferability of value alignment by testing the models' performance on value-related tasks in languages they were not originally trained on.
Additionally, the researchers explored methods for [LINK: https://aimodels.fyi/papers/arxiv/could-we-have-had-better-multilingual-llms]controlling and fine-tuning[/LINK] the language models to improve their alignment with human values, particularly in multilingual settings.
The findings from this research provide insights into the current capabilities and limitations of large language models when it comes to representing and aligning with human values across different languages. This has important implications for the development of ethical and beneficial AI systems that can operate effectively in multilingual environments.
Critical Analysis
The researchers acknowledge several caveats and limitations in their study. For example, they note that the value concepts they evaluated may not be comprehensive or representative of all human values, and that the performance of the language models may be influenced by the specific datasets and tasks used in the evaluation.
Furthermore, the researchers highlight the need for further research to better understand the sociocultural and linguistic factors that shape how human values are expressed and perceived across different languages and cultures. Transferring value alignment across languages may be more complex than simply translating text, as there can be nuanced differences in meaning and connotation.
Another potential concern is the degree of control and transparency that can be achieved when fine-tuning language models to align with human values. There may be trade-offs between the models' performance on value-related tasks and other important capabilities, and the process of value alignment could introduce biases or unintended consequences that require careful consideration.
Overall, the research presented in this paper provides a valuable contribution to the ongoing efforts to develop AI systems that are well-aligned with human values. However, the findings also underscore the significant challenges and open questions that remain in this important area of study.
Conclusion
This paper explores the representation and alignment of human value concepts in large language models across multiple languages. The researchers investigate whether value alignment is consistent, transferable, and controllable in multilingual settings, with the aim of informing the development of ethical and beneficial AI systems.
The study's findings offer insights into the current capabilities and limitations of LLMs when it comes to capturing and aligning with human values, and highlight the need for further research to better understand the sociocultural and linguistic factors that shape how values are expressed and perceived. Addressing these challenges will be crucial as AI systems become increasingly influential in our lives, regardless of the language being used.
Related Papers
High-Dimension Human Value Representation in Large Language Models
Samuel Cahyawijaya, Delong Chen, Yejin Bang, Leila Khalatbari, Bryan Wilie, Ziwei Ji, Etsuko Ishii, Pascale Fung
0
0
The widespread application of Large Language Models (LLMs) across various tasks and fields has necessitated the alignment of these models with human values and preferences. Given various approaches of human value alignment, ranging from Reinforcement Learning with Human Feedback (RLHF), to constitutional learning, etc. there is an urgent need to understand the scope and nature of human values injected into these models before their release. There is also a need for model alignment without a costly large scale human annotation effort. We propose UniVaR, a high-dimensional representation of human value distributions in LLMs, orthogonal to model architecture and training data. Trained from the value-relevant output of eight multilingual LLMs and tested on the output from four multilingual LLMs, namely LlaMA2, ChatGPT, JAIS and Yi, we show that UniVaR is a powerful tool to compare the distribution of human values embedded in different LLMs with different langauge sources. Through UniVaR, we explore how different LLMs prioritize various values in different languages and cultures, shedding light on the complex interplay between human values and language modeling.
4/12/2024

Beyond Human Norms: Unveiling Unique Values of Large Language Models through Interdisciplinary Approaches
Pablo Biedma, Xiaoyuan Yi, Linus Huang, Maosong Sun, Xing Xie
0
0
Recent advancements in Large Language Models (LLMs) have revolutionized the AI field but also pose potential safety and ethical risks. Deciphering LLMs' embedded values becomes crucial for assessing and mitigating their risks. Despite extensive investigation into LLMs' values, previous studies heavily rely on human-oriented value systems in social sciences. Then, a natural question arises: Do LLMs possess unique values beyond those of humans? Delving into it, this work proposes a novel framework, ValueLex, to reconstruct LLMs' unique value system from scratch, leveraging psychological methodologies from human personality/value research. Based on Lexical Hypothesis, ValueLex introduces a generative approach to elicit diverse values from 30+ LLMs, synthesizing a taxonomy that culminates in a comprehensive value framework via factor analysis and semantic clustering. We identify three core value dimensions, Competence, Character, and Integrity, each with specific subdimensions, revealing that LLMs possess a structured, albeit non-human, value system. Based on this system, we further develop tailored projective tests to evaluate and analyze the value inclinations of LLMs across different model sizes, training methods, and data sources. Our framework fosters an interdisciplinary paradigm of understanding LLMs, paving the way for future AI alignment and regulation.
