Fact-Checking Generative AI: Ontology-Driven Biological Graphs for Disease-Gene Link Verification
2308.03929
0
0
🤿
Abstract
Since the launch of various generative AI tools, scientists have been striving to evaluate their capabilities and contents, in the hope of establishing trust in their generative abilities. Regulations and guidelines are emerging to verify generated contents and identify novel uses. we aspire to demonstrate how ChatGPT claims are checked computationally using the rigor of network models. We aim to achieve fact-checking of the knowledge embedded in biological graphs that were contrived from ChatGPT contents at the aggregate level. We adopted a biological networks approach that enables the systematic interrogation of ChatGPT's linked entities. We designed an ontology-driven fact-checking algorithm that compares biological graphs constructed from approximately 200,000 PubMed abstracts with counterparts constructed from a dataset generated using the ChatGPT-3.5 Turbo model. In 10-samples of 250 randomly selected records a ChatGPT dataset of 1000 simulated articles , the fact-checking link accuracy ranged from 70% to 86%. This study demonstrated high accuracy of aggregate disease-gene links relationships found in ChatGPT-generated texts.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Scientists are evaluating the capabilities and contents of various generative AI tools, like ChatGPT, to establish trust in their abilities.
- Regulations and guidelines are emerging to verify generated content and identify novel uses.
- This study aims to computationally check claims made by ChatGPT using rigorous network models and fact-check the knowledge embedded in biological graphs derived from ChatGPT content.
Plain English Explanation
With the rise of powerful generative AI tools like ChatGPT, scientists are working to evaluate how well these systems can create content and what knowledge they have learned. The goal is to build trust in these AI capabilities by verifying the accuracy of the information they generate.
To do this, the researchers in this study used a biological network approach. They constructed graphs representing relationships between diseases and genes, based on both scientific literature and content generated by the ChatGPT-3.5 Turbo model. By systematically comparing these graphs, they were able to assess the accuracy of the disease-gene links found in the ChatGPT-generated text.
In 10 samples of 1,000 simulated articles each, the fact-checking process found that the accuracy of the disease-gene relationships ranged from 70% to 86%. This suggests that ChatGPT is generating content with a high degree of accuracy when it comes to these specific scientific connections.
Technical Explanation
The researchers adopted a biological networks approach to enable the systematic interrogation of the linked entities within ChatGPT's generated content. They designed an ontology-driven fact-checking algorithm that compared biological graphs constructed from approximately 200,000 PubMed abstracts with counterpart graphs constructed from a dataset generated using the ChatGPT-3.5 Turbo model.
In 10 samples of 250 randomly selected records from a 1,000-article ChatGPT dataset, the fact-checking process found that the accuracy of the disease-gene links ranged from 70% to 86%. This demonstrates a high degree of accuracy in the aggregate disease-gene relationships found within the text generated by ChatGPT.
Critical Analysis
The study provides a rigorous, computational approach to verifying the factual accuracy of content generated by ChatGPT. By focusing on the disease-gene relationships embedded in the text, the researchers were able to leverage well-established biological knowledge to assess the validity of ChatGPT's outputs.
However, it's important to note that this study only evaluated a specific type of factual knowledge, and the accuracy of ChatGPT's content may vary depending on the domain and complexity of the information being generated. Further research is needed to understand the broader capabilities and limitations of ChatGPT and other generative AI systems.
Additionally, the study acknowledges that the fact-checking process may not capture more nuanced aspects of the generated content, such as sentiment or contextual appropriateness. Continued exploration of these areas could provide a more comprehensive evaluation of generative AI capabilities.
Conclusion
This study demonstrates a promising approach to computationally verifying the factual accuracy of content generated by ChatGPT. By leveraging biological network models, the researchers were able to assess the validity of disease-gene relationships found in ChatGPT's outputs with a high degree of accuracy.
