Audio-Visual Generalized Zero-Shot Learning using Pre-Trained Large Multi-Modal Models
2404.06309
0
0
Abstract
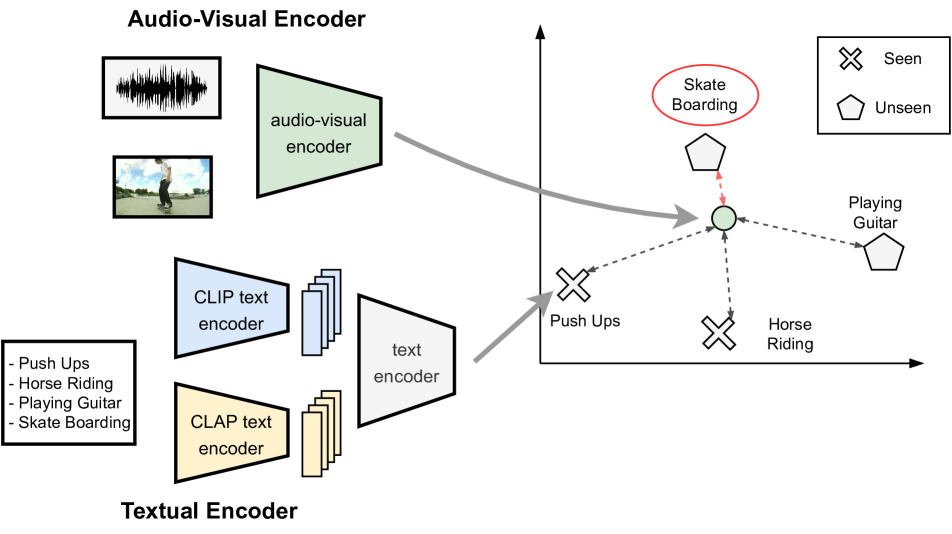
Audio-visual zero-shot learning methods commonly build on features extracted from pre-trained models, e.g. video or audio classification models. However, existing benchmarks predate the popularization of large multi-modal models, such as CLIP and CLAP. In this work, we explore such large pre-trained models to obtain features, i.e. CLIP for visual features, and CLAP for audio features. Furthermore, the CLIP and CLAP text encoders provide class label embeddings which are combined to boost the performance of the system. We propose a simple yet effective model that only relies on feed-forward neural networks, exploiting the strong generalization capabilities of the new audio, visual and textual features. Our framework achieves state-of-the-art performance on VGGSound-GZSL, UCF-GZSL, and ActivityNet-GZSL with our new features. Code and data available at: https://github.com/dkurzend/ClipClap-GZSL.
Create account to get full access
Overview
- This paper presents a novel approach for audio-visual generalized zero-shot learning (AV-GZSL) using pre-trained large multi-modal models.
- The proposed method aims to leverage the rich semantic and cross-modal knowledge captured by these pre-trained models to improve performance on the challenging AV-GZSL task.
- The paper also explores the role of different pre-training strategies and their impact on the final AV-GZSL performance.
Plain English Explanation
The paper focuses on a problem called "audio-visual generalized zero-shot learning" (AV-GZSL). This refers to the ability of AI systems to recognize objects or sounds that they haven't been explicitly trained on before, by using information from other related concepts they have learned.
The researchers in this study tried a new approach to solve this problem. They used large pre-trained models that have been trained on a huge amount of data to learn general knowledge about the world, including connections between different types of information like images, sounds, and text.
The idea is that these pre-trained models can capture rich semantic and cross-modal (combining different senses like vision and audio) knowledge, which can then be leveraged to improve the performance of AV-GZSL systems. The paper explores different ways of using these pre-trained models and investigates how the pre-training strategy affects the final AV-GZSL results.
Technical Explanation
The paper proposes a novel approach for audio-visual generalized zero-shot learning (AV-GZSL) using pre-trained large multi-modal models. The key idea is to leverage the rich semantic and cross-modal knowledge captured by these pre-trained models to enhance performance on the challenging AV-GZSL task.