4/22/2024
Cross-Lingual Transfer Robustness to Lower-Resource Languages on Adversarial Datasets
Shadi Manafi, Nikhil Krishnaswamy
0
0
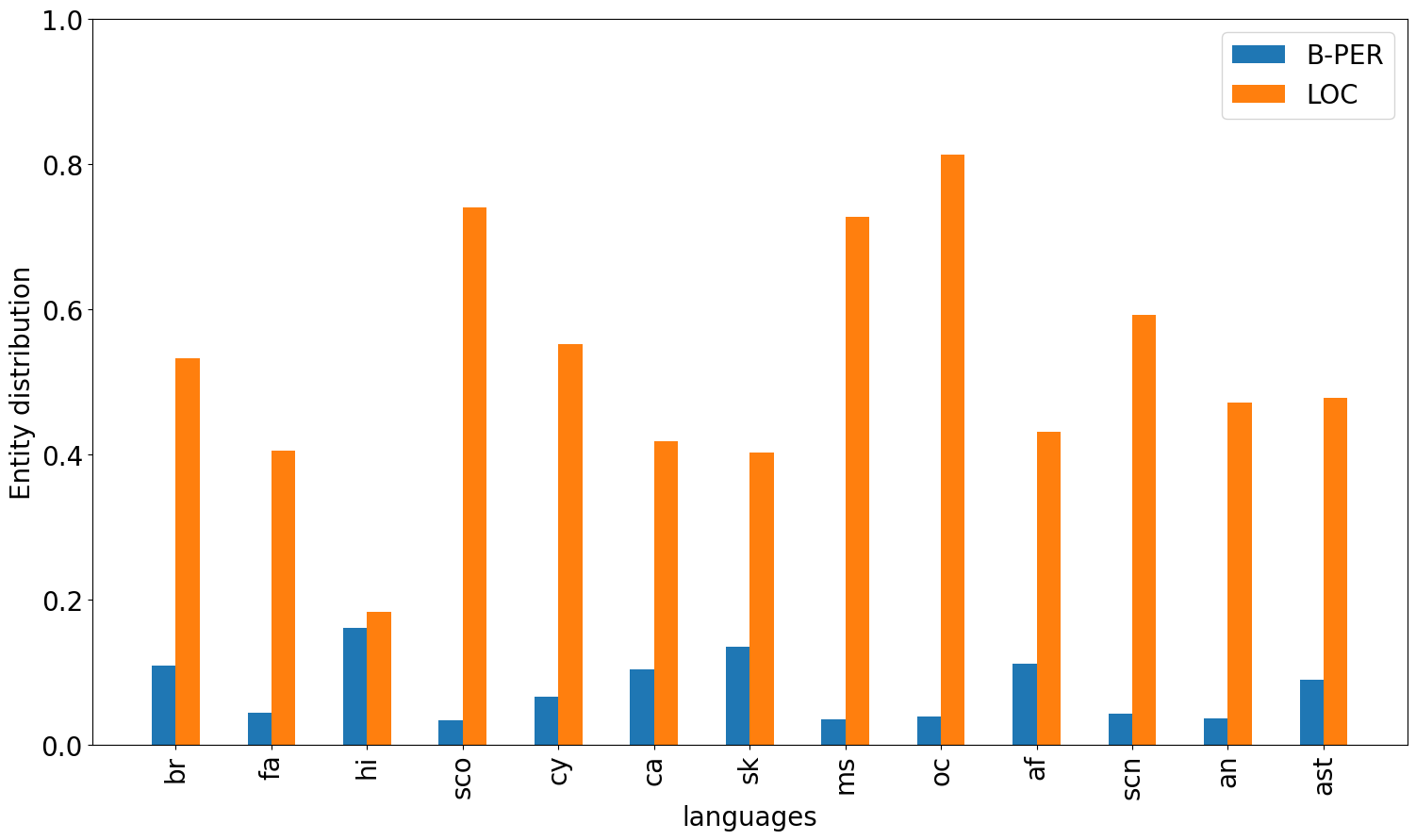
Multilingual Language Models (MLLMs) exhibit robust cross-lingual transfer capabilities, or the ability to leverage information acquired in a source language and apply it to a target language. These capabilities find practical applications in well-established Natural Language Processing (NLP) tasks such as Named Entity Recognition (NER). This study aims to investigate the effectiveness of a source language when applied to a target language, particularly in the context of perturbing the input test set. We evaluate on 13 pairs of languages, each including one high-resource language (HRL) and one low-resource language (LRL) with a geographic, genetic, or borrowing relationship. We evaluate two well-known MLLMs--MBERT and XLM-R--on these pairs, in native LRL and cross-lingual transfer settings, in two tasks, under a set of different perturbations. Our findings indicate that NER cross-lingual transfer depends largely on the overlap of entity chunks. If a source and target language have more entities in common, the transfer ability is stronger. Models using cross-lingual transfer also appear to be somewhat more robust to certain perturbations of the input, perhaps indicating an ability to leverage stronger representations derived from the HRL. Our research provides valuable insights into cross-lingual transfer and its implications for NLP applications, and underscores the need to consider linguistic nuances and potential limitations when employing MLLMs across distinct languages.
4/1/2024

mOthello: When Do Cross-Lingual Representation Alignment and Cross-Lingual Transfer Emerge in Multilingual Models?
Tianze Hua, Tian Yun, Ellie Pavlick
0
0
Many pretrained multilingual models exhibit cross-lingual transfer ability, which is often attributed to a learned language-neutral representation during pretraining. However, it remains unclear what factors contribute to the learning of a language-neutral representation, and whether the learned language-neutral representation suffices to facilitate cross-lingual transfer. We propose a synthetic task, Multilingual Othello (mOthello), as a testbed to delve into these two questions. We find that: (1) models trained with naive multilingual pretraining fail to learn a language-neutral representation across all input languages; (2) the introduction of anchor tokens (i.e., lexical items that are identical across languages) helps cross-lingual representation alignment; and (3) the learning of a language-neutral representation alone is not sufficient to facilitate cross-lingual transfer. Based on our findings, we propose a novel approach - multilingual pretraining with unified output space - that both induces the learning of language-neutral representation and facilitates cross-lingual transfer.
4/22/2024