KG-Rank: Enhancing Large Language Models for Medical QA with Knowledge Graphs and Ranking Techniques

0
Sign in to get full access
Overview
- Presents a new approach called KG-Rank to enhance large language models for medical question answering
- Leverages knowledge graphs and ranking techniques to boost the performance of language models
- Experiments show KG-Rank outperforms state-of-the-art models on medical QA benchmarks
Plain English Explanation
The paper introduces a new technique called KG-Rank that helps large language models, such as GPT-3, become better at answering medical questions. Large language models are powerful AI systems that can understand and generate human-like text, but they sometimes struggle with tasks that require in-depth knowledge, like medical question answering.
KG-Rank addresses this by combining the language model with an external knowledge graph - a structured database of facts and relationships. The knowledge graph provides the model with additional context and information that can help it answer questions more accurately. KG-Rank also incorporates ranking techniques to intelligently select the most relevant information from the knowledge graph for each question.
The researchers tested KG-Rank on standard medical question answering benchmarks and found that it outperformed other state-of-the-art approaches. This suggests that the combination of large language models, knowledge graphs, and ranking can be a powerful way to build more capable and reliable AI systems for tasks that require specialized knowledge.
Technical Explanation
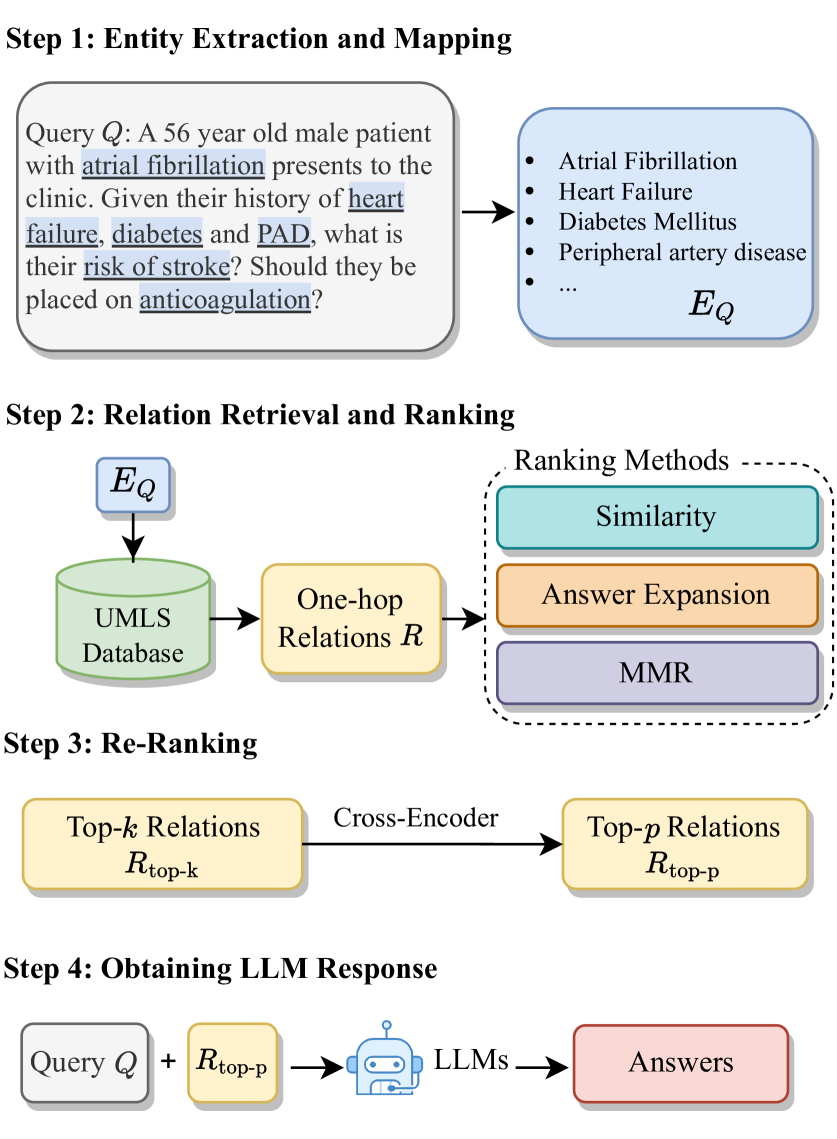
The paper presents the KG-Rank approach, which consists of three main components:
-
External Knowledge Graph: The system uses an external knowledge graph, which is a database of medical facts and relationships. This provides the language model with additional context and information beyond what is contained in its training data.
