Expressivity of Neural Networks with Random Weights and Learned Biases

0
Sign in to get full access
Overview
- This paper investigates the expressivity of neural networks with random weights and learned biases.
- The authors explore how the choice of activation function and network architecture can affect the network's ability to represent a wide range of functions.
- They provide theoretical analysis and empirical results to better understand the capabilities and limitations of this type of neural network.
Plain English Explanation
Neural networks are powerful machine learning models that can learn to perform a wide variety of tasks, from image recognition to language understanding. At the heart of a neural network are the individual neurons, which take in inputs, perform some computation, and produce an output.
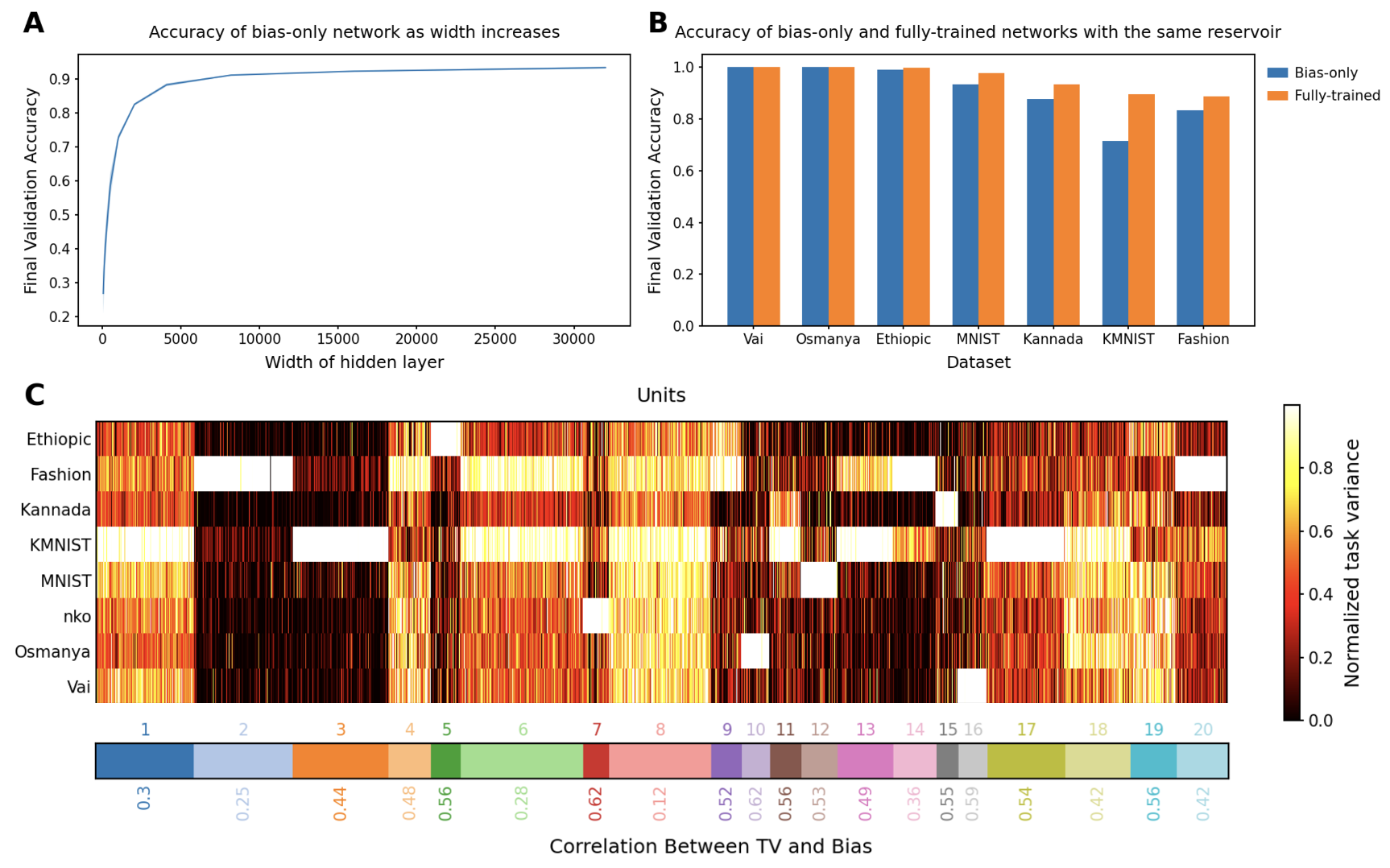
In this paper, the researchers look at a specific type of neural network where the weights (the connections between neurons) are randomly initialized and fixed, while the biases (which determine the activation thresholds of the neurons) are the only parameters that are learned during training. This is an interesting setup because it means the network doesn't have the same level of flexibility as a typical neural network, where all the weights and biases are learned.