The authors experiment with different pre-training strategies, including multi-stage multi-modal pre-training and data-efficient multi-modal fusion, and investigate their impact on the final AV-GZSL results. They also explore adapting vision-language models and using large language models as prompt learners for the AV-GZSL task.
The proposed approach is evaluated on standard AV-GZSL benchmarks, and the results demonstrate the effectiveness of leveraging pre-trained multi-modal models to improve performance on this task.
Critical Analysis
The paper presents a promising approach to addressing the challenging AV-GZSL problem by exploiting the knowledge captured in pre-trained multi-modal models. However, the authors acknowledge several limitations and areas for future research:
- The performance of the proposed method is still limited compared to human-level zero-shot learning abilities, suggesting that further advancements are needed.
- The paper focuses on a specific set of pre-training strategies and model architectures; exploring a wider range of pre-training techniques and model designs may yield additional insights.
- The paper does not delve into the interpretability of the learned cross-modal representations, which could provide valuable clues for understanding the underlying mechanisms of zero-shot learning.
Additionally, one could question the generalizability of the findings, as the experiments are conducted on a limited set of datasets and tasks. Further research is needed to validate the effectiveness of the proposed approach across a broader range of real-world applications and scenarios.
Conclusion
This paper presents a novel approach for audio-visual generalized zero-shot learning (AV-GZSL) that leverages the knowledge captured in pre-trained large multi-modal models. The proposed method aims to harness the rich semantic and cross-modal information learned by these models to enhance the performance of AV-GZSL systems.
The results demonstrate the potential of this approach, but also highlight the need for further advancements to close the gap between machine and human zero-shot learning abilities. Continued research in this direction, exploring a wider range of pre-training strategies and model architectures, could lead to significant improvements in the field of zero-shot and few-shot learning, with broad applications in various AI-powered systems and services.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Zero-Shot Audio Captioning Using Soft and Hard Prompts
Yiming Zhang, Xuenan Xu, Ruoyi Du, Haohe Liu, Yuan Dong, Zheng-Hua Tan, Wenwu Wang, Zhanyu Ma
0
0
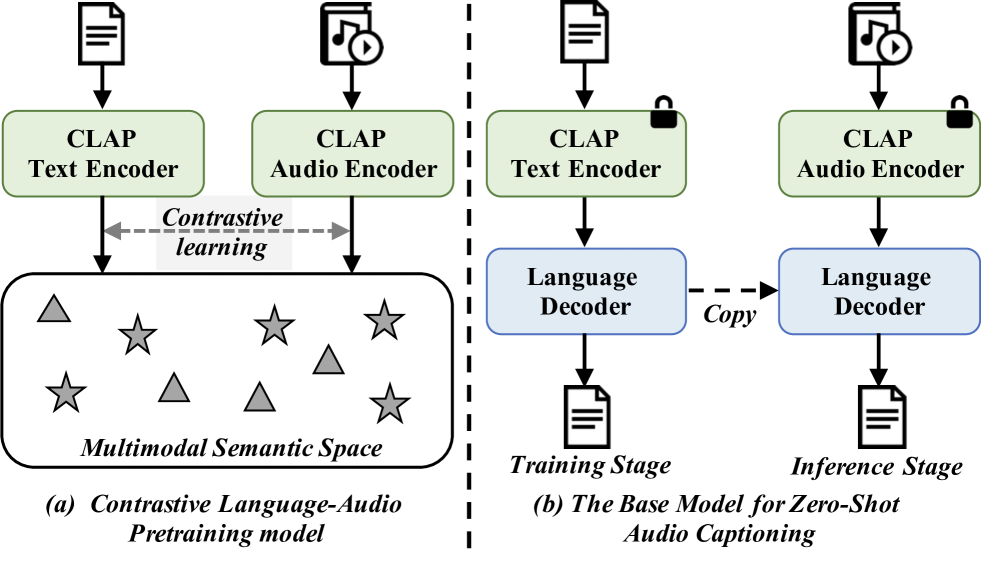
In traditional audio captioning methods, a model is usually trained in a fully supervised manner using a human-annotated dataset containing audio-text pairs and then evaluated on the test sets from the same dataset. Such methods have two limitations. First, these methods are often data-hungry and require time-consuming and expensive human annotations to obtain audio-text pairs. Second, these models often suffer from performance degradation in cross-domain scenarios, i.e., when the input audio comes from a different domain than the training set, which, however, has received little attention. We propose an effective audio captioning method based on the contrastive language-audio pre-training (CLAP) model to address these issues. Our proposed method requires only textual data for training, enabling the model to generate text from the textual feature in the cross-modal semantic space.In the inference stage, the model generates the descriptive text for the given audio from the audio feature by leveraging the audio-text alignment from CLAP.We devise two strategies to mitigate the discrepancy between text and audio embeddings: a mixed-augmentation-based soft prompt and a retrieval-based acoustic-aware hard prompt. These approaches are designed to enhance the generalization performance of our proposed model, facilitating the model to generate captions more robustly and accurately. Extensive experiments on AudioCaps and Clotho benchmarks show the effectiveness of our proposed method, which outperforms other zero-shot audio captioning approaches for in-domain scenarios and outperforms the compared methods for cross-domain scenarios, underscoring the generalization ability of our method.
