Exploring Spatial Representations in the Historical Lake District Texts with LLM-based Relation Extraction

0
Sign in to get full access
Overview
- This paper explores how large language models (LLMs) can be used to analyze spatial representations in historical texts about the Lake District region of England.
- The researchers use relation extraction techniques to identify and understand the spatial relationships described in the texts, such as the locations of landmarks, geographical features, and their relative positions.
- The findings provide insights into how LLMs can be leveraged to uncover valuable spatial information from unstructured historical documents, which could have applications in fields like digital humanities, geography, and cultural heritage preservation.
Plain English Explanation
The researchers in this paper were interested in understanding how the Lake District, a famous natural region in England, was described in historical texts. They used a special type of AI model called a "large language model" (LLM) to analyze these texts and identify the spatial relationships mentioned in them.
For example, the LLM could detect when a text was talking about the location of a mountain or lake, and how that feature was positioned relative to other landmarks. By extracting this spatial information, the researchers were able to gain insights into how people thought about and perceived the geography of the Lake District over time.
This type of analysis could be useful for a few reasons. First, it allows us to better understand the cultural and historical significance of places like the Lake District by seeing how they were portrayed in the writings of the past. Second, it demonstrates how powerful AI language models can be for extracting meaningful information from unstructured text data, which has applications in fields like digital humanities and geography. Overall, the study provides an interesting example of how advanced AI can be used to explore and preserve our cultural heritage.
Technical Explanation
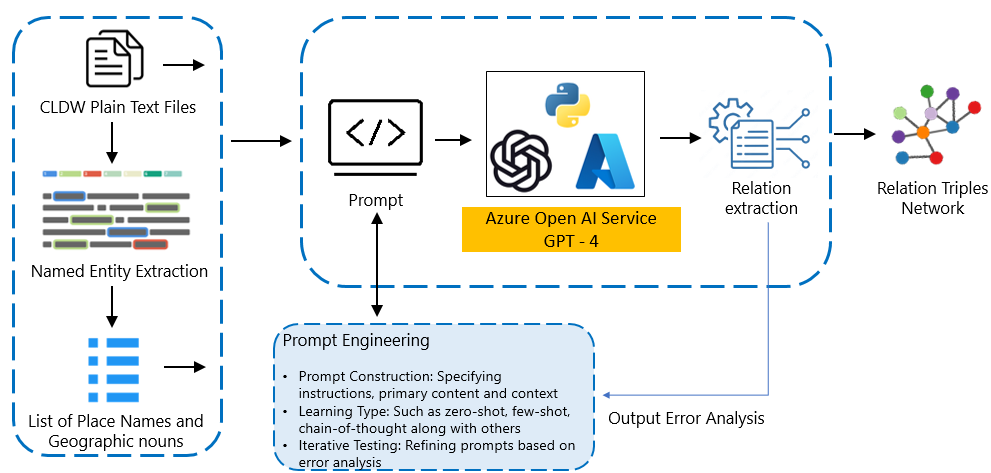
The researchers in this paper employed a relation extraction approach using large language models (LLMs) to identify and analyze spatial relationships described in a corpus of historical texts about the Lake District region.
They first preprocessed the text corpus to extract relevant named entities, such as place names and geographical features. They then used a fine-tuned BERT-based relation extraction model to detect spatial relations between these entities, such as "located_in", "part_of", and "near".
By aggregating and visualizing the extracted spatial relations, the researchers were able to uncover interesting insights about how the Lake District was conceptualized and described in the historical documents. For example, they found that certain landmarks were more prominent in the texts than others, and that the positioning of features relative to each other changed over time.
The GraphiCal reasoning capabilities of the LLMs also allowed the researchers to locate and extract more nuanced spatial concepts, such as the perceived distortions in how the geography of the region was described.
Overall, this study demonstrates the potential of using advanced AI techniques to uncover valuable spatial and cultural insights from unstructured historical texts, which could have applications in fields like digital humanities, geography, and cultural heritage preservation.
Critical Analysis
The researchers acknowledge several limitations and caveats in their work. First, the text corpus they analyzed was relatively small, focused only on historical writings about the Lake District. Expanding the analysis to a wider range of texts, from different time periods and geographical regions, could provide a richer and more comprehensive understanding of how spaces were conceptualized in the past.
Additionally, while the relation extraction model performed well on the specific task, the researchers note that LLMs can sometimes struggle with accurately representing more complex spatial relationships and concepts. Further research may be needed to improve the spatial reasoning capabilities of these models, perhaps by incorporating additional domain-specific knowledge or multimodal information.
It is also important to consider the potential biases and limitations inherent in the historical texts themselves. The way the Lake District was portrayed may have been influenced by the perspectives and agendas of the authors, rather than reflecting a neutral or objective representation of the region. Careful consideration of these contextual factors is necessary when drawing conclusions from the analysis.
Despite these limitations, this study offers a promising approach for leveraging advanced AI techniques to gain new insights into our cultural and historical heritage. By continuing to explore and refine these methods, researchers may uncover valuable spatial and relational information that could help us better understand and preserve important places and the stories they hold.