As generative AI systems become more advanced and widespread, ongoing efforts to evaluate their capabilities and contents will be crucial for building trust and identifying appropriate use cases. The insights from this study contribute to a growing body of research aimed at understanding and validating the knowledge and capabilities of these powerful AI tools.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
Detection of ChatGPT Fake Science with the xFakeSci Learning Algorithm
Ahmed Abdeen Hamed, Xindong Wu
0
0
Generative AI tools exemplified by ChatGPT are becoming a new reality. This study is motivated by the premise that ``AI generated content may exhibit a distinctive behavior that can be separated from scientific articles''. In this study, we show how articles can be generated using means of prompt engineering for various diseases and conditions. We then show how we tested this premise in two phases and prove its validity. Subsequently, we introduce xFakeSci, a novel learning algorithm, that is capable of distinguishing ChatGPT-generated articles from publications produced by scientists. The algorithm is trained using network models driven from both sources. As for the classification step, it was performed using 300 articles per condition. The actual label steps took place against an equal mix of 50 generated articles and 50 authentic PubMed abstracts. The testing also spanned publication periods from 2010 to 2024 and encompassed research on three distinct diseases: cancer, depression, and Alzheimer's. Further, we evaluated the accuracy of the xFakeSci algorithm against some of the classical data mining algorithms (e.g., Support Vector Machines, Regression, and Naive Bayes). The xFakeSci algorithm achieved F1 scores ranging from 80% to 94%, outperforming common data mining algorithms, which scored F1 values between 38% and 52%. We attribute the noticeable difference to the introduction of calibration and a proximity distance heuristic, which underscores this promising performance. Indeed, the prediction of fake science generated by ChatGPT presents a considerable challenge. Nonetheless, the introduction of the xFakeSci algorithm is a significant step on the way to combating fake science.
4/16/2024
📉
Applying BioBERT to Extract Germline Gene-Disease Associations for Building a Knowledge Graph from the Biomedical Literature
Armando D. Diaz Gonzalez, Kevin S. Hughes, Songhui Yue, Sean T. Hayes
0
0
Published biomedical information has and continues to rapidly increase. The recent advancements in Natural Language Processing (NLP), have generated considerable interest in automating the extraction, normalization, and representation of biomedical knowledge about entities such as genes and diseases. Our study analyzes germline abstracts in the construction of knowledge graphs of the of the immense work that has been done in this area for genes and diseases. This paper presents SimpleGermKG, an automatic knowledge graph construction approach that connects germline genes and diseases. For the extraction of genes and diseases, we employ BioBERT, a pre-trained BERT model on biomedical corpora. We propose an ontology-based and rule-based algorithm to standardize and disambiguate medical terms. For semantic relationships between articles, genes, and diseases, we implemented a part-whole relation approach to connect each entity with its data source and visualize them in a graph-based knowledge representation. Lastly, we discuss the knowledge graph applications, limitations, and challenges to inspire the future research of germline corpora. Our knowledge graph contains 297 genes, 130 diseases, and 46,747 triples. Graph-based visualizations are used to show the results.
4/24/2024
🔎
FakeGPT: Fake News Generation, Explanation and Detection of Large Language Models
Yue Huang, Lichao Sun
0
0
The rampant spread of fake news has adversely affected society, resulting in extensive research on curbing its spread. As a notable milestone in large language models (LLMs), ChatGPT has gained significant attention due to its exceptional natural language processing capabilities. In this study, we present a thorough exploration of ChatGPT's proficiency in generating, explaining, and detecting fake news as follows. Generation -- We employ four prompt methods to generate fake news samples and prove the high quality of these samples through both self-assessment and human evaluation. Explanation -- We obtain nine features to characterize fake news based on ChatGPT's explanations and analyze the distribution of these factors across multiple public datasets. Detection -- We examine ChatGPT's capacity to identify fake news. We explore its detection consistency and then propose a reason-aware prompt method to improve its performance. Although our experiments demonstrate that ChatGPT shows commendable performance in detecting fake news, there is still room for its improvement. Consequently, we further probe into the potential extra information that could bolster its effectiveness in detecting fake news.