6/11/2024

tinyCLAP: Distilling Constrastive Language-Audio Pretrained Models
Francesco Paissan, Elisabetta Farella
0
0
Contrastive Language-Audio Pretraining (CLAP) became of crucial importance in the field of audio and speech processing. Its employment ranges from sound event detection to text-to-audio generation. However, one of the main limitations is the considerable amount of data required in the training process and the overall computational complexity during inference. This paper investigates how we can reduce the complexity of contrastive language-audio pre-trained models, yielding an efficient model that we call tinyCLAP. We derive an unimodal distillation loss from first principles and explore how the dimensionality of the shared, multimodal latent space can be reduced via pruning. TinyCLAP uses only 6% of the original Microsoft CLAP parameters with a minimal reduction (less than 5%) in zero-shot classification performance across the three sound event detection datasets on which it was tested
6/13/2024
🛸
Cascade-CLIP: Cascaded Vision-Language Embeddings Alignment for Zero-Shot Semantic Segmentation
Yunheng Li, ZhongYu Li, Quansheng Zeng, Qibin Hou, Ming-Ming Cheng
0
0
Pre-trained vision-language models, e.g., CLIP, have been successfully applied to zero-shot semantic segmentation. Existing CLIP-based approaches primarily utilize visual features from the last layer to align with text embeddings, while they neglect the crucial information in intermediate layers that contain rich object details. However, we find that directly aggregating the multi-level visual features weakens the zero-shot ability for novel classes. The large differences between the visual features from different layers make these features hard to align well with the text embeddings. We resolve this problem by introducing a series of independent decoders to align the