Exploring Pessimism and Optimism Dynamics in Deep Reinforcement Learning
2406.03890
0
0

Abstract
Off-policy actor-critic algorithms have shown promise in deep reinforcement learning for continuous control tasks. Their success largely stems from leveraging pessimistic state-action value function updates, which effectively address function approximation errors and improve performance. However, such pessimism can lead to under-exploration, constraining the agent's ability to explore/refine its policies. Conversely, optimism can counteract under-exploration, but it also carries the risk of excessive risk-taking and poor convergence if not properly balanced. Based on these insights, we introduce Utility Soft Actor-Critic (USAC), a novel framework within the actor-critic paradigm that enables independent control over the degree of pessimism/optimism for both the actor and the critic via interpretable parameters. USAC adapts its exploration strategy based on the uncertainty of critics through a utility function that allows us to balance between pessimism and optimism separately. By going beyond binary choices of optimism and pessimism, USAC represents a significant step towards achieving balance within off-policy actor-critic algorithms. Our experiments across various continuous control problems show that the degree of pessimism or optimism depends on the nature of the task. Furthermore, we demonstrate that USAC can outperform state-of-the-art algorithms for appropriately configured pessimism/optimism parameters.
Create account to get full access
Overview
• The paper explores the dynamics of pessimism and optimism in deep reinforcement learning (RL) agents, investigating how these factors impact their performance and behavior.
• The researchers propose several approaches to modulating the level of pessimism or optimism in RL agents, and evaluate the effects on task performance and exploration/exploitation tradeoffs.
Plain English Explanation
• Reinforcement learning (RL) is a type of machine learning where agents learn to make decisions by interacting with their environment and receiving rewards or penalties. link to "Theory of Risk-Aware Agents: Bridging Actor-Critic"
• In this paper, the researchers looked at how the level of pessimism or optimism in RL agents can affect their performance. Pessimistic agents may be more cautious and avoid risks, while optimistic agents may be more willing to try new things.
• The researchers tested different ways to adjust the balance of pessimism and optimism in the agents, and examined how this impacted their ability to solve tasks and explore their environment. link to "Efficient Reinforcement Learning via Decoupling Exploration & Utilization"
• The goal was to better understand how to create RL agents that can effectively navigate the tradeoff between exploring new options and exploiting what they've already learned. link to "Actor-Critic Reinforcement Learning in Phased Actor"
Technical Explanation
• The paper proposes several methods for modulating the level of pessimism or optimism in RL agents, including using ensemble models, Bayesian uncertainty estimates, and constrained optimization techniques. link to "Value-Improved Actor-Critic Algorithms"
• The researchers evaluated these approaches on a suite of reinforcement learning benchmark tasks, measuring the agents' task performance as well as metrics related to exploration and exploitation.
• The results suggest that incorporating the right level of pessimism or optimism can lead to significant improvements in an agent's ability to solve challenging tasks, especially when there is a complex trade-off between exploration and exploitation. link to "Unified PAC-Bayesian Study of Pessimism in Offline Policy"
Critical Analysis
• The paper provides a comprehensive and rigorous analysis of the role of pessimism and optimism in RL, offering valuable insights for the design of more effective and robust RL agents.
• However, the proposed methods may be computationally expensive or difficult to scale to very large problem domains, and the researchers acknowledge that further work is needed to make them more efficient and practical.
• Additionally, the paper focuses primarily on task performance and exploration/exploitation metrics, but does not deeply explore other important factors such as safety, robustness, or interpretability.
Conclusion
• This paper contributes to our understanding of how the balance of pessimism and optimism can impact the behavior and performance of deep reinforcement learning agents.
• The insights from this research could inform the development of more sophisticated RL systems that can adaptively regulate their level of risk-taking and exploration to improve their overall effectiveness in complex, real-world environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤷
PAC-Bayesian Soft Actor-Critic Learning
Bahareh Tasdighi, Abdullah Akgul, Manuel Haussmann, Kenny Kazimirzak Brink, Melih Kandemir
0
0
Actor-critic algorithms address the dual goals of reinforcement learning (RL), policy evaluation and improvement via two separate function approximators. The practicality of this approach comes at the expense of training instability, caused mainly by the destructive effect of the approximation errors of the critic on the actor. We tackle this bottleneck by employing an existing Probably Approximately Correct (PAC) Bayesian bound for the first time as the critic training objective of the Soft Actor-Critic (SAC) algorithm. We further demonstrate that online learning performance improves significantly when a stochastic actor explores multiple futures by critic-guided random search. We observe our resulting algorithm to compare favorably against the state-of-the-art SAC implementation on multiple classical control and locomotion tasks in terms of both sample efficiency and regret.
