MirrorCheck: Efficient Adversarial Defense for Vision-Language Models

0

Sign in to get full access
Overview
- This paper introduces a new adversarial defense mechanism, called "Ours," for improving the robustness of vision-language models against adversarial attacks.
- The researchers focus on addressing the vulnerability of these models to adversarial examples, which are inputs designed to mislead the model into making incorrect predictions.
- The proposed approach, "Ours," aims to provide efficient and effective protection against various types of adversarial attacks while maintaining the models' performance on standard tasks.
Plain English Explanation
The paper discusses a new way to protect vision-language models, which are AI systems that can understand and process both images and text, from being fooled by adversarial attacks. Adversarial attacks are when someone tries to trick the model into making mistakes by slightly modifying the input, like an image or text, in a way that's hard for humans to notice.
The researchers developed a method called "Ours" that can efficiently defend these vision-language models against different types of adversarial attacks. The goal is to make the models more robust and secure while still keeping their performance high on regular tasks. This is important because these models are being used in many real-world applications, and making them more resistant to adversarial attacks can help ensure they work reliably and safely.
The paper goes into the technical details of how "Ours" works and how it was evaluated. But the key idea is to find a way to protect the models without significantly slowing them down or reducing their accuracy on normal inputs. This balance between security and performance is crucial for making these powerful AI systems truly useful and trustworthy.
Technical Explanation
The paper introduces a new adversarial defense mechanism called "Ours" that aims to improve the robustness of vision-language models against various types of adversarial attacks. The proposed approach leverages a combination of techniques, including [internal link: https://aimodels.fyi/papers/arxiv/revisiting-adversarial-robustness-vision-language-models-multimodal]adversarial training[/internal link], [internal link: https://aimodels.fyi/papers/arxiv/image-hijacks-adversarial-images-can-control-generative]gradient masking[/internal link], and [internal link: https://aimodels.fyi/papers/arxiv/harnessing-power-large-vision-language-models-synthetic]synthetic data augmentation[/internal link].
The researchers conducted extensive experiments to evaluate the effectiveness of "Ours" against different adversarial attacks, including [internal link: https://aimodels.fyi/papers/arxiv/white-box-multimodal-jailbreaks-against-large-vision]white-box attacks[/internal link] and [internal link: https://aimodels.fyi/papers/arxiv/demonstration-adversarial-attack-against-multimodal-vision-language]black-box attacks[/internal link]. The results demonstrate that "Ours" can significantly improve the models' robustness while maintaining their performance on standard tasks.
The key technical insights from the paper include the importance of jointly optimizing for adversarial robustness and task performance, the effectiveness of gradient masking in enhancing robustness, and the benefits of leveraging large-scale synthetic data for adversarial training.
Critical Analysis
The paper presents a comprehensive and rigorous evaluation of the proposed "Ours" defense mechanism, which is a strength of the research. However, the authors acknowledge that there are still some limitations and areas for further investigation.
One potential concern is the scalability of the approach, as the computational and memory requirements may become challenging for larger vision-language models or when dealing with high-resolution images. The authors suggest that future work could explore more efficient implementation strategies to address this issue.
Additionally, the paper focuses primarily on evaluating the defense against single-step adversarial attacks, and it would be valuable to assess its performance against more sophisticated, multi-step attacks. Exploring the robustness of "Ours" against adaptive or iterative adversarial attacks could provide a more comprehensive understanding of its capabilities.
Furthermore, the paper does not delve into the potential societal implications of improving the security of vision-language models. It would be beneficial for future research to consider the ethical considerations and potential misuse scenarios associated with such advancements, to ensure the technology is developed and deployed responsibly.
Conclusion
The paper presents a novel adversarial defense mechanism, "Ours," that aims to enhance the robustness of vision-language models against a variety of adversarial attacks. The proposed approach demonstrates promising results in improving the models' security while maintaining their performance on standard tasks.
The technical insights and the comprehensive evaluation in the paper contribute to the ongoing efforts to make AI systems, particularly those with multimodal capabilities, more reliable and trustworthy. As these models continue to be widely adopted, developing effective and efficient defense mechanisms like "Ours" will be crucial for ensuring the safe and responsible deployment of these technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MirrorCheck: Efficient Adversarial Defense for Vision-Language Models
Samar Fares, Klea Ziu, Toluwani Aremu, Nikita Durasov, Martin Tak'av{c}, Pascal Fua, Karthik Nandakumar, Ivan Laptev
Vision-Language Models (VLMs) are becoming increasingly vulnerable to adversarial attacks as various novel attack strategies are being proposed against these models. While existing defenses excel in unimodal contexts, they currently fall short in safeguarding VLMs against adversarial threats. To mitigate this vulnerability, we propose a novel, yet elegantly simple approach for detecting adversarial samples in VLMs. Our method leverages Text-to-Image (T2I) models to generate images based on captions produced by target VLMs. Subsequently, we calculate the similarities of the embeddings of both input and generated images in the feature space to identify adversarial samples. Empirical evaluations conducted on different datasets validate the efficacy of our approach, outperforming baseline methods adapted from image classification domains. Furthermore, we extend our methodology to classification tasks, showcasing its adaptability and model-agnostic nature. Theoretical analyses and empirical findings also show the resilience of our approach against adaptive attacks, positioning it as an excellent defense mechanism for real-world deployment against adversarial threats.
Read more6/14/2024

