Growing Tiny Networks: Spotting Expressivity Bottlenecks and Fixing Them Optimally

0
🔍
Sign in to get full access
Overview
- Machine learning tasks are formulated as optimization problems, where the goal is to find an optimal function within a certain functional space.
- Typically, a neural network architecture is chosen and its parameters (connection weights) are optimized, which restricts the evolution of the function during training to what is expressible with the chosen architecture.
- The authors propose a method to adapt the neural network architecture on the fly during training, using information extracted from backpropagation to detect and solve "expressivity bottlenecks."
- This allows them to start with small neural networks and have them grow appropriately, matching the accuracy of large neural networks while reducing the need for architectural hyperparameter search.
Plain English Explanation
In machine learning, the goal is often to find the best mathematical function that can solve a particular problem, such as recognizing images or translating text. Researchers have found that using a specific type of machine learning model called a neural network can be very effective for many tasks.
Typically, when training a neural network, the researchers choose a particular architecture (the number and arrangement of the network's "neurons") and then optimize the values of the connections between those neurons. This works well, but it also means the network can only learn functions that fit within the constraints of the chosen architecture. If the problem requires a more complex function, the researchers have to use a larger neural network, which can be computationally expensive and time-consuming to train.
The authors of this paper propose a new approach. Instead of sticking with a fixed architecture, they want the neural network to be able to adapt and change its own architecture during training. By analyzing the gradients (the information used to update the network during training), they can detect when the network is struggling to express the necessary function and automatically add new neurons where they are needed.
This allows the authors to start with a very simple neural network and let it grow in complexity as needed, rather than having to guess the right architecture ahead of time. They demonstrate this approach on a common image recognition task and show that it can match the performance of much larger, more complex neural networks while requiring less training time.
Technical Explanation
The authors propose a method to adapt the neural network architecture on the fly during training, using information extracted from backpropagation to detect and solve "expressivity bottlenecks." This is in contrast to the standard approach, where a fixed neural network architecture is chosen and its parameters (connection weights) are optimized.
The key idea is to define a mathematical formulation of "expressivity bottlenecks" - points during training where the current neural network architecture is unable to effectively represent the necessary function. By analyzing the gradients computed during backpropagation, the authors can identify these bottlenecks and selectively add new neurons to the network, allowing it to grow in complexity as needed.
This builds on previous work on the "tropical expressivity" of neural networks, which provides a theoretical understanding of the representational capacity of different neural network architectures. The authors leverage these insights to dynamically adapt the architecture during training.
Additionally, the authors demonstrate their approach on the CIFAR image recognition dataset, showing that they can match the accuracy of large, complex neural networks while using a much simpler initial architecture and requiring less training time. This reduces the need for costly architectural hyperparameter optimization, which is often required when using fixed neural network architectures.
Critical Analysis
The authors present a compelling approach to dynamically adapting neural network architectures during training, which addresses a key limitation of the standard practice of using fixed architectures. By detecting and solving expressivity bottlenecks, the method allows neural networks to grow in complexity as needed, rather than requiring researchers to guess the right architecture ahead of time.
However, the authors do not provide a detailed analysis of the computational overhead introduced by their architecture adaptation process. Constantly monitoring for and adding new neurons could slow down training, particularly for large-scale problems. The authors should further investigate the trade-offs between the benefits of their approach and any potential computational costs.
Additionally, the authors' experiments are limited to the CIFAR dataset, which, while widely used, may not be representative of all types of machine learning problems. Further testing on a broader range of tasks, including more complex domains like natural language processing or reinforcement learning, would help validate the generalizability of the authors' approach.
Overall, the authors have presented an innovative technique that addresses an important challenge in neural network design. With further refinement and more extensive evaluation, this approach could have significant implications for reducing the manual effort required to configure and tune neural network architectures.
Conclusion
This paper proposes a novel method for dynamically adapting neural network architectures during training, using information extracted from backpropagation to detect and solve "expressivity bottlenecks." This allows the neural network to grow in complexity as needed, rather than being constrained by a fixed architecture chosen at the outset.
The authors demonstrate that their approach can match the performance of large, complex neural networks on an image recognition task, while using a much simpler initial architecture and requiring less training time. This reduces the need for costly architectural hyperparameter optimization, which is often required when using fixed neural network designs.