6/11/2024
❗
On the Theory of Risk-Aware Agents: Bridging Actor-Critic and Economics
Michal Nauman, Marek Cygan
0
0
Risk-aware Reinforcement Learning (RL) algorithms like SAC and TD3 were shown empirically to outperform their risk-neutral counterparts in a variety of continuous-action tasks. However, the theoretical basis for the pessimistic objectives these algorithms employ remains unestablished, raising questions about the specific class of policies they are implementing. In this work, we apply the expected utility hypothesis, a fundamental concept in economics, to illustrate that both risk-neutral and risk-aware RL goals can be interpreted through expected utility maximization using an exponential utility function. This approach reveals that risk-aware policies effectively maximize value certainty equivalent, aligning them with conventional decision theory principles. Furthermore, we propose Dual Actor-Critic (DAC). DAC is a risk-aware, model-free algorithm that features two distinct actor networks: a pessimistic actor for temporal-difference learning and an optimistic actor for exploration. Our evaluations of DAC across various locomotion and manipulation tasks demonstrate improvements in sample efficiency and final performance. Remarkably, DAC, while requiring significantly less computational resources, matches the performance of leading model-based methods in the complex dog and humanoid domains.
5/27/2024
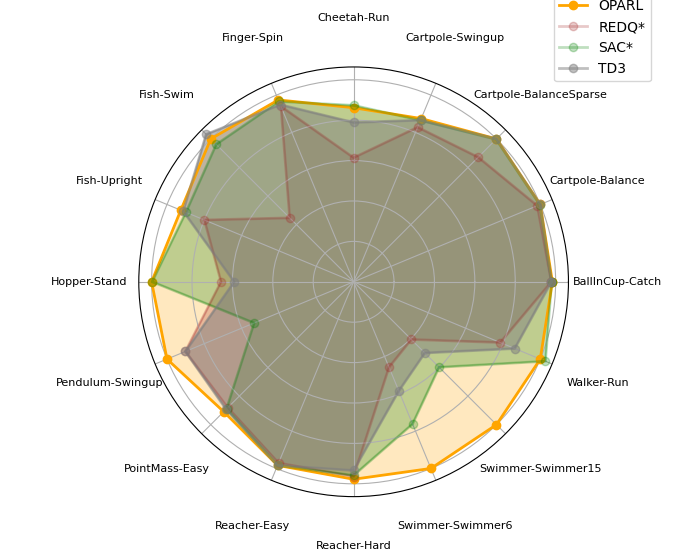
Efficient Reinforcement Learning via Decoupling Exploration and Utilization
Jingpu Yang, Helin Wang, Qirui Zhao, Zhecheng Shi, Zirui Song, Miao Fang
0
0
Reinforcement Learning (RL), recognized as an efficient learning approach, has achieved remarkable success across multiple fields and applications, including gaming, robotics, and autonomous vehicles. Classical single-agent reinforcement learning grapples with the imbalance of exploration and exploitation as well as limited generalization abilities. This methodology frequently leads to algorithms settling for suboptimal solutions that are tailored only to specific datasets. In this work, our aim is to train agent with efficient learning by decoupling exploration and utilization, so that agent can escaping the conundrum of suboptimal Solutions. In reinforcement learning, the previously imposed pessimistic punitive measures have deprived the model of its exploratory potential, resulting in diminished exploration capabilities. To address this, we have introduced an additional optimistic Actor to enhance the model's exploration ability, while employing a more constrained pessimistic Actor for performance evaluation. The above idea is implemented in the proposed OPARL (Optimistic and Pessimistic Actor Reinforcement Learning) algorithm. This unique amalgamation within the reinforcement learning paradigm fosters a more balanced and efficient approach. It facilitates the optimization of policies that concentrate on high-reward actions via pessimistic exploitation strategies while concurrently ensuring extensive state coverage through optimistic exploration. Empirical and theoretical investigations demonstrate that OPARL enhances agent capabilities in both utilization and exploration. In the most tasks of DMControl benchmark and Mujoco environment, OPARL performed better than state-of-the-art methods. Our code has released on https://github.com/yydsok/OPARL
5/13/2024

Actor-Critic Reinforcement Learning with Phased Actor
Ruofan Wu, Junmin Zhong, Jennie Si
0
0
Policy gradient methods in actor-critic reinforcement learning (RL) have become perhaps the most promising approaches to solving continuous optimal control problems. However, the trial-and-error nature of RL and the inherent randomness associated with solution approximations cause variations in the learned optimal values and policies. This has significantly hindered their successful deployment in real life applications where control responses need to meet dynamic performance criteria deterministically. Here we propose a novel phased actor in actor-critic (PAAC) method, aiming at improving policy gradient estimation and thus the quality of the control policy. Specifically, PAAC accounts for both $Q$ value and TD error in its actor update. We prove qualitative properties of PAAC for learning convergence of the value and policy, solution optimality, and stability of system dynamics. Additionally, we show variance reduction in policy gradient estimation. PAAC performance is systematically and quantitatively evaluated in this study using DeepMind Control Suite (DMC). Results show that PAAC leads to significant performance improvement measured by total cost, learning variance, robustness, learning speed and success rate. As PAAC can be piggybacked onto general policy gradient learning frameworks, we select well-known methods such as direct heuristic dynamic programming (dHDP), deep deterministic policy gradient (DDPG) and their variants to demonstrate the effectiveness of PAAC. Consequently we provide a unified view on these related policy gradient algorithms.
4/19/2024