Conclusion
This paper presents an innovative application of large language models and relation extraction techniques to analyze spatial representations in historical texts about the Lake District region of England. The researchers were able to extract and visualize the spatial relationships described in the texts, providing insights into how this important geographical area was conceptualized and portrayed over time.
The findings of this study demonstrate the potential of using AI-powered text analysis to uncover valuable cultural and historical information from unstructured sources. This approach could have significant applications in fields like digital humanities, geography, and cultural heritage preservation, helping us to better understand and appreciate the rich tapestry of our shared past.
As language models and other AI technologies continue to advance, researchers will likely find increasingly sophisticated ways to leverage these tools for exploring and preserving our cultural and historical legacies. This paper serves as an intriguing example of how these cutting-edge techniques can be applied to shed new light on the spatial dimensions of our shared stories and experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Exploring Spatial Representations in the Historical Lake District Texts with LLM-based Relation Extraction
Erum Haris, Anthony G. Cohn, John G. Stell
Navigating historical narratives poses a challenge in unveiling the spatial intricacies of past landscapes. The proposed work addresses this challenge within the context of the English Lake District, employing the Corpus of the Lake District Writing. The method utilizes a generative pre-trained transformer model to extract spatial relations from the textual descriptions in the corpus. The study applies this large language model to understand the spatial dimensions inherent in historical narratives comprehensively. The outcomes are presented as semantic triples, capturing the nuanced connections between entities and locations, and visualized as a network, offering a graphical representation of the spatial narrative. The study contributes to a deeper comprehension of the English Lake District's spatial tapestry and provides an approach to uncovering spatial relations within diverse historical contexts.
Read more6/21/2024
🤔
0
Evaluating Spatial Understanding of Large Language Models
Yutaro Yamada, Yihan Bao, Andrew K. Lampinen, Jungo Kasai, Ilker Yildirim
Large language models (LLMs) show remarkable capabilities across a variety of tasks. Despite the models only seeing text in training, several recent studies suggest that LLM representations implicitly capture aspects of the underlying grounded concepts. Here, we explore LLM representations of a particularly salient kind of grounded knowledge -- spatial relationships. We design natural-language navigation tasks and evaluate the ability of LLMs, in particular GPT-3.5-turbo, GPT-4, and Llama2 series models, to represent and reason about spatial structures. These tasks reveal substantial variability in LLM performance across different spatial structures, including square, hexagonal, and triangular grids, rings, and trees. In extensive error analysis, we find that LLMs' mistakes reflect both spatial and non-spatial factors. These findings suggest that LLMs appear to capture certain aspects of spatial structure implicitly, but room for improvement remains.
Read more4/16/2024
💬
0
Distortions in Judged Spatial Relations in Large Language Models
Nir Fulman, Abdulkadir Memduhou{g}lu, Alexander Zipf
We present a benchmark for assessing the capability of Large Language Models (LLMs) to discern intercardinal directions between geographic locations and apply it to three prominent LLMs: GPT-3.5, GPT-4, and Llama-2. This benchmark specifically evaluates whether LLMs exhibit a hierarchical spatial bias similar to humans, where judgments about individual locations' spatial relationships are influenced by the perceived relationships of the larger groups that contain them. To investigate this, we formulated 14 questions focusing on well-known American cities. Seven questions were designed to challenge the LLMs with scenarios potentially influenced by the orientation of larger geographical units, such as states or countries, while the remaining seven targeted locations were less susceptible to such hierarchical categorization. Among the tested models, GPT-4 exhibited superior performance with 55 percent accuracy, followed by GPT-3.5 at 47 percent, and Llama-2 at 45 percent. The models showed significantly reduced accuracy on tasks with suspected hierarchical bias. For example, GPT-4's accuracy dropped to 33 percent on these tasks, compared to 86 percent on others. However, the models identified the nearest cardinal direction in most cases, reflecting their associative learning mechanism, thereby embodying human-like misconceptions. We discuss avenues for improving the spatial reasoning capabilities of LLMs.
Read more6/5/2024
⛏️
0
RE$^2$: Region-Aware Relation Extraction from Visually Rich Documents
Pritika Ramu, Sijia Wang, Lalla Mouatadid, Joy Rimchala, Lifu Huang
Current research in form understanding predominantly relies on large pre-trained language models, necessitating extensive data for pre-training. However, the importance of layout structure (i.e., the spatial relationship between the entity blocks in the visually rich document) to relation extraction has been overlooked. In this paper, we propose REgion-Aware Relation Extraction (RE$^2$) that leverages region-level spatial structure among the entity blocks to improve their relation prediction. We design an edge-aware graph attention network to learn the interaction between entities while considering their spatial relationship defined by their region-level representations. We also introduce a constraint objective to regularize the model towards consistency with the inherent constraints of the relation extraction task. Extensive experiments across various datasets, languages and domains demonstrate the superiority of our proposed approach.
Read more6/5/2024