FaceFolds: Meshed Radiance Manifolds for Efficient Volumetric Rendering of Dynamic Faces
2404.13807
0
0
Abstract
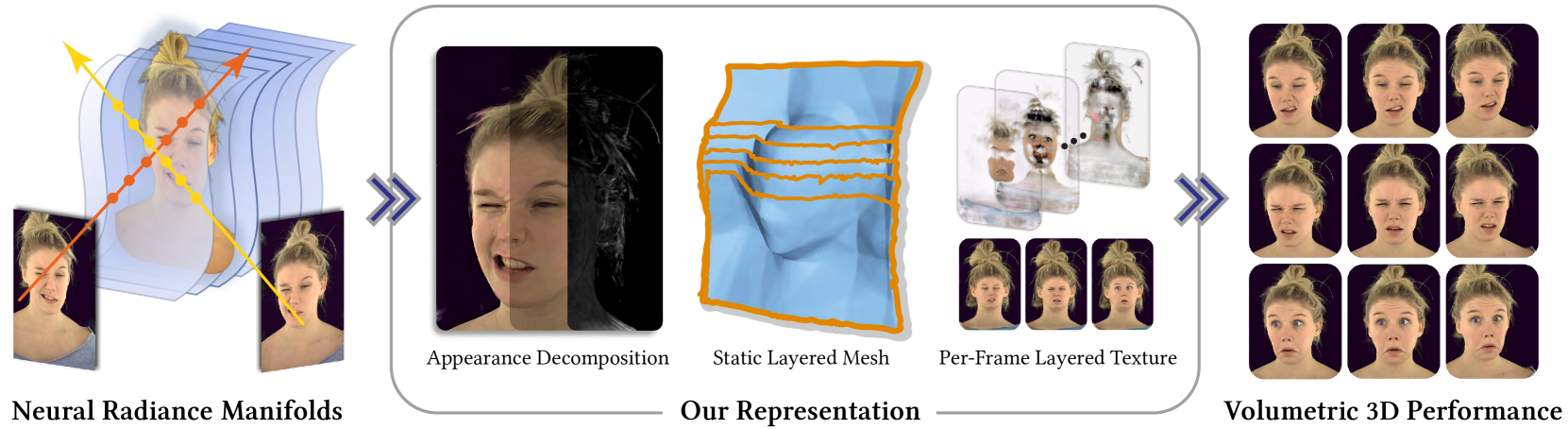
3D rendering of dynamic face captures is a challenging problem, and it demands improvements on several fronts$unicode{x2014}$photorealism, efficiency, compatibility, and configurability. We present a novel representation that enables high-quality volumetric rendering of an actor's dynamic facial performances with minimal compute and memory footprint. It runs natively on commodity graphics soft- and hardware, and allows for a graceful trade-off between quality and efficiency. Our method utilizes recent advances in neural rendering, particularly learning discrete radiance manifolds to sparsely sample the scene to model volumetric effects. We achieve efficient modeling by learning a single set of manifolds for the entire dynamic sequence, while implicitly modeling appearance changes as temporal canonical texture. We export a single layered mesh and view-independent RGBA texture video that is compatible with legacy graphics renderers without additional ML integration. We demonstrate our method by rendering dynamic face captures of real actors in a game engine, at comparable photorealism to state-of-the-art neural rendering techniques at previously unseen frame rates.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a method called FaceFolds for efficiently rendering dynamic faces in volumetric scenes.
- It introduces a novel representation called "meshed radiance manifolds" that captures the time-varying radiance of a face and enables fast rendering.
- The approach leverages neural radiance fields (NeRFs) and performance capture data to create a compact and high-fidelity 4D face model.
Plain English Explanation
The research in this paper aims to develop a better way to digitally render realistic, dynamic human faces in 3D scenes. Traditionally, creating lifelike animated faces has been challenging, as it requires a lot of computing power to simulate all the intricate details of facial movements and expressions.