Overall, this research represents an important step towards more flexible and adaptive neural network architectures, which could have significant implications for reducing the manual effort required to configure and tune machine learning models. With further development and evaluation, this technique could become a valuable tool in the machine learning practitioner's toolkit.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔍
0
Growing Tiny Networks: Spotting Expressivity Bottlenecks and Fixing Them Optimally
Manon Verbockhaven (TAU, LISN), Sylvain Chevallier (TAU, LISN), Guillaume Charpiat (TAU, LISN)
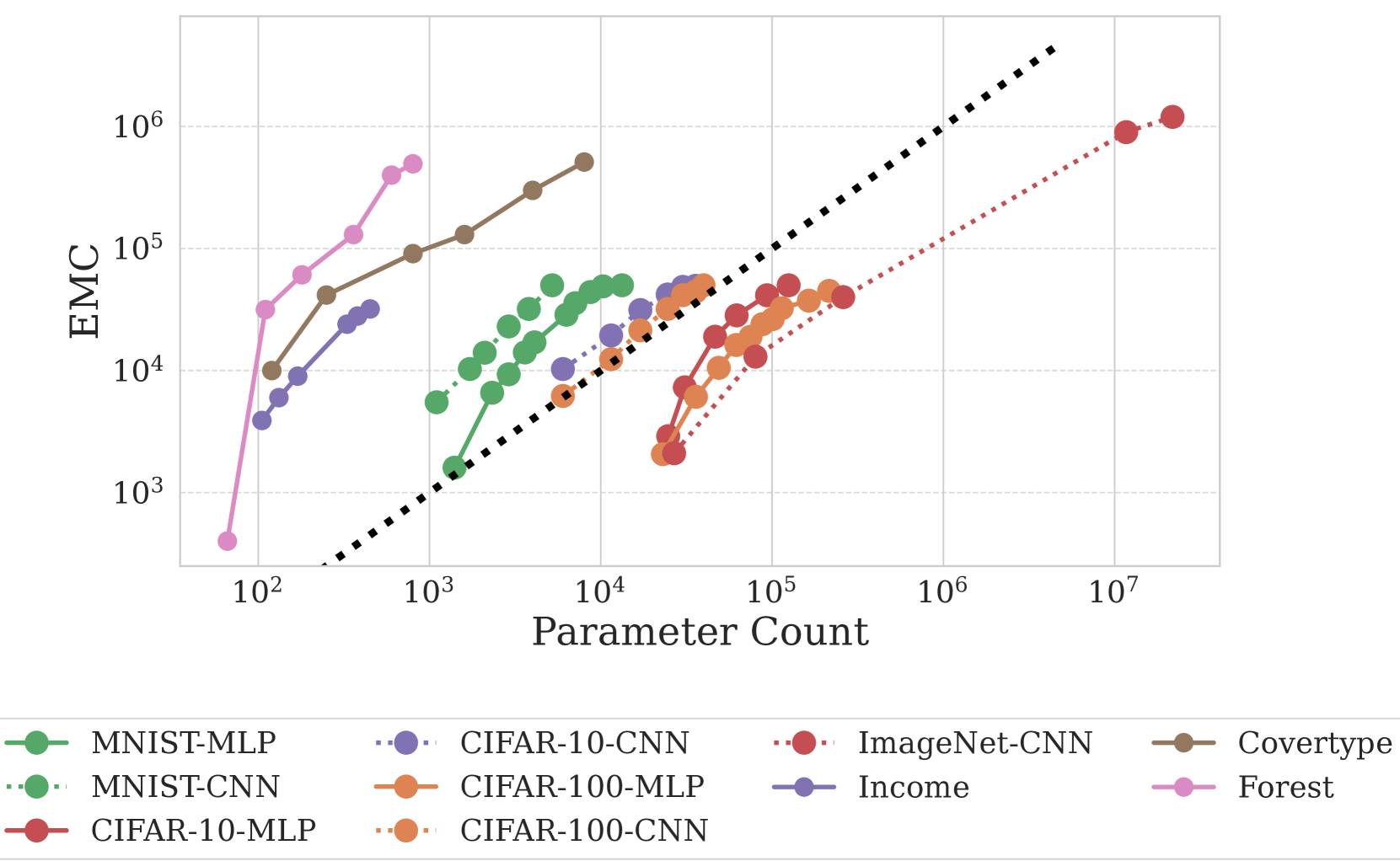
Machine learning tasks are generally formulated as optimization problems, where one searches for an optimal function within a certain functional space. In practice, parameterized functional spaces are considered, in order to be able to perform gradient descent. Typically, a neural network architecture is chosen and fixed, and its parameters (connection weights) are optimized, yielding an architecture-dependent result. This way of proceeding however forces the evolution of the function during training to lie within the realm of what is expressible with the chosen architecture, and prevents any optimization across architectures. Costly architectural hyper-parameter optimization is often performed to compensate for this. Instead, we propose to adapt the architecture on the fly during training. We show that the information about desirable architectural changes, due to expressivity bottlenecks when attempting to follow the functional gradient, can be extracted from %the backpropagation. To do this, we propose a mathematical definition of expressivity bottlenecks, which enables us to detect, quantify and solve them while training, by adding suitable neurons when and where needed. Thus, while the standard approach requires large networks, in terms of number of neurons per layer, for expressivity and optimization reasons, we are able to start with very small neural networks and let them grow appropriately. As a proof of concept, we show results~on the CIFAR dataset, matching large neural network accuracy, with competitive training time, while removing the need for standard architectural hyper-parameter search.
