On the Implicit Bias of Adam
2309.00079
0
0
🔮
Abstract
In previous literature, backward error analysis was used to find ordinary differential equations (ODEs) approximating the gradient descent trajectory. It was found that finite step sizes implicitly regularize solutions because terms appearing in the ODEs penalize the two-norm of the loss gradients. We prove that the existence of similar implicit regularization in RMSProp and Adam depends on their hyperparameters and the training stage, but with a different norm involved: the corresponding ODE terms either penalize the (perturbed) one-norm of the loss gradients or, conversely, impede its reduction (the latter case being typical). We also conduct numerical experiments and discuss how the proven facts can influence generalization.
Create account to get full access
Overview
- The paper analyzes the implicit regularization effects of the RMSProp and Adam optimization algorithms, which are commonly used in training deep neural networks.
- It was previously found that the gradient descent algorithm has an implicit regularization effect due to the finite step size, which penalizes the two-norm of the loss gradients.
- This paper shows that the implicit regularization in RMSProp and Adam depends on their hyperparameters and the training stage, but it involves a different norm - either the (perturbed) one-norm of the loss gradients or an impeding of its reduction.
- Numerical experiments are conducted to demonstrate these effects and discuss how they can influence the generalization performance of the trained models.
Plain English Explanation
Optimization algorithms like gradient descent, RMSProp, and Adam are commonly used to train deep neural networks. These algorithms don't just find the best set of model parameters - they also have an "implicit regularization" effect, which means they subtly encourage the model to have certain desirable properties, even without explicit regularization techniques.
Previous research showed that gradient descent's implicit regularization is related to the size of the steps it takes - larger steps tend to produce models with smaller gradients (the rate of change of the loss function). This is beneficial because smaller gradients often lead to better generalization, or the ability to perform well on new, unseen data.
This new paper analyzes the implicit regularization effects of RMSProp and Adam. It finds that these algorithms also have implicit regularization, but the details are a bit different. Depending on the algorithm's hyperparameters and the stage of training, the implicit regularization either encourages smaller one-norm gradients (the sum of the absolute values of the gradients) or makes it harder for the one-norm to decrease.
The researchers also ran experiments to see how these implicit regularization effects influence the final performance of the trained models. The results suggest that understanding these effects can help us use optimization algorithms more effectively to improve the generalization of deep learning models.
Technical Explanation
The paper builds on prior work that used backward error analysis to find ordinary differential equations (ODEs) that approximate the trajectory of gradient descent. This analysis showed that the finite step size of gradient descent implicitly regularizes the solutions by penalizing the two-norm (Euclidean length) of the loss gradients.
In this paper, the researchers prove that similar implicit regularization exists in the RMSProp and Adam optimization algorithms, but the norm involved is different. Depending on the algorithm's hyperparameters and the stage of training, the corresponding ODE terms either penalize the (perturbed) one-norm of the loss gradients or impede its reduction.
The one-norm is the sum of the absolute values of the gradient components, which is related to the Dollar-ellinfty-Dollar norm commonly used in optimization literature. The researchers provide theoretical analysis and numerical experiments to demonstrate these implicit regularization effects and discuss how they can influence the generalization performance of the trained models.
Critical Analysis
The paper provides a rigorous theoretical analysis of the implicit regularization effects in RMSProp and Adam, building on previous work on gradient descent. The insights are valuable for understanding how these widely used optimization algorithms behave and how their hyperparameters can impact the training and generalization of deep learning models.
However, the analysis is limited to the specific norms involved (two-norm and one-norm) and does not explore other potential implicit regularization effects. Additionally, the numerical experiments, while informative, could be expanded to cover a wider range of network architectures, datasets, and training scenarios to better understand the practical implications of the findings.
It would also be interesting to see if these implicit regularization effects interact with other techniques, such as explicit regularization or data augmentation, and how they might be leveraged to improve the generalization of deep learning models.
Conclusion
This paper makes an important contribution to the understanding of optimization algorithms used in deep learning. By analyzing the implicit regularization effects in RMSProp and Adam, the researchers shed light on how these algorithms can implicitly encourage desirable properties in the trained models, such as smaller gradients.
