Learning Topology Uniformed Face Mesh by Volume Rendering for Multi-view Reconstruction
2404.05606
0
0

Abstract
Face meshes in consistent topology serve as the foundation for many face-related applications, such as 3DMM constrained face reconstruction and expression retargeting. Traditional methods commonly acquire topology uniformed face meshes by two separate steps: multi-view stereo (MVS) to reconstruct shapes followed by non-rigid registration to align topology, but struggles with handling noise and non-lambertian surfaces. Recently neural volume rendering techniques have been rapidly evolved and shown great advantages in 3D reconstruction or novel view synthesis. Our goal is to leverage the superiority of neural volume rendering into multi-view reconstruction of face mesh with consistent topology. We propose a mesh volume rendering method that enables directly optimizing mesh geometry while preserving topology, and learning implicit features to model complex facial appearance from multi-view images. The key innovation lies in spreading sparse mesh features into the surrounding space to simulate radiance field required for volume rendering, which facilitates backpropagation of gradients from images to mesh geometry and implicit appearance features. Our proposed feature spreading module exhibits deformation invariance, enabling photorealistic rendering seamlessly after mesh editing. We conduct experiments on multi-view face image dataset to evaluate the reconstruction and implement an application for photorealistic rendering of animated face mesh.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces a method for learning a uniform face mesh topology from multi-view images using volume rendering.
- The key idea is to optimize the face mesh topology during the reconstruction process, rather than using a fixed topology, to better capture the underlying facial structure.
- The authors demonstrate that their approach outperforms state-of-the-art methods for multi-view 3D face reconstruction on several benchmark datasets.
Plain English Explanation
The paper presents a new way to reconstruct 3D face models from multiple camera views. Rather than using a pre-defined mesh topology, the method learns the optimal mesh structure as part of the reconstruction process. This allows the model to better capture the unique shape and details of each person's face.
The authors leverage volume rendering techniques to enable this topology optimization. By representing the face as a 3D volume, they can optimize the underlying mesh vertices and connectivity to accurately match the observed images from multiple viewpoints. This differs from traditional approaches that use a fixed mesh template, which may not fit every face equally well.
The results show this learnable topology approach leads to more accurate 3D face reconstructions compared to existing methods. The ability to adaptively model the facial structure is a key advantage, as faces can vary significantly in their precise shape and features from person to person.
Technical Explanation
The core innovation in this work is the ability to learn the optimal face mesh topology during the 3D reconstruction process, rather than using a pre-defined template mesh. This is achieved through the use of a volume rendering approach, which represents the face as a 3D density field.
The system takes as input a set of multi-view images of a face, along with the corresponding camera parameters. It then optimizes both the vertex positions of the face mesh and the mesh connectivity to best match the observed images. This is done by differentiating through the volume rendering process to enable end-to-end training.
The authors demonstrate that this learnable topology approach outperforms state-of-the-art methods like MVD-Fusion and HumanMeshRecovery on several benchmarks for multi-view 3D face reconstruction. The flexibility to adapt the mesh structure to each individual face leads to more accurate reconstructions.
Critical Analysis
The key limitation discussed in the paper is the computational complexity of the volume rendering process, which is required for the topology optimization. This makes the method slower than approaches that use a fixed mesh template. The authors note that further improvements to the efficiency of the volume rendering could help address this issue.
Another potential concern is the reliance on multi-view image data for training and inference. While the method is shown to work well on benchmark datasets, its performance may degrade for real-world applications with fewer or lower-quality camera views. Extending the approach to handle more diverse and unconstrained input conditions could broaden its practical applicability.
Additionally, the paper does not provide a detailed analysis of the learned mesh topologies or discuss how they differ from traditional fixed templates. Further exploration of the topological properties and their relationship to facial structure could yield additional insights.
Conclusion
Overall, this work presents a novel approach for multi-view 3D face reconstruction that learns the optimal mesh topology as part of the reconstruction process. By leveraging volume rendering, the method is able to adaptively model the unique shape and features of each individual face, leading to more accurate 3D reconstructions.
The ability to learn the mesh structure, rather than relying on a pre-defined template, is a significant advance in the field of 3D facial modeling. This flexibility could have important applications in areas such as face animation, virtual avatars, and medical imaging, where capturing the precise facial geometry is crucial.
While the computational complexity remains a challenge, the authors' work demonstrates the potential of learnable topology optimization for multi-view 3D reconstruction. Further research in this direction could lead to even more robust and versatile methods for reconstructing 3D face models from real-world data.
