Exploring Transferability of Multimodal Adversarial Samples for Vision-Language Pre-training Models with Contrastive Learning

0
🤯
Sign in to get full access
Overview
- This paper explores the adversarial robustness of Vision-Language Pre-training (VLP) models, which integrate visual and textual data to enhance vision-language understanding.
- The researchers introduce a novel gradient-based multimodal adversarial attack method that generates adversarial texts and images within imperceptible perturbations, using both image-text and intra-modal contrastive loss.
- The method aims to improve the transferability of multimodal adversarial samples in VLP models.
Plain English Explanation
The paper focuses on vision-language pre-training models, which are AI systems that learn to understand the relationship between images and text. These models are essential for tasks like image-text retrieval and visual entailment.
However, the researchers found that these models are vulnerable to adversarial attacks, where small, imperceptible changes to the input can cause the model to make mistakes. This is a significant problem, as it means these models could be easily fooled in real-world applications.
To address this issue, the researchers developed a new method to generate adversarial examples that can "trick" the vision-language models. Their approach generates adversarial texts and images simultaneously, using a technique called "contrastive learning" to ensure the adversarial samples are effective across different tasks.
The researchers evaluated their method on publicly available datasets and found that it outperformed existing adversarial attack methods, making the vision-language models more vulnerable to attack. This research is an important step in understanding the limitations of these models and developing strategies to make them more robust and reliable.
Technical Explanation
The paper introduces a novel gradient-based multimodal adversarial attack method to improve the transferability of adversarial samples in VLP models. The key elements of the approach are:
-
Contrastive Learning: The method employs both image-text and intra-modal contrastive loss to generate adversarial texts and images concurrently. This ensures the adversarial samples are effective across different modalities.
-
Gradient-based Attack: The attack is gradient-based, which means it uses the gradients of the model's loss function to identify the most effective perturbations to the input.
-
Multimodal Attack: The approach generates adversarial samples for both images and text, within imperceptible perturbation bounds, to attack the VLP model's alignment of image-text features.
The researchers evaluate their method in a black-box setting, using publicly available datasets for image-text retrieval and visual entailment tasks. Extensive experiments show that their approach significantly outperforms existing single-modal transfer-based adversarial attack methods, as well as current multimodal adversarial attack approaches.
Critical Analysis
The paper provides a comprehensive evaluation of the proposed multimodal adversarial attack method, demonstrating its effectiveness in undermining the performance of VLP models. However, the researchers acknowledge that their approach is limited to a black-box setting, and it would be valuable to explore the transferability of the adversarial samples across different VLP models and architectures.
Additionally, while the paper highlights the importance of adversarial robustness in VLP models, it does not discuss potential defenses or mitigation strategies that could be employed to make these models more resilient to such attacks. Exploring countermeasures and their impact on model performance would be a valuable extension of this research.
Conclusion
This paper presents a novel gradient-based multimodal adversarial attack method that significantly improves the transferability of adversarial samples in VLP models. By using contrastive learning to generate concurrent adversarial texts and images, the researchers have developed a powerful tool for exposing the vulnerabilities of these models.
The findings of this study underscore the critical need for enhanced adversarial robustness in vision-language understanding systems, as they are increasingly being deployed in real-world applications. The insights from this research can inform the development of more robust and reliable VLP models, ultimately leading to more trustworthy and secure AI-powered solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
0
Exploring Transferability of Multimodal Adversarial Samples for Vision-Language Pre-training Models with Contrastive Learning
Youze Wang, Wenbo Hu, Yinpeng Dong, Hanwang Zhang, Hang Su, Richang Hong
The integration of visual and textual data in Vision-Language Pre-training (VLP) models is crucial for enhancing vision-language understanding. However, the adversarial robustness of these models, especially in the alignment of image-text features, has not yet been sufficiently explored. In this paper, we introduce a novel gradient-based multimodal adversarial attack method, underpinned by contrastive learning, to improve the transferability of multimodal adversarial samples in VLP models. This method concurrently generates adversarial texts and images within imperceptive perturbation, employing both image-text and intra-modal contrastive loss. We evaluate the effectiveness of our approach on image-text retrieval and visual entailment tasks, using publicly available datasets in a black-box setting. Extensive experiments indicate a significant advancement over existing single-modal transfer-based adversarial attack methods and current multimodal adversarial attack approaches.
Read more7/23/2024