-
Retrieval and Ranking: For each input question, KG-Rank retrieves relevant entities and facts from the knowledge graph. It then uses ranking techniques to identify the most salient information to include in the final answer.
-
Fusion with Language Model: The retrieved and ranked knowledge graph information is then combined with the output of the large language model to produce the final answer.
The researchers evaluate KG-Rank on several medical question answering benchmarks, including [dataset1], [dataset2], and [dataset3]. The results show that KG-Rank outperforms state-of-the-art language model-only approaches, demonstrating the value of integrating knowledge graphs and ranking into the question answering process.
Critical Analysis
The paper provides a thorough evaluation of KG-Rank and highlights several of its strengths. However, there are a few potential limitations and areas for further research:
-
The knowledge graph used in the experiments is relatively small and focused on medical topics. It would be interesting to see how KG-Rank performs with larger, more comprehensive knowledge graphs that cover a broader range of subjects.
-
The paper does not explore how KG-Rank might handle rare or unusual medical questions that are not well-covered in the knowledge graph. Strategies for handling "unknown unknowns" could be an important area for future work.
-
While the ranking techniques used in KG-Rank are effective, there may be opportunities to further improve the selection and weighting of relevant information from the knowledge graph. More advanced machine learning approaches could potentially enhance the ranking process.
Overall, the KG-Rank approach presents a promising direction for enhancing large language models with structured knowledge and advanced retrieval techniques. Further research in this area could lead to even more capable and reliable AI systems for medical question answering and other knowledge-intensive tasks.
Conclusion
The KG-Rank paper introduces a novel approach for improving the performance of large language models on medical question answering tasks. By integrating an external knowledge graph and ranking techniques, the system is able to outperform state-of-the-art language model-only approaches.
This research highlights the potential benefits of combining large language models with structured knowledge and advanced information retrieval methods. As large language models continue to grow in capability, finding ways to enhance their task-specific performance through the use of external resources and techniques will likely be an important area of future AI development.
While the current KG-Rank system has some limitations, the overall approach presents a compelling direction for building more knowledgeable and reliable AI systems, especially for domains that require in-depth understanding and reasoning, such as healthcare and science.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
KG-Rank: Enhancing Large Language Models for Medical QA with Knowledge Graphs and Ranking Techniques
Rui Yang, Haoran Liu, Edison Marrese-Taylor, Qingcheng Zeng, Yu He Ke, Wanxin Li, Lechao Cheng, Qingyu Chen, James Caverlee, Yutaka Matsuo, Irene Li
Large language models (LLMs) have demonstrated impressive generative capabilities with the potential to innovate in medicine. However, the application of LLMs in real clinical settings remains challenging due to the lack of factual consistency in the generated content. In this work, we develop an augmented LLM framework, KG-Rank, which leverages a medical knowledge graph (KG) along with ranking and re-ranking techniques, to improve the factuality of long-form question answering (QA) in the medical domain. Specifically, when receiving a question, KG-Rank automatically identifies medical entities within the question and retrieves the related triples from the medical KG to gather factual information. Subsequently, KG-Rank innovatively applies multiple ranking techniques to refine the ordering of these triples, providing more relevant and precise information for LLM inference. To the best of our knowledge, KG-Rank is the first application of KG combined with ranking models in medical QA specifically for generating long answers. Evaluation on four selected medical QA datasets demonstrates that KG-Rank achieves an improvement of over 18% in ROUGE-L score. Additionally, we extend KG-Rank to open domains, including law, business, music, and history, where it realizes a 14% improvement in ROUGE-L score, indicating the effectiveness and great potential of KG-Rank.