Related Papers
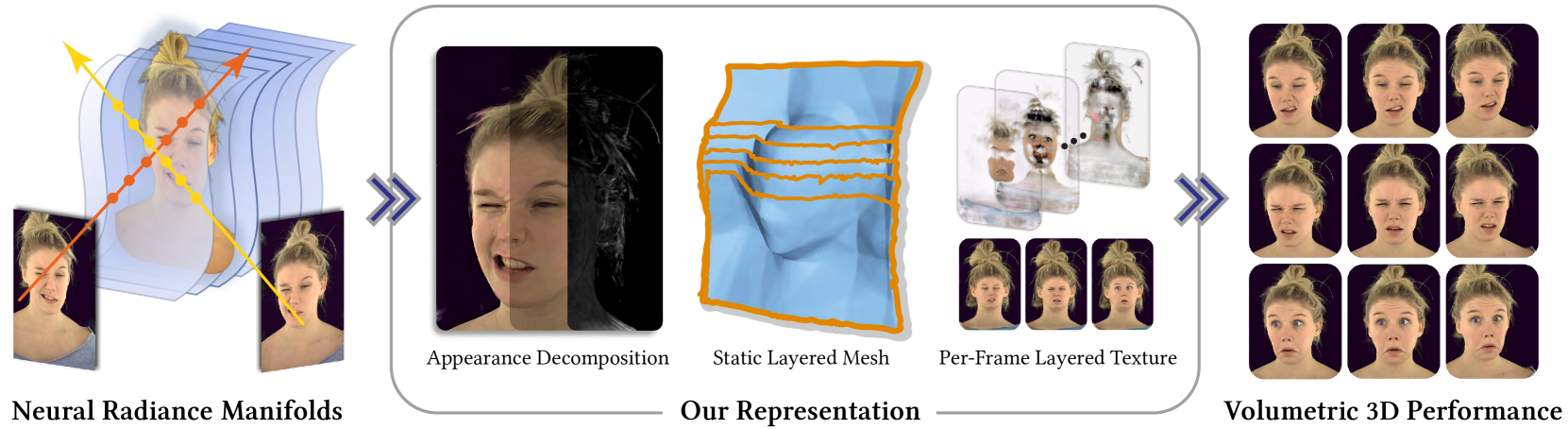
FaceFolds: Meshed Radiance Manifolds for Efficient Volumetric Rendering of Dynamic Faces
Safa C. Medin, Gengyan Li, Ruofei Du, Stephan Garbin, Philip Davidson, Gregory W. Wornell, Thabo Beeler, Abhimitra Meka
0
0
3D rendering of dynamic face captures is a challenging problem, and it demands improvements on several fronts$unicode{x2014}$photorealism, efficiency, compatibility, and configurability. We present a novel representation that enables high-quality volumetric rendering of an actor's dynamic facial performances with minimal compute and memory footprint. It runs natively on commodity graphics soft- and hardware, and allows for a graceful trade-off between quality and efficiency. Our method utilizes recent advances in neural rendering, particularly learning discrete radiance manifolds to sparsely sample the scene to model volumetric effects. We achieve efficient modeling by learning a single set of manifolds for the entire dynamic sequence, while implicitly modeling appearance changes as temporal canonical texture. We export a single layered mesh and view-independent RGBA texture video that is compatible with legacy graphics renderers without additional ML integration. We demonstrate our method by rendering dynamic face captures of real actors in a game engine, at comparable photorealism to state-of-the-art neural rendering techniques at previously unseen frame rates.
4/23/2024
🤷
InstantAvatar: Efficient 3D Head Reconstruction via Surface Rendering
Antonio Canela, Pol Caselles, Ibrar Malik, Eduard Ramon, Jaime Garc'ia, Jordi S'anchez-Riera, Gil Triginer, Francesc Moreno-Noguer
0
0
Recent advances in full-head reconstruction have been obtained by optimizing a neural field through differentiable surface or volume rendering to represent a single scene. While these techniques achieve an unprecedented accuracy, they take several minutes, or even hours, due to the expensive optimization process required. In this work, we introduce InstantAvatar, a method that recovers full-head avatars from few images (down to just one) in a few seconds on commodity hardware. In order to speed up the reconstruction process, we propose a system that combines, for the first time, a voxel-grid neural field representation with a surface renderer. Notably, a naive combination of these two techniques leads to unstable optimizations that do not converge to valid solutions. In order to overcome this limitation, we present a novel statistical model that learns a prior distribution over 3D head signed distance functions using a voxel-grid based architecture. The use of this prior model, in combination with other design choices, results into a system that achieves 3D head reconstructions with comparable accuracy as the state-of-the-art with a 100x speed-up.
