Locating and Extracting Relational Concepts in Large Language Models

0

Sign in to get full access
Overview
- This paper explores methods for locating and extracting relational concepts from large language models (LLMs)
- The authors propose techniques to identify and extract meaningful relationships between concepts within the vast knowledge stored in LLMs
- Their approach aims to make the inner workings of LLMs more interpretable and unlock the full potential of these powerful models
Plain English Explanation
Large language models (LLMs) like GPT-3 and BERT have access to an enormous amount of information, allowing them to perform impressive language tasks. However, the complex inner workings of these models can be difficult to understand. This research presents methods to locate and extract the specific relationships and connections between different concepts stored within LLMs.
The key idea is to identify meaningful "relational concepts" - how different ideas, entities, and facts are related to each other. By surfacing these interconnections, the model becomes more transparent and its knowledge can be better leveraged for applications like improving recall in LLMs or disambiguating entity matching. The techniques can also shed light on how an LLM's knowledge and representations evolve over time.
Overall, this research takes a step towards opening up the "black box" of LLMs and enabling more transparency and control over these powerful models.
Technical Explanation
The core of the authors' approach is to first identify key "anchor" concepts within the LLM, then explore the network of related concepts surrounding each anchor. They leverage various techniques like concept extraction, concept clustering, and concept embedding to systematically locate and extract meaningful relational concepts.
The process begins by defining a set of important "anchor" concepts that serve as starting points for the analysis. The model then investigates the web of related concepts, associations, and attributes linked to each anchor, surfacing the key relational concepts that connect them.
Advanced language model analysis is used to extract, group, and contextualize these relational concepts. The authors experiment with different concept representation methods, including concept-based models and latent representations, to identify the most effective approach.
Through extensive experimentation on various LLM architectures, the researchers demonstrate the efficacy of their techniques in locating and extracting meaningful relational knowledge from these complex models. The extracted concepts and relationships can then be leveraged to enhance model interpretability, enable more targeted knowledge extraction, and unlock new applications.
Critical Analysis
The authors acknowledge several limitations and avenues for future work. One key challenge is ensuring the extracted relational concepts are truly meaningful and reflect genuine semantic connections, rather than simply statistical correlations. More research is needed to develop robust methods for distinguishing meaningful conceptual relationships from spurious associations.
Additionally, the proposed techniques are computationally intensive, requiring significant resources to analyze the vast knowledge stored in large language models. Scaling these methods to handle extremely large models and knowledge bases remains an open challenge.
There are also open questions around the broader implications of making LLM knowledge more transparent and accessible. While increased interpretability is valuable, care must be taken to avoid potential misuse or misunderstanding of the extracted relational concepts, especially in high-stakes applications.
Overall, this research represents an important step forward in our understanding of large language models and our ability to harness their immense knowledge. However, continued innovation and careful consideration of the ethical implications will be crucial as this field of study progresses.
Conclusion
This paper introduces novel techniques for locating and extracting the rich relational concepts embedded within large language models. By surfacing the complex web of connections between different ideas and entities, the authors aim to make these powerful models more interpretable and their knowledge more accessible.
The proposed methods demonstrate the ability to systematically uncover meaningful conceptual relationships, which can enhance model transparency, enable more targeted knowledge extraction, and unlock new applications. As LLMs continue to grow in scale and capability, this research represents an important step towards unlocking their full potential while ensuring responsible development and deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Locating and Extracting Relational Concepts in Large Language Models
Zijian Wang, Britney White, Chang Xu
Relational concepts are indeed foundational to the structure of knowledge representation, as they facilitate the association between various entity concepts, allowing us to express and comprehend complex world knowledge. By expressing relational concepts in natural language prompts, people can effortlessly interact with large language models (LLMs) and recall desired factual knowledge. However, the process of knowledge recall lacks interpretability, and representations of relational concepts within LLMs remain unknown to us. In this paper, we identify hidden states that can express entity and relational concepts through causal mediation analysis in fact recall processes. Our finding reveals that at the last token position of the input prompt, there are hidden states that solely express the causal effects of relational concepts. Based on this finding, we assume that these hidden states can be treated as relational representations and we can successfully extract them from LLMs. The experimental results demonstrate high credibility of the relational representations: they can be flexibly transplanted into other fact recall processes, and can also be used as robust entity connectors. Moreover, we also show that the relational representations exhibit significant potential for controllable fact recall through relation rewriting.
Read more6/21/2024

0
Does Knowledge Localization Hold True? Surprising Differences Between Entity and Relation Perspectives in Language Models
Yifan Wei, Xiaoyan Yu, Yixuan Weng, Huanhuan Ma, Yuanzhe Zhang, Jun Zhao, Kang Liu
Large language models encapsulate knowledge and have demonstrated superior performance on various natural language processing tasks. Recent studies have localized this knowledge to specific model parameters, such as the MLP weights in intermediate layers. This study investigates the differences between entity and relational knowledge through knowledge editing. Our findings reveal that entity and relational knowledge cannot be directly transferred or mapped to each other. This result is unexpected, as logically, modifying the entity or the relation within the same knowledge triplet should yield equivalent outcomes. To further elucidate the differences between entity and relational knowledge, we employ causal analysis to investigate how relational knowledge is stored in pre-trained models. Contrary to prior research suggesting that knowledge is stored in MLP weights, our experiments demonstrate that relational knowledge is also significantly encoded in attention modules. This insight highlights the multifaceted nature of knowledge storage in language models, underscoring the complexity of manipulating specific types of knowledge within these models.
Read more9/4/2024