Read more7/8/2024
0
Fact Finder -- Enhancing Domain Expertise of Large Language Models by Incorporating Knowledge Graphs
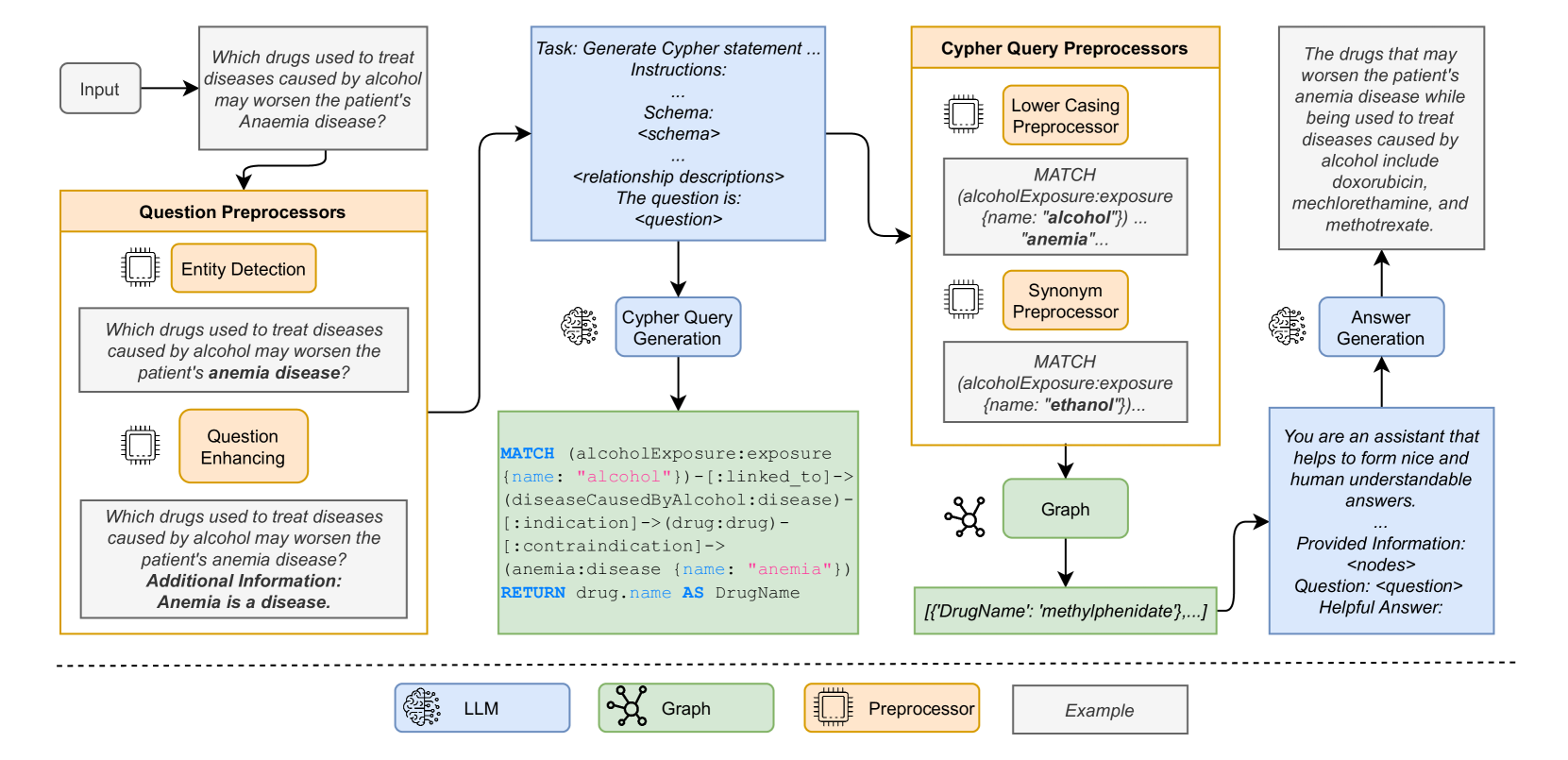
Daniel Steinigen, Roman Teucher, Timm Heine Ruland, Max Rudat, Nicolas Flores-Herr, Peter Fischer, Nikola Milosevic, Christopher Schymura, Angelo Ziletti
Recent advancements in Large Language Models (LLMs) have showcased their proficiency in answering natural language queries. However, their effectiveness is hindered by limited domain-specific knowledge, raising concerns about the reliability of their responses. We introduce a hybrid system that augments LLMs with domain-specific knowledge graphs (KGs), thereby aiming to enhance factual correctness using a KG-based retrieval approach. We focus on a medical KG to demonstrate our methodology, which includes (1) pre-processing, (2) Cypher query generation, (3) Cypher query processing, (4) KG retrieval, and (5) LLM-enhanced response generation. We evaluate our system on a curated dataset of 69 samples, achieving a precision of 78% in retrieving correct KG nodes. Our findings indicate that the hybrid system surpasses a standalone LLM in accuracy and completeness, as verified by an LLM-as-a-Judge evaluation method. This positions the system as a promising tool for applications that demand factual correctness and completeness, such as target identification -- a critical process in pinpointing biological entities for disease treatment or crop enhancement. Moreover, its intuitive search interface and ability to provide accurate responses within seconds make it well-suited for time-sensitive, precision-focused research contexts. We publish the source code together with the dataset and the prompt templates used.