The key innovation in this paper is a new technique called "FaceFolds" that uses a compact representation called "meshed radiance manifolds" to efficiently capture the changing appearance of a face over time. By combining neural radiance fields (link) and performance capture data, the researchers were able to create a high-quality 4D face model that can be rendered quickly, even in complex virtual environments.
This advance could have important applications in areas like video games, movies, and virtual reality, where realistic human faces are essential for creating immersive experiences. It also builds on previous work in efficient 3D head avatars and instantaneous 3D head reconstruction, further improving the ability to digitally recreate human faces.
Technical Explanation
The FaceFolds method starts by capturing high-quality 3D face scans and associated performance data using a specialized capture setup. This data is then used to train a neural radiance field (NeRF) model that can represent the time-varying appearance of the face.
To make this NeRF-based representation more efficient for rendering, the researchers introduce the concept of "meshed radiance manifolds". This involves fitting a deformable mesh to the face, with each vertex storing a radiance field that encodes the appearance of that local region over time. This allows the face to be rendered by efficiently sampling the radiance fields associated with the mesh vertices, rather than the entire NeRF volume.
Key innovations in the FaceFolds approach include:
- Using performance capture data to constrain and guide the NeRF training process, ensuring high fidelity
- Developing specialized mesh optimization and vertex radiance field encoding techniques to enable fast rendering
- Demonstrating state-of-the-art results in terms of rendering quality and speed, outperforming alternative NeRF-based face modeling approaches
The paper also explores extensions of the FaceFolds method, such as enabling 4D facial expression diffusion and creating generic, expression-aware volumetric head avatars.
Critical Analysis
The FaceFolds approach represents a significant advance in the field of realistic face rendering, addressing key challenges around efficiency and fidelity. By leveraging performance capture data and a novel meshed radiance manifold representation, the researchers were able to create a compact and high-quality 4D face model that can be rendered in real-time.
One potential limitation of the approach is that it relies on specialized capture hardware to obtain the initial 3D face scans and performance data. This could limit the accessibility of the technique for some applications or researchers without access to such specialized equipment.
Additionally, while the paper demonstrates impressive results on a range of face poses and expressions, it's unclear how well the method would generalize to a broader diversity of faces, including different ethnicities, ages, and facial features. Further testing and evaluation on more diverse datasets could help address this potential concern.
Overall, the FaceFolds method represents an exciting advancement in the field of volumetric face rendering, with the potential to enable more lifelike and immersive digital experiences in a wide range of applications.
Conclusion
The FaceFolds paper presents a novel approach for efficiently rendering dynamic human faces in volumetric scenes. By combining neural radiance fields and performance capture data, the researchers developed a compact "meshed radiance manifold" representation that enables high-fidelity face rendering at fast speeds.
This work builds on previous advances in face mesh modeling, 3D head avatar creation, and instant 3D head reconstruction, further pushing the boundaries of what is possible in terms of realistic digital facial animation.
The FaceFolds technique has the potential to significantly impact a wide range of applications, from video games and virtual reality experiences to digital cinematography and telepresence systems. As the field of human face modeling and rendering continues to evolve, innovations like this will be crucial for creating truly immersive and lifelike virtual environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Learning Topology Uniformed Face Mesh by Volume Rendering for Multi-view Reconstruction
Yating Wang, Ran Yi, Ke Fan, Jinkun Hao, Jiangbo Lu, Lizhuang Ma
0
0
Face meshes in consistent topology serve as the foundation for many face-related applications, such as 3DMM constrained face reconstruction and expression retargeting. Traditional methods commonly acquire topology uniformed face meshes by two separate steps: multi-view stereo (MVS) to reconstruct shapes followed by non-rigid registration to align topology, but struggles with handling noise and non-lambertian surfaces. Recently neural volume rendering techniques have been rapidly evolved and shown great advantages in 3D reconstruction or novel view synthesis. Our goal is to leverage the superiority of neural volume rendering into multi-view reconstruction of face mesh with consistent topology. We propose a mesh volume rendering method that enables directly optimizing mesh geometry while preserving topology, and learning implicit features to model complex facial appearance from multi-view images. The key innovation lies in spreading sparse mesh features into the surrounding space to simulate radiance field required for volume rendering, which facilitates backpropagation of gradients from images to mesh geometry and implicit appearance features. Our proposed feature spreading module exhibits deformation invariance, enabling photorealistic rendering seamlessly after mesh editing. We conduct experiments on multi-view face image dataset to evaluate the reconstruction and implement an application for photorealistic rendering of animated face mesh.