multi-level visual features with the text embeddings in a cascaded way, forming a novel but simple framework named Cascade-CLIP. Our Cascade-CLIP is flexible and can be easily applied to existing zero-shot semantic segmentation methods. Experimental results show that our simple Cascade-CLIP achieves superior zero-shot performance on segmentation benchmarks, like COCO-Stuff, Pascal-VOC, and Pascal-Context. Our code is available at: https://github.com/HVision-NKU/Cascade-CLIP
6/7/2024
Unified Video-Language Pre-training with Synchronized Audio
Shentong Mo, Haofan Wang, Huaxia Li, Xu Tang
0
0
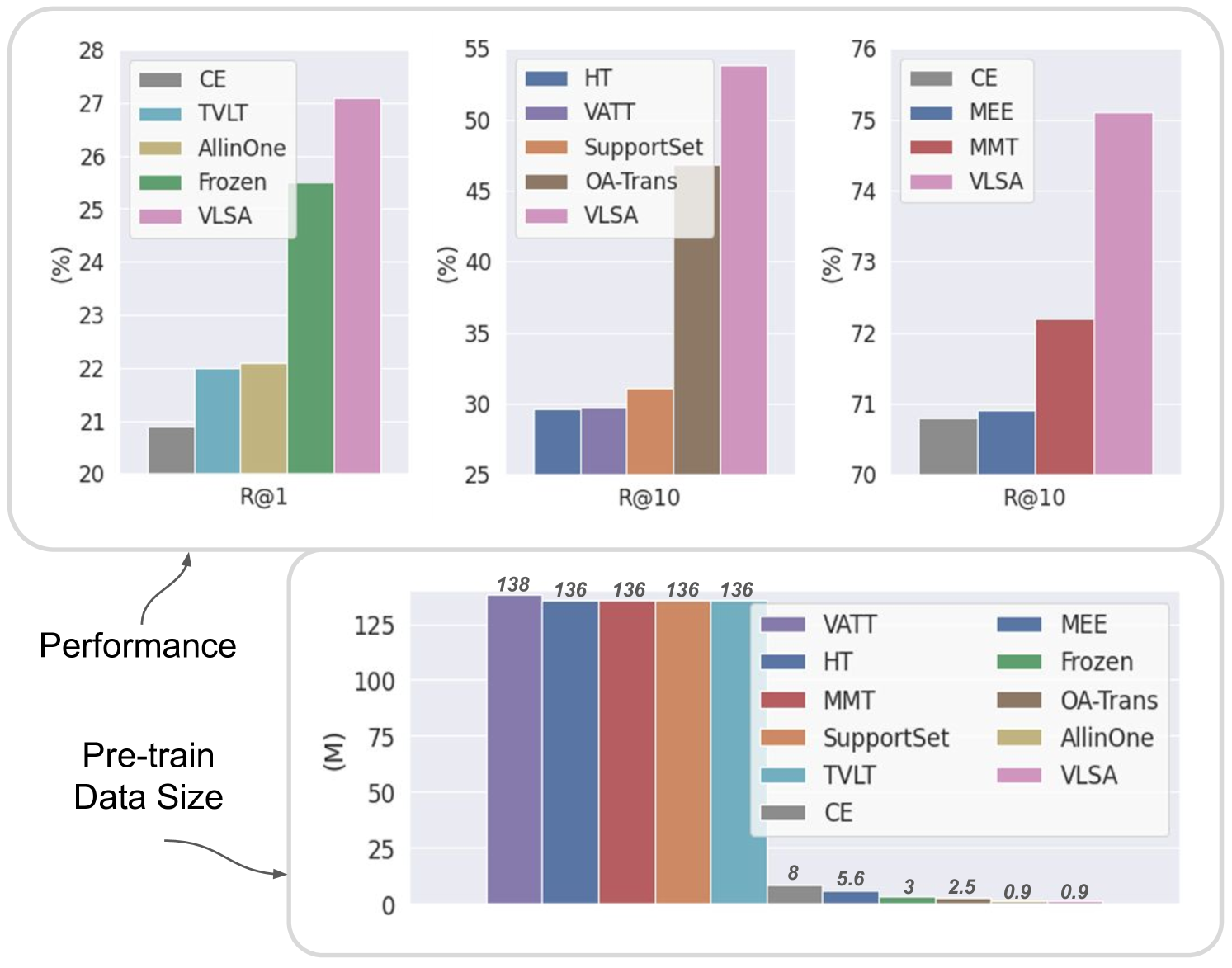
Video-language pre-training is a typical and challenging problem that aims at learning visual and textual representations from large-scale data in a self-supervised way. Existing pre-training approaches either captured the correspondence of image-text pairs or utilized temporal ordering of frames. However, they do not explicitly explore the natural synchronization between audio and the other two modalities. In this work, we propose an enhanced framework for Video-Language pre-training with Synchronized Audio, termed as VLSA, that can learn tri-modal representations in a unified self-supervised transformer. Specifically, our VLSA jointly aggregates embeddings of local patches and global tokens for video, text, and audio. Furthermore, we utilize local-patch masked modeling to learn modality-aware features, and leverage global audio matching to capture audio-guided features for video and text. We conduct extensive experiments on retrieval across text, video, and audio. Our simple model pre-trained on only 0.9M data achieves improving results against state-of-the-art baselines. In addition, qualitative visualizations vividly showcase the superiority of our VLSA in learning discriminative visual-textual representations.
5/14/2024