4/9/2024
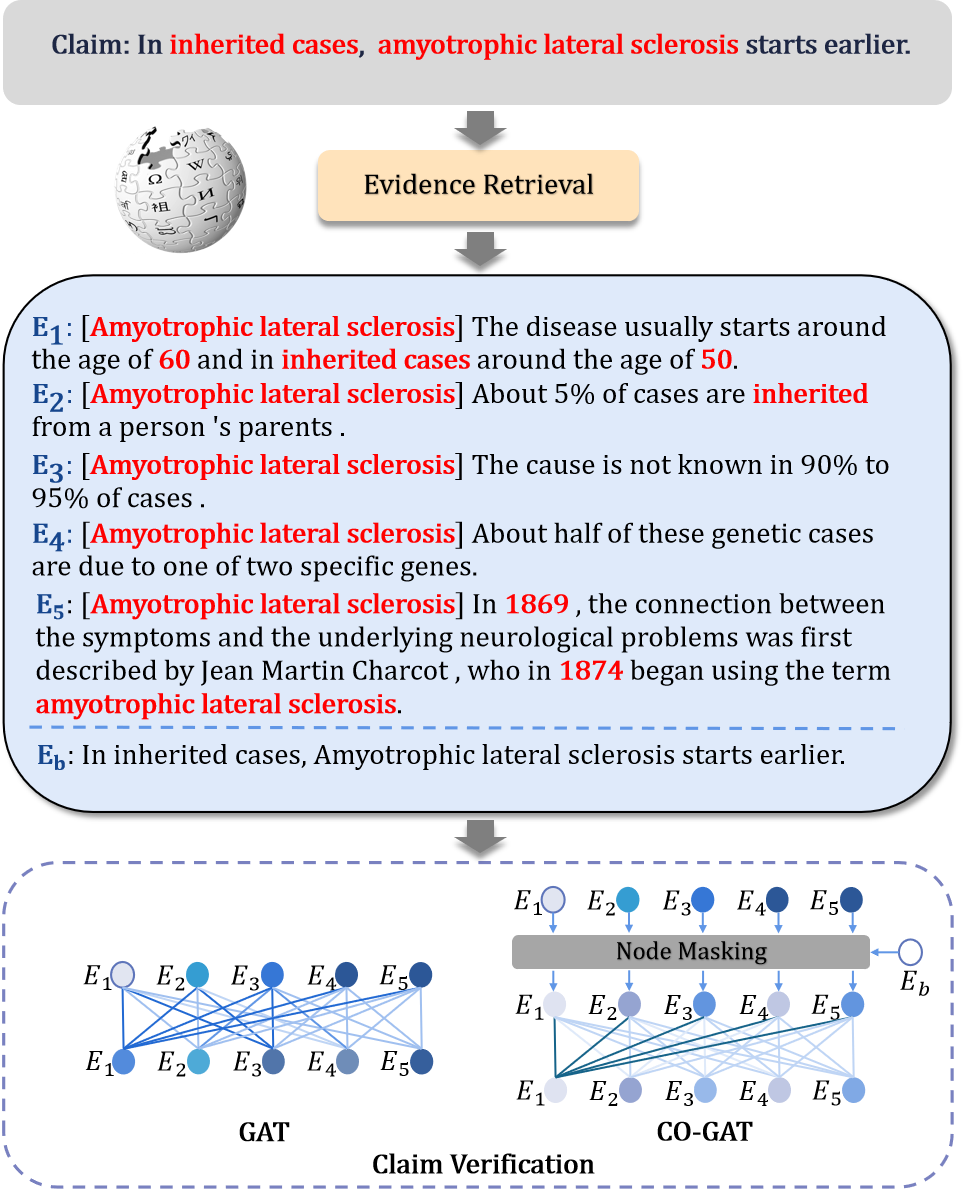
New!Multi-Evidence based Fact Verification via A Confidential Graph Neural Network
Yuqing Lan, Zhenghao Liu, Yu Gu, Xiaoyuan Yi, Xiaohua Li, Liner Yang, Ge Yu
0
0
Fact verification tasks aim to identify the integrity of textual contents according to the truthful corpus. Existing fact verification models usually build a fully connected reasoning graph, which regards claim-evidence pairs as nodes and connects them with edges. They employ the graph to propagate the semantics of the nodes. Nevertheless, the noisy nodes usually propagate their semantics via the edges of the reasoning graph, which misleads the semantic representations of other nodes and amplifies the noise signals. To mitigate the propagation of noisy semantic information, we introduce a Confidential Graph Attention Network (CO-GAT), which proposes a node masking mechanism for modeling the nodes. Specifically, CO-GAT calculates the node confidence score by estimating the relevance between the claim and evidence pieces. Then, the node masking mechanism uses the node confidence scores to control the noise information flow from the vanilla node to the other graph nodes. CO-GAT achieves a 73.59% FEVER score on the FEVER dataset and shows the generalization ability by broadening the effectiveness to the science-specific domain.
5/20/2024