Read more5/31/2024
0
Expressivity of Neural Networks with Random Weights and Learned Biases
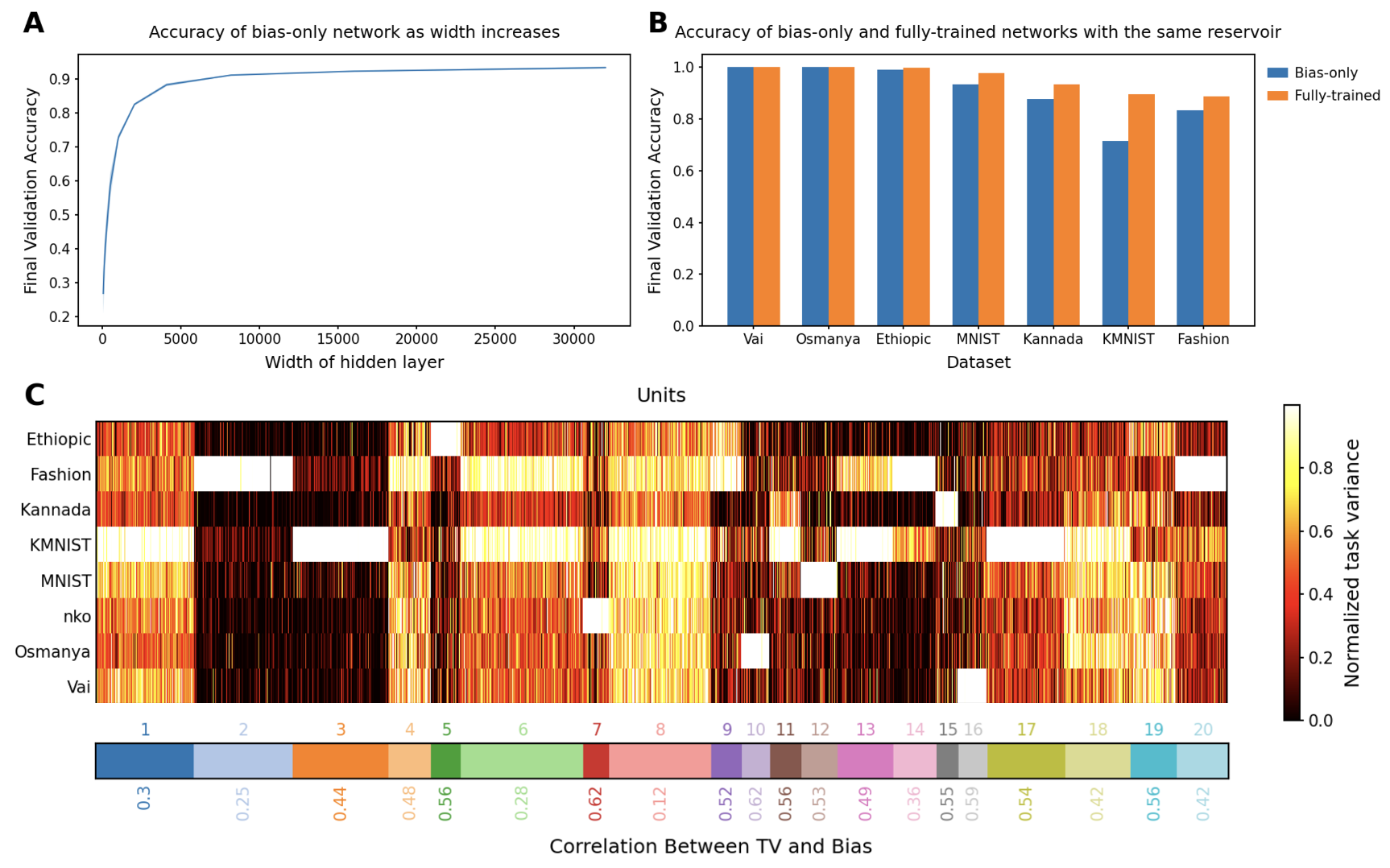
Ezekiel Williams, Avery Hee-Woon Ryoo, Thomas Jiralerspong, Alexandre Payeur, Matthew G. Perich, Luca Mazzucatto, Guillaume Lajoie
Landmark universal function approximation results for neural networks with trained weights and biases provided impetus for the ubiquitous use of neural networks as learning models in Artificial Intelligence (AI) and neuroscience. Recent work has pushed the bounds of universal approximation by showing that arbitrary functions can similarly be learned by tuning smaller subsets of parameters, for example the output weights, within randomly initialized networks. Motivated by the fact that biases can be interpreted as biologically plausible mechanisms for adjusting unit outputs in neural networks, such as tonic inputs or activation thresholds, we investigate the expressivity of neural networks with random weights where only biases are optimized. We provide theoretical and numerical evidence demonstrating that feedforward neural networks with fixed random weights can be trained to perform multiple tasks by learning biases only. We further show that an equivalent result holds for recurrent neural networks predicting dynamical system trajectories. Our results are relevant to neuroscience, where they demonstrate the potential for behaviourally relevant changes in dynamics without modifying synaptic weights, as well as for AI, where they shed light on multi-task methods such as bias fine-tuning and unit masking.
Read more7/2/2024
0
Just How Flexible are Neural Networks in Practice?
Ravid Shwartz-Ziv, Micah Goldblum, Arpit Bansal, C. Bayan Bruss, Yann LeCun, Andrew Gordon Wilson
It is widely believed that a neural network can fit a training set containing at least as many samples as it has parameters, underpinning notions of overparameterized and underparameterized models. In practice, however, we only find solutions accessible via our training procedure, including the optimizer and regularizers, limiting flexibility. Moreover, the exact parameterization of the function class, built into an architecture, shapes its loss surface and impacts the minima we find. In this work, we examine the ability of neural networks to fit data in practice. Our findings