0
Concept Formation and Alignment in Language Models: Bridging Statistical Patterns in Latent Space to Concept Taxonomy
Mehrdad Khatir, Chandan K. Reddy
This paper explores the concept formation and alignment within the realm of language models (LMs). We propose a mechanism for identifying concepts and their hierarchical organization within the semantic representations learned by various LMs, encompassing a spectrum from early models like Glove to the transformer-based language models like ALBERT and T5. Our approach leverages the inherent structure present in the semantic embeddings generated by these models to extract a taxonomy of concepts and their hierarchical relationships. This investigation sheds light on how LMs develop conceptual understanding and opens doors to further research to improve their ability to reason and leverage real-world knowledge. We further conducted experiments and observed the possibility of isolating these extracted conceptual representations from the reasoning modules of the transformer-based LMs. The observed concept formation along with the isolation of conceptual representations from the reasoning modules can enable targeted token engineering to open the door for potential applications in knowledge transfer, explainable AI, and the development of more modular and conceptually grounded language models.
Read more6/11/2024
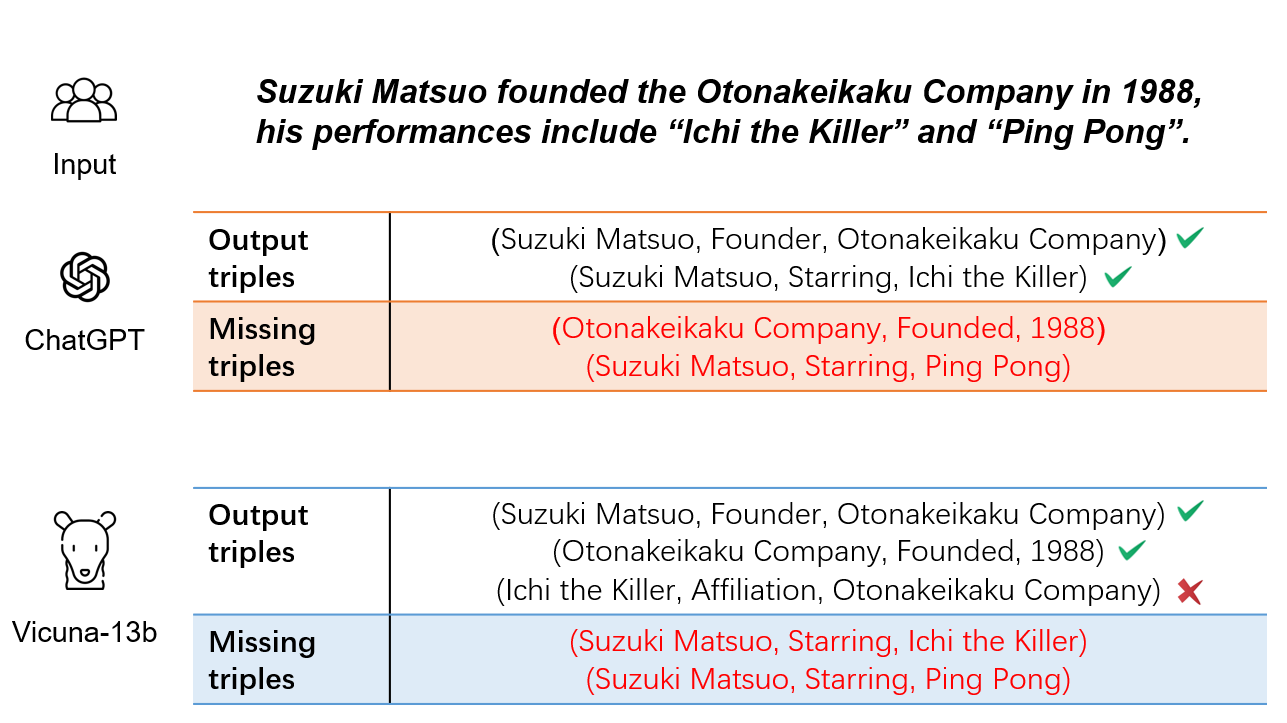
0
Improving Recall of Large Language Models: A Model Collaboration Approach for Relational Triple Extraction
Zepeng Ding, Wenhao Huang, Jiaqing Liang, Deqing Yang, Yanghua Xiao
Relation triple extraction, which outputs a set of triples from long sentences, plays a vital role in knowledge acquisition. Large language models can accurately extract triples from simple sentences through few-shot learning or fine-tuning when given appropriate instructions. However, they often miss out when extracting from complex sentences. In this paper, we design an evaluation-filtering framework that integrates large language models with small models for relational triple extraction tasks. The framework includes an evaluation model that can extract related entity pairs with high precision. We propose a simple labeling principle and a deep neural network to build the model, embedding the outputs as prompts into the extraction process of the large model. We conduct extensive experiments to demonstrate that the proposed method can assist large language models in obtaining more accurate extraction results, especially from complex sentences containing multiple relational triples. Our evaluation model can also be embedded into traditional extraction models to enhance their extraction precision from complex sentences.
Read more4/16/2024