Neural Networks Trained by Weight Permutation are Universal Approximators

0

Sign in to get full access
Overview
- Neural networks with randomly initialized weights and learned biases can serve as universal approximators, meaning they can approximate any continuous function.
- The paper investigates the expressive power of neural networks with random weights and learned biases, providing theoretical and empirical insights.
- Key findings suggest that these types of neural networks can achieve high accuracy on a variety of tasks, even with low-precision weights and biases.
Plain English Explanation
Neural networks are a type of artificial intelligence that can be trained to perform all sorts of tasks, from image recognition to language translation. One interesting property of neural networks is their ability to approximate any continuous function, which means they can learn to mimic the behavior of any mathematical function.
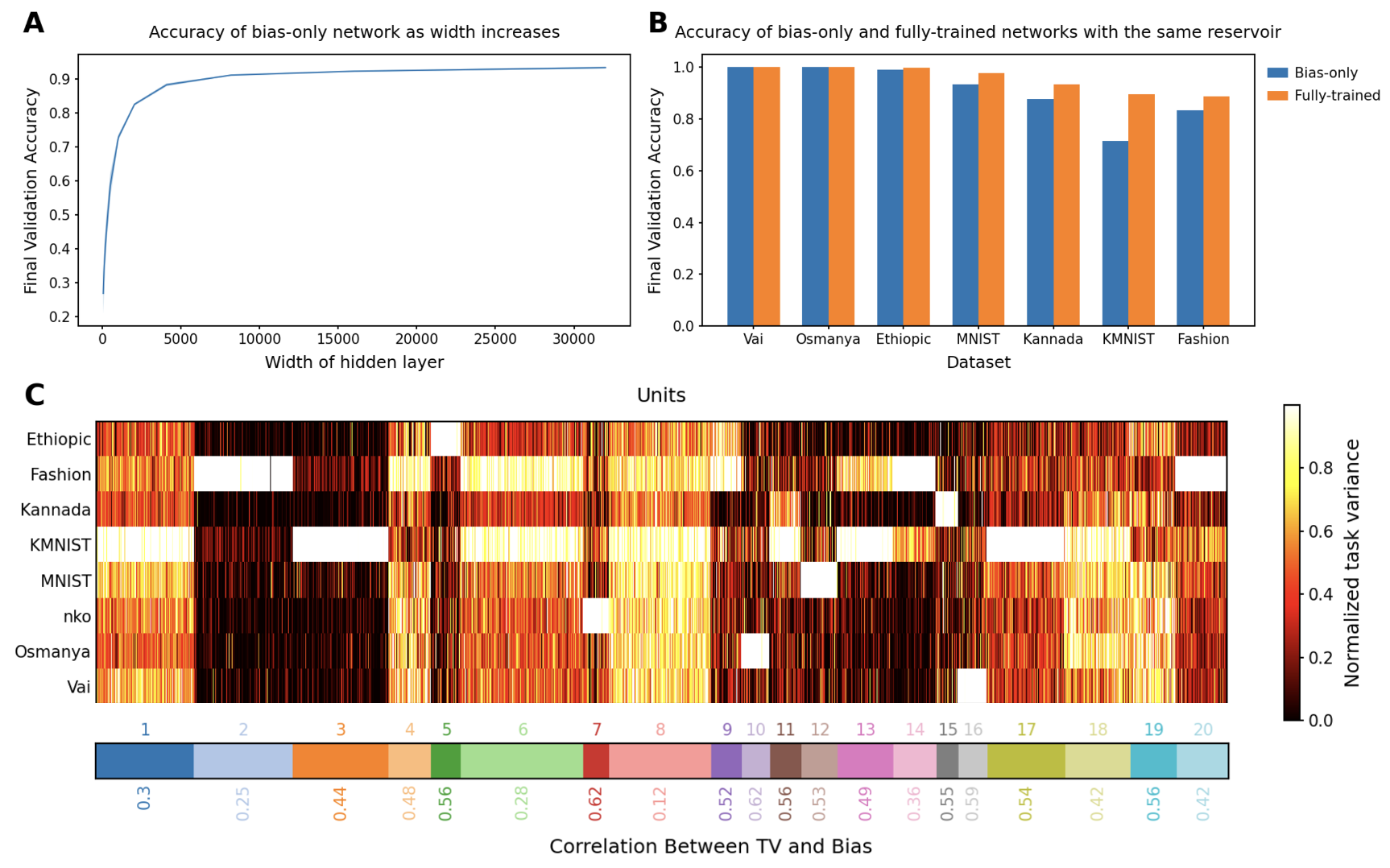
In this paper, the researchers looked at a particular type of neural network where the weights (the numbers that determine how the different parts of the network are connected) are randomly set, and only the biases (the numbers that determine how each part of the network activates) are learned during training. Surprisingly, they found that these neural networks with random weights and learned biases can still act as universal approximators, just like more complex neural networks.
One of the key insights is that these simple neural networks can achieve high accuracy on a variety of tasks, even when the weights and biases are represented using low-precision numbers. This is important because it means that these types of neural networks could potentially be implemented more efficiently in hardware, like on smartphones or other devices with limited computing power.
Overall, the research provides a better understanding of the expressive power of neural networks and suggests that even relatively simple architectures can be powerful tools for solving complex problems.
Technical Explanation
The paper investigates the expressive power of neural networks with randomly initialized weights and learned biases, demonstrating that they can serve as universal approximators. The authors provide theoretical and empirical analyses to support this claim.
Theoretically, the paper establishes bounds on the approximation error of neural networks with random weights and learned biases, showing that they can approximate any continuous function to arbitrary precision. The analysis relies on the properties of random matrices and the universality of certain activation functions, such as the ReLU.
Empirically, the authors evaluate the performance of neural networks with random weights and learned biases on a variety of tasks, including image classification, regression, and function approximation. The results demonstrate that these simple neural networks can achieve high accuracy, even when using low-precision representations for the weights and biases.
The paper also explores the relationship between the network architecture, the number of parameters, and the approximation accuracy. The authors show that the expressive power of these neural networks scales with the number of hidden units, and that they can achieve good parameter efficiency compared to more complex architectures.
Critical Analysis
The paper provides a solid theoretical and empirical foundation for the expressive power of neural networks with random weights and learned biases. The authors' analysis of the approximation error bounds and the empirical evaluation on various tasks are well-designed and convincing.
One potential limitation of the research is the focus on simple feed-forward neural networks. While the authors demonstrate the universality of this architecture, it would be interesting to see if similar results hold for more complex neural network architectures, such as convolutional or recurrent neural networks.
Additionally, the paper does not explore the training dynamics of these neural networks in depth. It would be useful to investigate the convergence properties of the learning algorithm and the potential implications for practical applications.
Overall, the research provides valuable insights into the expressive power of neural networks and highlights the potential benefits of using simple architectures with random weights and learned biases. Further exploration of the limitations and real-world applicability of these findings could lead to advancements in efficient neural network design and implementation.
Conclusion
This paper presents an important contribution to the understanding of neural network expressivity. The key finding that neural networks with randomly initialized weights and learned biases can act as universal approximators, even with low-precision representations, has significant implications for the design and deployment of efficient AI systems.