4/8/2024
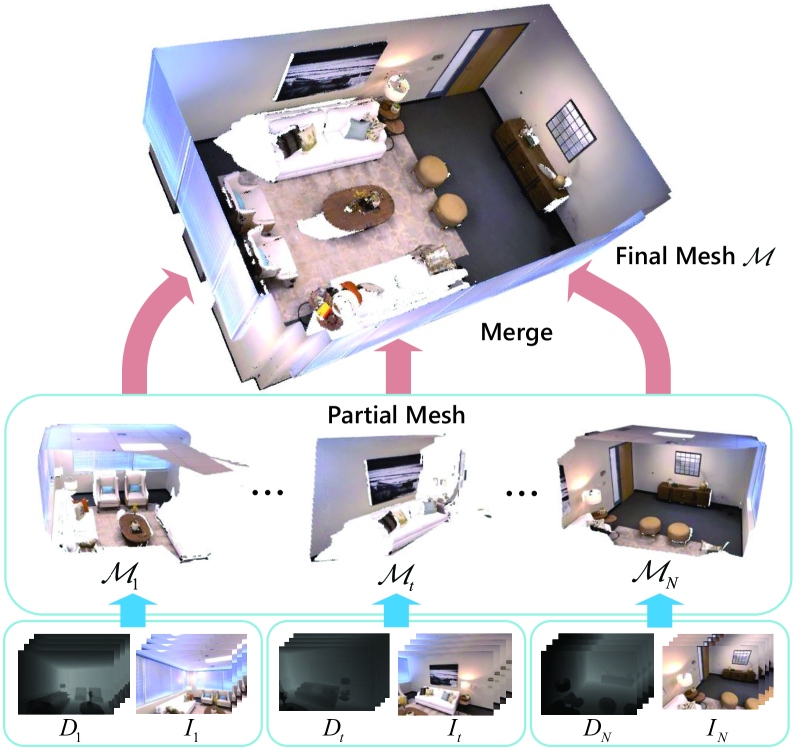
HVOFusion: Incremental Mesh Reconstruction Using Hybrid Voxel Octree
Shaofan Liu, Junbo Chen, Jianke Zhu
0
0
Incremental scene reconstruction is essential to the navigation in robotics. Most of the conventional methods typically make use of either TSDF (truncated signed distance functions) volume or neural networks to implicitly represent the surface. Due to the voxel representation or involving with time-consuming sampling, they have difficulty in balancing speed, memory storage, and surface quality. In this paper, we propose a novel hybrid voxel-octree approach to effectively fuse octree with voxel structures so that we can take advantage of both implicit surface and explicit triangular mesh representation. Such sparse structure preserves triangular faces in the leaf nodes and produces partial meshes sequentially for incremental reconstruction. This storage scheme allows us to naturally optimize the mesh in explicit 3D space to achieve higher surface quality. We iteratively deform the mesh towards the target and recovers vertex colors by optimizing a shading model. Experimental results on several datasets show that our proposed approach is capable of quickly and accurately reconstructing a scene with realistic colors.
4/30/2024
🧠
Geometry-aware Reconstruction and Fusion-refined Rendering for Generalizable Neural Radiance Fields
Tianqi Liu, Xinyi Ye, Min Shi, Zihao Huang, Zhiyu Pan, Zhan Peng, Zhiguo Cao
0
0
Generalizable NeRF aims to synthesize novel views for unseen scenes. Common practices involve constructing variance-based cost volumes for geometry reconstruction and encoding 3D descriptors for decoding novel views. However, existing methods show limited generalization ability in challenging conditions due to inaccurate geometry, sub-optimal descriptors, and decoding strategies. We address these issues point by point. First, we find the variance-based cost volume exhibits failure patterns as the features of pixels corresponding to the same point can be inconsistent across different views due to occlusions or reflections. We introduce an Adaptive Cost Aggregation (ACA) approach to amplify the contribution of consistent pixel pairs and suppress inconsistent ones. Unlike previous methods that solely fuse 2D features into descriptors, our approach introduces a Spatial-View Aggregator (SVA) to incorporate 3D context into descriptors through spatial and inter-view interaction. When decoding the descriptors, we observe the two existing decoding strategies excel in different areas, which are complementary. A Consistency-Aware Fusion (CAF) strategy is proposed to leverage the advantages of both. We incorporate the above ACA, SVA, and CAF into a coarse-to-fine framework, termed Geometry-aware Reconstruction and Fusion-refined Rendering (GeFu). GeFu attains state-of-the-art performance across multiple datasets. Code is available at https://github.com/TQTQliu/GeFu .
4/29/2024