indicate that: (1) standard optimizers find minima where the model can only fit training sets with significantly fewer samples than it has parameters; (2) convolutional networks are more parameter-efficient than MLPs and ViTs, even on randomly labeled data; (3) while stochastic training is thought to have a regularizing effect, SGD actually finds minima that fit more training data than full-batch gradient descent; (4) the difference in capacity to fit correctly labeled and incorrectly labeled samples can be predictive of generalization; (5) ReLU activation functions result in finding minima that fit more data despite being designed to avoid vanishing and exploding gradients in deep architectures.
Read more6/18/2024

0
Tropical Expressivity of Neural Networks
Shiv Bhatia, Yueqi Cao, Paul Lezeau, Anthea Monod
We propose an algebraic geometric framework to study the expressivity of linear activation neural networks. A particular quantity that has been actively studied in the field of deep learning is the number of linear regions, which gives an estimate of the information capacity of the architecture. To study and evaluate information capacity and expressivity, we work in the setting of tropical geometry -- a combinatorial and polyhedral variant of algebraic geometry -- where there are known connections between tropical rational maps and feedforward neural networks. Our work builds on and expands this connection to capitalize on the rich theory of tropical geometry to characterize and study various architectural aspects of neural networks. Our contributions are threefold: we provide a novel tropical geometric approach to selecting sampling domains among linear regions; an algebraic result allowing for a guided restriction of the sampling domain for network architectures with symmetries; and an open source library to analyze neural networks as tropical Puiseux rational maps. We provide a comprehensive set of proof-of-concept numerical experiments demonstrating the breadth of neural network architectures to which tropical geometric theory can be applied to reveal insights on expressivity characteristics of a network. Our work provides the foundations for the adaptation of both theory and existing software from computational tropical geometry and symbolic computation to deep learning.
Read more5/31/2024