The theoretical and empirical analyses demonstrate the remarkable capabilities of these simple neural network architectures, suggesting that they could be a viable alternative to more complex models in certain applications. This could lead to the development of more parameter-efficient and computationally-efficient neural network-based solutions, with potential benefits for edge computing, embedded systems, and resource-constrained environments.
Overall, the findings in this paper contribute to the ongoing efforts to understand the expressivity and limitations of neural networks, which is crucial for advancing the field of artificial intelligence and realizing its full potential.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Neural Networks Trained by Weight Permutation are Universal Approximators
Yongqiang Cai, Gaohang Chen, Zhonghua Qiao
The universal approximation property is fundamental to the success of neural networks, and has traditionally been achieved by training networks without any constraints on their parameters. However, recent experimental research proposed a novel permutation-based training method, which exhibited a desired classification performance without modifying the exact weight values. In this paper, we provide a theoretical guarantee of this permutation training method by proving its ability to guide a ReLU network to approximate one-dimensional continuous functions. Our numerical results further validate this method's efficiency in regression tasks with various initializations. The notable observations during weight permutation suggest that permutation training can provide an innovative tool for describing network learning behavior.
Read more7/2/2024
0
Expressivity of Neural Networks with Random Weights and Learned Biases
Ezekiel Williams, Avery Hee-Woon Ryoo, Thomas Jiralerspong, Alexandre Payeur, Matthew G. Perich, Luca Mazzucatto, Guillaume Lajoie
Landmark universal function approximation results for neural networks with trained weights and biases provided impetus for the ubiquitous use of neural networks as learning models in Artificial Intelligence (AI) and neuroscience. Recent work has pushed the bounds of universal approximation by showing that arbitrary functions can similarly be learned by tuning smaller subsets of parameters, for example the output weights, within randomly initialized networks. Motivated by the fact that biases can be interpreted as biologically plausible mechanisms for adjusting unit outputs in neural networks, such as tonic inputs or activation thresholds, we investigate the expressivity of neural networks with random weights where only biases are optimized. We provide theoretical and numerical evidence demonstrating that feedforward neural networks with fixed random weights can be trained to perform multiple tasks by learning biases only. We further show that an equivalent result holds for recurrent neural networks predicting dynamical system trajectories. Our results are relevant to neuroscience, where they demonstrate the potential for behaviourally relevant changes in dynamics without modifying synaptic weights, as well as for AI, where they shed light on multi-task methods such as bias fine-tuning and unit masking.
Read more7/2/2024
🏋️
0
Approximation and Gradient Descent Training with Neural Networks
G. Welper
It is well understood that neural networks with carefully hand-picked weights provide powerful function approximation and that they can be successfully trained in over-parametrized regimes. Since over-parametrization ensures zero training error, these two theories are not immediately compatible. Recent work uses the smoothness that is required for approximation results to extend a neural tangent kernel (NTK) optimization argument to an under-parametrized regime and show direct approximation bounds for networks trained by gradient flow. Since gradient flow is only an idealization of a practical method, this paper establishes analogous results for networks trained by gradient descent.
Read more5/21/2024

0
Universal Approximation Theory: Foundations for Parallelism in Neural Networks
Wei Wang, Qing Li
Neural networks are increasingly evolving towards training large models with big data, a method that has demonstrated superior performance across many tasks. However, this approach introduces an urgent problem: current deep learning models are predominantly serial, meaning that as the number of network layers increases, so do the training and inference times. This is unacceptable if deep learning is to continue advancing. Therefore, this paper proposes a deep learning parallelization strategy based on the Universal Approximation Theorem (UAT). From this foundation, we designed a parallel network called Para-Former to test our theory. Unlike traditional serial models, the inference time of Para-Former does not increase with the number of layers, significantly accelerating the inference speed of multi-layer networks. Experimental results validate the effectiveness of this network.
Read more8/20/2024