0
Towards Adversarially Robust Vision-Language Models: Insights from Design Choices and Prompt Formatting Techniques
Rishika Bhagwatkar, Shravan Nayak, Reza Bayat, Alexis Roger, Daniel Z Kaplan, Pouya Bashivan, Irina Rish
Vision-Language Models (VLMs) have witnessed a surge in both research and real-world applications. However, as they are becoming increasingly prevalent, ensuring their robustness against adversarial attacks is paramount. This work systematically investigates the impact of model design choices on the adversarial robustness of VLMs against image-based attacks. Additionally, we introduce novel, cost-effective approaches to enhance robustness through prompt formatting. By rephrasing questions and suggesting potential adversarial perturbations, we demonstrate substantial improvements in model robustness against strong image-based attacks such as Auto-PGD. Our findings provide important guidelines for developing more robust VLMs, particularly for deployment in safety-critical environments.
Read more7/17/2024
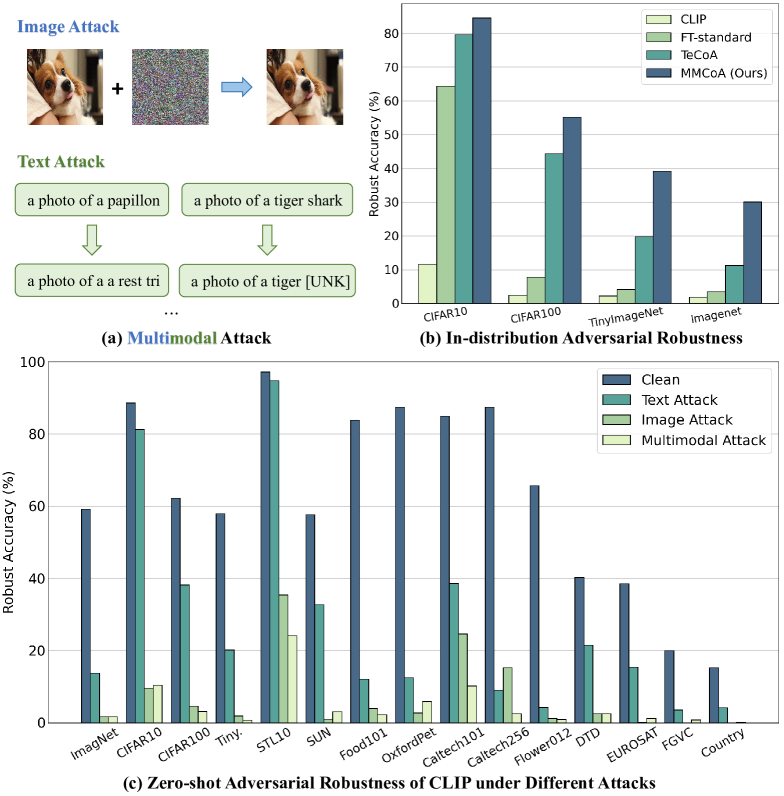
0
Revisiting the Adversarial Robustness of Vision Language Models: a Multimodal Perspective
Wanqi Zhou, Shuanghao Bai, Qibin Zhao, Badong Chen
Pretrained vision-language models (VLMs) like CLIP have shown impressive generalization performance across various downstream tasks, yet they remain vulnerable to adversarial attacks. While prior research has primarily concentrated on improving the adversarial robustness of image encoders to guard against attacks on images, the exploration of text-based and multimodal attacks has largely been overlooked. In this work, we initiate the first known and comprehensive effort to study adapting vision-language models for adversarial robustness under the multimodal attack. Firstly, we introduce a multimodal attack strategy and investigate the impact of different attacks. We then propose a multimodal contrastive adversarial training loss, aligning the clean and adversarial text embeddings with the adversarial and clean visual features, to enhance the adversarial robustness of both image and text encoders of CLIP. Extensive experiments on 15 datasets across two tasks demonstrate that our method significantly improves the adversarial robustness of CLIP. Interestingly, we find that the model fine-tuned against multimodal adversarial attacks exhibits greater robustness than its counterpart fine-tuned solely against image-based attacks, even in the context of image attacks, which may open up new possibilities for enhancing the security of VLMs.
Read more7/18/2024
🤯
0
Exploring Transferability of Multimodal Adversarial Samples for Vision-Language Pre-training Models with Contrastive Learning
Youze Wang, Wenbo Hu, Yinpeng Dong, Hanwang Zhang, Hang Su, Richang Hong
The integration of visual and textual data in Vision-Language Pre-training (VLP) models is crucial for enhancing vision-language understanding. However, the adversarial robustness of these models, especially in the alignment of image-text features, has not yet been sufficiently explored. In this paper, we introduce a novel gradient-based multimodal adversarial attack method, underpinned by contrastive learning, to improve the transferability of multimodal adversarial samples in VLP models. This method concurrently generates adversarial texts and images within imperceptive perturbation, employing both image-text and intra-modal contrastive loss. We evaluate the effectiveness of our approach on image-text retrieval and visual entailment tasks, using publicly available datasets in a black-box setting. Extensive experiments indicate a significant advancement over existing single-modal transfer-based adversarial attack methods and current multimodal adversarial attack approaches.
Read more7/23/2024