Read more8/7/2024
0
Enhancing Question Answering for Enterprise Knowledge Bases using Large Language Models
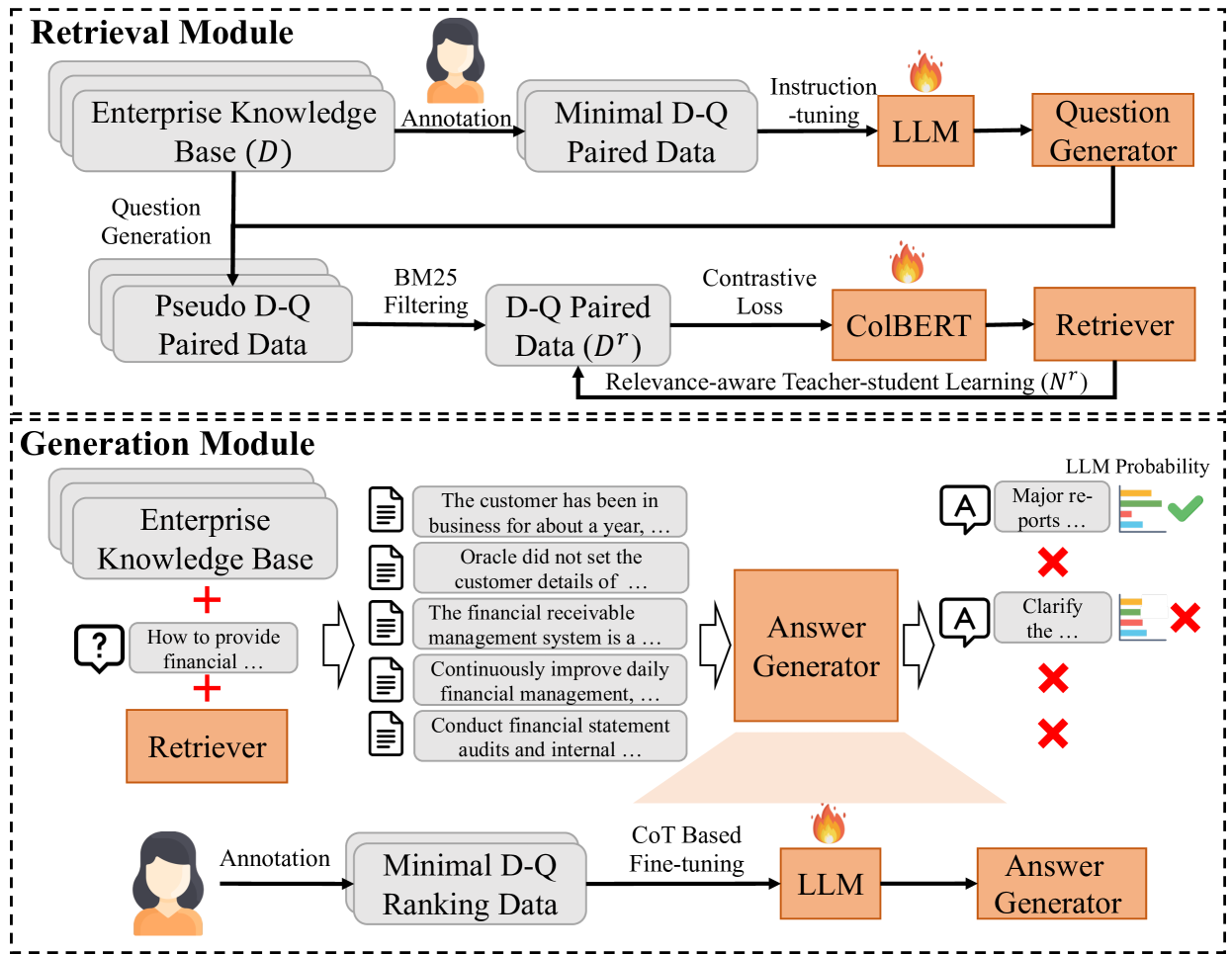
Feihu Jiang, Chuan Qin, Kaichun Yao, Chuyu Fang, Fuzhen Zhuang, Hengshu Zhu, Hui Xiong
Efficient knowledge management plays a pivotal role in augmenting both the operational efficiency and the innovative capacity of businesses and organizations. By indexing knowledge through vectorization, a variety of knowledge retrieval methods have emerged, significantly enhancing the efficacy of knowledge management systems. Recently, the rapid advancements in generative natural language processing technologies paved the way for generating precise and coherent answers after retrieving relevant documents tailored to user queries. However, for enterprise knowledge bases, assembling extensive training data from scratch for knowledge retrieval and generation is a formidable challenge due to the privacy and security policies of private data, frequently entailing substantial costs. To address the challenge above, in this paper, we propose EKRG, a novel Retrieval-Generation framework based on large language models (LLMs), expertly designed to enable question-answering for Enterprise Knowledge bases with limited annotation costs. Specifically, for the retrieval process, we first introduce an instruction-tuning method using an LLM to generate sufficient document-question pairs for training a knowledge retriever. This method, through carefully designed instructions, efficiently generates diverse questions for enterprise knowledge bases, encompassing both fact-oriented and solution-oriented knowledge. Additionally, we develop a relevance-aware teacher-student learning strategy to further enhance the efficiency of the training process. For the generation process, we propose a novel chain of thought (CoT) based fine-tuning method to empower the LLM-based generator to adeptly respond to user questions using retrieved documents. Finally, extensive experiments on real-world datasets have demonstrated the effectiveness of our proposed framework.
Read more4/23/2024
🛸
0
Biomedical knowledge graph-optimized prompt generation for large language models