The key question the researchers explore is: How expressive can these "random weight" neural networks be? In other words, what kinds of functions can they represent, and how do the choice of activation function and network architecture affect their capabilities?
Through a combination of theoretical analysis and experiments, the researchers find that the expressivity of these networks can be quite high, but it depends on factors like the type of activation function used. For example, networks with ReLU activations tend to be more expressive than networks with sigmoid activations.
The researchers also explore how the depth (number of layers) and width (number of neurons per layer) of the network can impact its expressivity. This is an important consideration, as the design of the network architecture can significantly affect the types of functions it can represent.
Overall, this research provides valuable insights into the capabilities and limitations of neural networks with random weights and learned biases, which could have important implications for the design and deployment of these types of models in real-world applications.
Technical Explanation
The paper investigates the expressivity of neural networks with randomly initialized weights and learned biases. The authors analyze how the choice of activation function and network architecture can affect the network's ability to represent a wide range of functions.
The key elements of the research are:
-
Theoretical Analysis: The authors provide a theoretical framework for analyzing the expressivity of neural networks with random weights and learned biases. This includes examining the role of the activation function and network depth and width.
-
Empirical Experiments: The researchers conduct a series of experiments to validate their theoretical findings. They train neural networks with different activation functions, depths, and widths, and evaluate their ability to fit various target functions.
-
Insights and Limitations: The paper offers several insights into the capabilities and limitations of neural networks with random weights. For example, they find that ReLU-based networks tend to be more expressive than sigmoid-based networks, and that deeper networks can be more expressive than shallower ones.
-
Potential Implications: The researchers discuss how their findings could inform the design of neural network architectures and the use of these types of models in real-world applications, such as visual bias mitigation or tiny network spotting.
Overall, this research provides a deeper understanding of the approximation power and limitations of neural networks with random weights and learned biases, which could have important implications for the design and deployment of these types of models.
Critical Analysis
The paper offers a thorough analysis of the expressivity of neural networks with random weights and learned biases, and the authors make a compelling case for the importance of this line of research. However, there are a few potential limitations and areas for further exploration:
-
Scope of Activation Functions: The paper primarily focuses on ReLU and sigmoid activations, but there may be other activation functions that could exhibit different expressivity characteristics. Expanding the analysis to a wider range of activation functions could provide even deeper insights.
-
Generalization to Real-World Tasks: While the theoretical and empirical analysis in the paper is rigorous, it's unclear how well the findings would translate to more complex, real-world machine learning tasks. Further research may be needed to understand the practical implications of these insights.
-
Comparison to Fully Learned Networks: The paper compares the expressivity of random weight networks to theoretical bounds, but a direct comparison to fully learned neural networks could provide additional context and perspective.
-
[object Object]: The potential applications of this research, such as in visual bias mitigation, are briefly mentioned but not explored in depth. Further investigation into these use cases could be valuable.
Overall, the paper makes a significant contribution to our understanding of neural network expressivity, but there are still opportunities for further research and exploration in this area.
Conclusion
This paper provides a detailed investigation into the expressivity of neural networks with random weights and learned biases. The researchers offer both theoretical analysis and empirical evidence to better understand how the choice of activation function and network architecture can impact the network's ability to represent a wide range of functions.
The key findings suggest that these "random weight" neural networks can be quite expressive, but their capabilities depend on factors like the activation function and the depth and width of the network. This research could have important implications for the design and deployment of neural network models, particularly in applications where tiny network spotting or visual bias mitigation are critical.