0
Improving Adversarial Transferability of Vision-Language Pre-training Models through Collaborative Multimodal Interaction
Jiyuan Fu, Zhaoyu Chen, Kaixun Jiang, Haijing Guo, Jiafeng Wang, Shuyong Gao, Wenqiang Zhang
Despite the substantial advancements in Vision-Language Pre-training (VLP) models, their susceptibility to adversarial attacks poses a significant challenge. Existing work rarely studies the transferability of attacks on VLP models, resulting in a substantial performance gap from white-box attacks. We observe that prior work overlooks the interaction mechanisms between modalities, which plays a crucial role in understanding the intricacies of VLP models. In response, we propose a novel attack, called Collaborative Multimodal Interaction Attack (CMI-Attack), leveraging modality interaction through embedding guidance and interaction enhancement. Specifically, attacking text at the embedding level while preserving semantics, as well as utilizing interaction image gradients to enhance constraints on perturbations of texts and images. Significantly, in the image-text retrieval task on Flickr30K dataset, CMI-Attack raises the transfer success rates from ALBEF to TCL, $text{CLIP}_{text{ViT}}$ and $text{CLIP}_{text{CNN}}$ by 8.11%-16.75% over state-of-the-art methods. Moreover, CMI-Attack also demonstrates superior performance in cross-task generalization scenarios. Our work addresses the underexplored realm of transfer attacks on VLP models, shedding light on the importance of modality interaction for enhanced adversarial robustness.
Read more7/9/2024
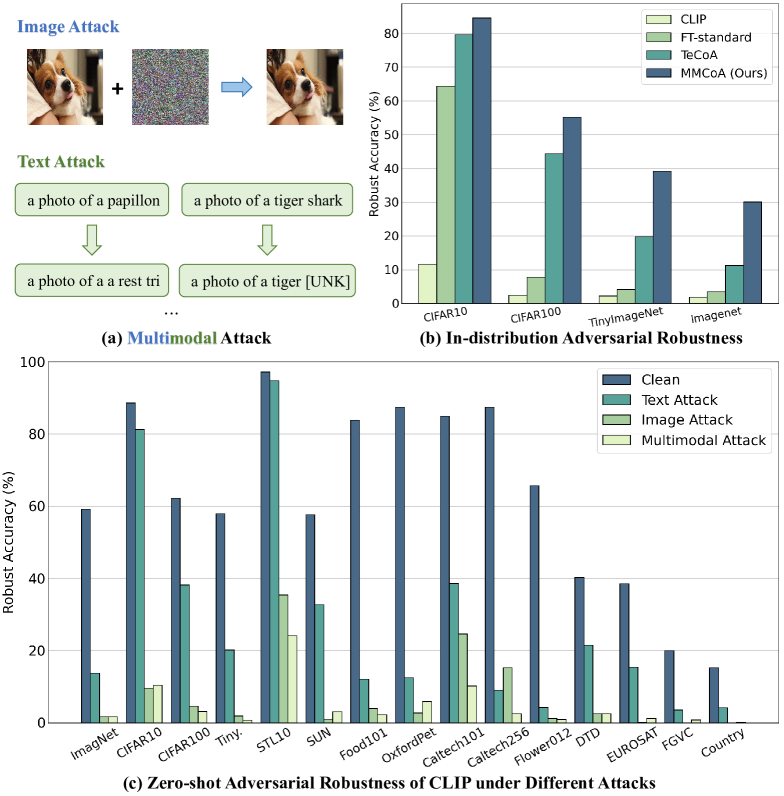
0
Revisiting the Adversarial Robustness of Vision Language Models: a Multimodal Perspective
Wanqi Zhou, Shuanghao Bai, Qibin Zhao, Badong Chen
Pretrained vision-language models (VLMs) like CLIP have shown impressive generalization performance across various downstream tasks, yet they remain vulnerable to adversarial attacks. While prior research has primarily concentrated on improving the adversarial robustness of image encoders to guard against attacks on images, the exploration of text-based and multimodal attacks has largely been overlooked. In this work, we initiate the first known and comprehensive effort to study adapting vision-language models for adversarial robustness under the multimodal attack. Firstly, we introduce a multimodal attack strategy and investigate the impact of different attacks. We then propose a multimodal contrastive adversarial training loss, aligning the clean and adversarial text embeddings with the adversarial and clean visual features, to enhance the adversarial robustness of both image and text encoders of CLIP. Extensive experiments on 15 datasets across two tasks demonstrate that our method significantly improves the adversarial robustness of CLIP. Interestingly, we find that the model fine-tuned against multimodal adversarial attacks exhibits greater robustness than its counterpart fine-tuned solely against image-based attacks, even in the context of image attacks, which may open up new possibilities for enhancing the security of VLMs.
Read more7/18/2024

0
Probing the Robustness of Vision-Language Pretrained Models: A Multimodal Adversarial Attack Approach
Jiwei Guan, Tianyu Ding, Longbing Cao, Lei Pan, Chen Wang, Xi Zheng
Vision-language pretraining (VLP) with transformers has demonstrated exceptional performance across numerous multimodal tasks. However, the adversarial robustness of these models has not been thoroughly investigated. Existing multimodal attack methods have largely overlooked cross-modal interactions between visual and textual modalities, particularly in the context of cross-attention mechanisms. In this paper, we study the adversarial vulnerability of recent VLP transformers and design a novel Joint Multimodal Transformer Feature Attack (JMTFA) that concurrently introduces adversarial perturbations in both visual and textual modalities under white-box settings. JMTFA strategically targets attention relevance scores to disrupt important features within each modality, generating adversarial samples by fusing perturbations and leading to erroneous model predictions. Experimental results indicate that the proposed approach achieves high attack success rates on vision-language understanding and reasoning downstream tasks compared to existing baselines. Notably, our findings reveal that the textual modality significantly influences the complex fusion processes within VLP transformers. Moreover, we observe no apparent relationship between model size and adversarial robustness under our proposed attacks. These insights emphasize a new dimension of adversarial robustness and underscore potential risks in the reliable deployment of multimodal AI systems.
Read more8/27/2024