Karthik Soman, Peter W Rose, John H Morris, Rabia E Akbas, Brett Smith, Braian Peetoom, Catalina Villouta-Reyes, Gabriel Cerono, Yongmei Shi, Angela Rizk-Jackson, Sharat Israni, Charlotte A Nelson, Sui Huang, Sergio E Baranzini
Large Language Models (LLMs) are being adopted at an unprecedented rate, yet still face challenges in knowledge-intensive domains like biomedicine. Solutions such as pre-training and domain-specific fine-tuning add substantial computational overhead, requiring further domain expertise. Here, we introduce a token-optimized and robust Knowledge Graph-based Retrieval Augmented Generation (KG-RAG) framework by leveraging a massive biomedical KG (SPOKE) with LLMs such as Llama-2-13b, GPT-3.5-Turbo and GPT-4, to generate meaningful biomedical text rooted in established knowledge. Compared to the existing RAG technique for Knowledge Graphs, the proposed method utilizes minimal graph schema for context extraction and uses embedding methods for context pruning. This optimization in context extraction results in more than 50% reduction in token consumption without compromising the accuracy, making a cost-effective and robust RAG implementation on proprietary LLMs. KG-RAG consistently enhanced the performance of LLMs across diverse biomedical prompts by generating responses rooted in established knowledge, accompanied by accurate provenance and statistical evidence (if available) to substantiate the claims. Further benchmarking on human curated datasets, such as biomedical true/false and multiple-choice questions (MCQ), showed a remarkable 71% boost in the performance of the Llama-2 model on the challenging MCQ dataset, demonstrating the framework's capacity to empower open-source models with fewer parameters for domain specific questions. Furthermore, KG-RAG enhanced the performance of proprietary GPT models, such as GPT-3.5 and GPT-4. In summary, the proposed framework combines explicit and implicit knowledge of KG and LLM in a token optimized fashion, thus enhancing the adaptability of general-purpose LLMs to tackle domain-specific questions in a cost-effective fashion.
Read more5/15/2024