These insights can help deep learning practitioners make more informed choices when selecting and tuning optimization algorithms for their specific tasks and datasets. Ultimately, a better understanding of these implicit biases can lead to more effective and robust deep learning models that generalize well to new, unseen data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
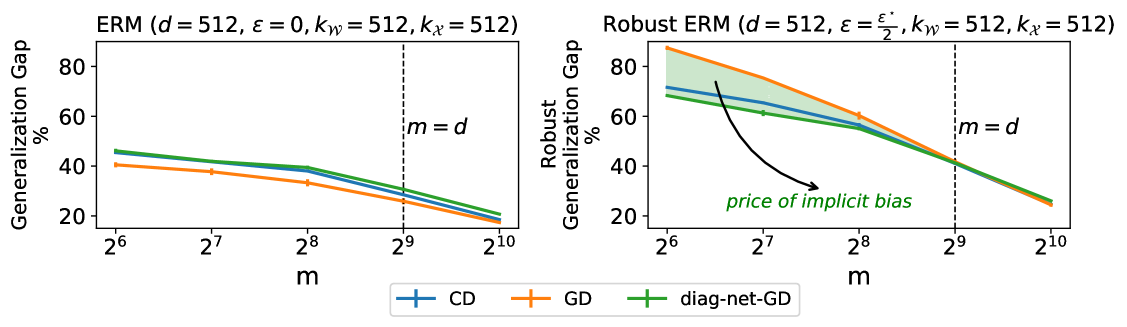
The Price of Implicit Bias in Adversarially Robust Generalization
Nikolaos Tsilivis, Natalie Frank, Nathan Srebro, Julia Kempe
0
0
We study the implicit bias of optimization in robust empirical risk minimization (robust ERM) and its connection with robust generalization. In classification settings under adversarial perturbations with linear models, we study what type of regularization should ideally be applied for a given perturbation set to improve (robust) generalization. We then show that the implicit bias of optimization in robust ERM can significantly affect the robustness of the model and identify two ways this can happen; either through the optimization algorithm or the architecture. We verify our predictions in simulations with synthetic data and experimentally study the importance of implicit bias in robust ERM with deep neural networks.
6/10/2024

The Implicit Bias of Adam on Separable Data
Chenyang Zhang, Difan Zou, Yuan Cao
0
0
Adam has become one of the most favored optimizers in deep learning problems. Despite its success in practice, numerous mysteries persist regarding its theoretical understanding. In this paper, we study the implicit bias of Adam in linear logistic regression. Specifically, we show that when the training data are linearly separable, Adam converges towards a linear classifier that achieves the maximum $ell_infty$-margin. Notably, for a general class of diminishing learning rates, this convergence occurs within polynomial time. Our result shed light on the difference between Adam and (stochastic) gradient descent from a theoretical perspective.
6/18/2024
Implicit Bias of AdamW: $ell_infty$ Norm Constrained Optimization
Shuo Xie, Zhiyuan Li
0
0
Adam with decoupled weight decay, also known as AdamW, is widely acclaimed for its superior performance in language modeling tasks, surpassing Adam with $ell_2$ regularization in terms of generalization and optimization. However, this advantage is not theoretically well-understood. One challenge here is that though intuitively Adam with $ell_2$ regularization optimizes the $ell_2$ regularized loss, it is not clear if AdamW optimizes a specific objective. In this work, we make progress toward understanding the benefit of AdamW by showing that it implicitly performs constrained optimization. More concretely, we show in the full-batch setting, if AdamW converges with any non-increasing learning rate schedule whose partial sum diverges, it must converge to a KKT point of the original loss under the constraint that the $ell_infty$ norm of the parameter is bounded by the inverse of the weight decay factor. This result is built on the observation that Adam can be viewed as a smoothed version of SignGD, which is the normalized steepest descent with respect to $ell_infty$ norm, and a surprising connection between normalized steepest descent with weight decay and Frank-Wolfe.
4/9/2024
⚙️
A Theoretical and Empirical Study on the Convergence of Adam with an Exact Constant Step Size in Non-Convex Settings
Alokendu Mazumder, Rishabh Sabharwal, Manan Tayal, Bhartendu Kumar, Punit Rathore
0
0
In neural network training, RMSProp and Adam remain widely favoured optimisation algorithms. One of the keys to their performance lies in selecting the correct step size, which can significantly influence their effectiveness. Additionally, questions about their theoretical convergence properties continue to be a subject of interest. In this paper, we theoretically analyse a constant step size version of Adam in the non-convex setting and discuss why it is important for the convergence of Adam to use a fixed step size. This work demonstrates the derivation and effective implementation of a constant step size for Adam, offering insights into its performance and efficiency in non convex optimisation scenarios. (i) First, we provide proof that these adaptive gradient algorithms are guaranteed to reach criticality for smooth non-convex objectives with constant step size, and we give bounds on the running time. Both deterministic and stochastic versions of Adam are analysed in this paper. We show sufficient conditions for the derived constant step size to achieve asymptotic convergence of the gradients to zero with minimal assumptions. Next, (ii) we design experiments to empirically study Adam's convergence with our proposed constant step size against stateof the art step size schedulers on classification tasks. Lastly, (iii) we also demonstrate that our derived constant step size has better abilities in reducing the gradient norms, and empirically, we show that despite the accumulation of a few past gradients, the key driver for convergence in Adam is the non-increasing step sizes.
4/5/2024