Overall, this work contributes to our broader understanding of neural network approximation power and expressivity, and opens up new avenues for future research in this important area of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Expressivity of Neural Networks with Random Weights and Learned Biases
Ezekiel Williams, Avery Hee-Woon Ryoo, Thomas Jiralerspong, Alexandre Payeur, Matthew G. Perich, Luca Mazzucatto, Guillaume Lajoie
Landmark universal function approximation results for neural networks with trained weights and biases provided impetus for the ubiquitous use of neural networks as learning models in Artificial Intelligence (AI) and neuroscience. Recent work has pushed the bounds of universal approximation by showing that arbitrary functions can similarly be learned by tuning smaller subsets of parameters, for example the output weights, within randomly initialized networks. Motivated by the fact that biases can be interpreted as biologically plausible mechanisms for adjusting unit outputs in neural networks, such as tonic inputs or activation thresholds, we investigate the expressivity of neural networks with random weights where only biases are optimized. We provide theoretical and numerical evidence demonstrating that feedforward neural networks with fixed random weights can be trained to perform multiple tasks by learning biases only. We further show that an equivalent result holds for recurrent neural networks predicting dynamical system trajectories. Our results are relevant to neuroscience, where they demonstrate the potential for behaviourally relevant changes in dynamics without modifying synaptic weights, as well as for AI, where they shed light on multi-task methods such as bias fine-tuning and unit masking.
Read more7/2/2024
📈
0
Random Vector Functional Link Networks for Function Approximation on Manifolds
Deanna Needell, Aaron A. Nelson, Rayan Saab, Palina Salanevich, Olov Schavemaker
The learning speed of feed-forward neural networks is notoriously slow and has presented a bottleneck in deep learning applications for several decades. For instance, gradient-based learning algorithms, which are used extensively to train neural networks, tend to work slowly when all of the network parameters must be iteratively tuned. To counter this, both researchers and practitioners have tried introducing randomness to reduce the learning requirement. Based on the original construction of Igelnik and Pao, single layer neural-networks with random input-to-hidden layer weights and biases have seen success in practice, but the necessary theoretical justification is lacking. In this paper, we begin to fill this theoretical gap. We provide a (corrected) rigorous proof that the Igelnik and Pao construction is a universal approximator for continuous functions on compact domains, with approximation error decaying asymptotically like $O(1/sqrt{n})$ for the number $n$ of network nodes. We then extend this result to the non-asymptotic setting, proving that one can achieve any desired approximation error with high probability provided $n$ is sufficiently large. We further adapt this randomized neural network architecture to approximate functions on smooth, compact submanifolds of Euclidean space, providing theoretical guarantees in both the asymptotic and non-asymptotic forms. Finally, we illustrate our results on manifolds with numerical experiments.
Read more8/27/2024
🧠
0
ReLU Neural Networks with Linear Layers are Biased Towards Single- and Multi-Index Models
Suzanna Parkinson, Greg Ongie, Rebecca Willett
Neural networks often operate in the overparameterized regime, in which there are far more parameters than training samples, allowing the training data to be fit perfectly. That is, training the network effectively learns an interpolating function, and properties of the interpolant affect predictions the network will make on new samples. This manuscript explores how properties of such functions learned by neural networks of depth greater than two layers. Our framework considers a family of networks of varying depths that all have the same capacity but different representation costs. The representation cost of a function induced by a neural network architecture is the minimum sum of squared weights needed for the network to represent the function; it reflects the function space bias associated with the architecture. Our results show that adding additional linear layers to the input side of a shallow ReLU network yields a representation cost favoring functions with low mixed variation - that is, it has limited variation in directions orthogonal to a low-dimensional subspace and can be well approximated by a single- or multi-index model. Such functions may be represented by the composition of a function with low two-layer representation cost and a low-rank linear operator. Our experiments confirm this behavior in standard network training regimes. They additionally show that linear layers can improve generalization and the learned network is well-aligned with the true latent low-dimensional linear subspace when data is generated using a multi-index model.
Read more6/27/2024

0
Neural Networks Trained by Weight Permutation are Universal Approximators
Yongqiang Cai, Gaohang Chen, Zhonghua Qiao
The universal approximation property is fundamental to the success of neural networks, and has traditionally been achieved by training networks without any constraints on their parameters. However, recent experimental research proposed a novel permutation-based training method, which exhibited a desired classification performance without modifying the exact weight values. In this paper, we provide a theoretical guarantee of this permutation training method by proving its ability to guide a ReLU network to approximate one-dimensional continuous functions. Our numerical results further validate this method's efficiency in regression tasks with various initializations. The notable observations during weight permutation suggest that permutation training can provide an innovative tool for describing network learning behavior.
Read more7/2/2024