4/9/2024
Efficient 3D Implicit Head Avatar with Mesh-anchored Hash Table Blendshapes
Ziqian Bai, Feitong Tan, Sean Fanello, Rohit Pandey, Mingsong Dou, Shichen Liu, Ping Tan, Yinda Zhang
0
0
3D head avatars built with neural implicit volumetric representations have achieved unprecedented levels of photorealism. However, the computational cost of these methods remains a significant barrier to their widespread adoption, particularly in real-time applications such as virtual reality and teleconferencing. While attempts have been made to develop fast neural rendering approaches for static scenes, these methods cannot be simply employed to support realistic facial expressions, such as in the case of a dynamic facial performance. To address these challenges, we propose a novel fast 3D neural implicit head avatar model that achieves real-time rendering while maintaining fine-grained controllability and high rendering quality. Our key idea lies in the introduction of local hash table blendshapes, which are learned and attached to the vertices of an underlying face parametric model. These per-vertex hash-tables are linearly merged with weights predicted via a CNN, resulting in expression dependent embeddings. Our novel representation enables efficient density and color predictions using a lightweight MLP, which is further accelerated by a hierarchical nearest neighbor search method. Extensive experiments show that our approach runs in real-time while achieving comparable rendering quality to state-of-the-arts and decent results on challenging expressions.
4/3/2024
⚙️
3DFlowRenderer: One-shot Face Re-enactment via Dense 3D Facial Flow Estimation
Siddharth Nijhawan, Takuya Yashima, Tamaki Kojima
0
0
Performing facial expression transfer under one-shot setting has been increasing in popularity among research community with a focus on precise control of expressions. Existing techniques showcase compelling results in perceiving expressions, but they lack robustness with extreme head poses. They also struggle to accurately reconstruct background details, thus hindering the realism. In this paper, we propose a novel warping technology which integrates the advantages of both 2D and 3D methods to achieve robust face re-enactment. We generate dense 3D facial flow fields in feature space to warp an input image based on target expressions without depth information. This enables explicit 3D geometric control for re-enacting misaligned source and target faces. We regularize the motion estimation capability of the 3D flow prediction network through proposed Cyclic warp loss by converting warped 3D features back into 2D RGB space. To ensure the generation of finer facial region with natural-background, our framework only renders the facial foreground region first and learns to inpaint the blank area which needs to be filled due to source face translation, thus reconstructing the detailed background without any unwanted pixel motion. Extensive evaluation reveals that our method outperforms state-of-the-art techniques in rendering artifact-free facial images.
4/24/2024
🤷
InstantAvatar: Efficient 3D Head Reconstruction via Surface Rendering
Antonio Canela, Pol Caselles, Ibrar Malik, Eduard Ramon, Jaime Garc'ia, Jordi S'anchez-Riera, Gil Triginer, Francesc Moreno-Noguer
0
0
Recent advances in full-head reconstruction have been obtained by optimizing a neural field through differentiable surface or volume rendering to represent a single scene. While these techniques achieve an unprecedented accuracy, they take several minutes, or even hours, due to the expensive optimization process required. In this work, we introduce InstantAvatar, a method that recovers full-head avatars from few images (down to just one) in a few seconds on commodity hardware. In order to speed up the reconstruction process, we propose a system that combines, for the first time, a voxel-grid neural field representation with a surface renderer. Notably, a naive combination of these two techniques leads to unstable optimizations that do not converge to valid solutions. In order to overcome this limitation, we present a novel statistical model that learns a prior distribution over 3D head signed distance functions using a voxel-grid based architecture. The use of this prior model, in combination with other design choices, results into a system that achieves 3D head reconstructions with comparable accuracy as the state-of-the-art with a 100x speed-up.
4/8/2024