FADE: Few-shot/zero-shot Anomaly Detection Engine using Large Vision-Language Model

0

Sign in to get full access
Overview
- The paper presents FADE, a Few-shot/Zero-shot Anomaly Detection Engine using large vision-language models.
- FADE can detect anomalies in images without requiring labeled anomaly data for training.
- The approach leverages the rich semantic understanding of large language models to enable few-shot and zero-shot anomaly detection.
Plain English Explanation
FADE: Few-shot/Zero-shot Anomaly Detection Engine using Large Vision-Language Model is a new technique for detecting anomalies in images. Anomaly detection is the task of identifying data points that deviate from the normal patterns in a dataset.
Traditional anomaly detection methods often require a lot of labeled anomaly data for training. FADE overcomes this limitation by using large vision-language models, which are trained on vast amounts of visual and textual data. These models have developed a rich understanding of the visual world and language, which FADE leverages to perform few-shot and zero-shot anomaly detection.
In few-shot anomaly detection, the model only needs a few examples of the anomaly to learn what it looks like and detect it in new images. In zero-shot anomaly detection, the model can detect anomalies without any examples, simply by describing what the anomaly should look like using natural language.
This is a powerful capability that could be very useful in many real-world applications, such as detecting defects in manufacturing, identifying rare diseases in medical imaging, or spotting abnormalities in surveillance footage. By avoiding the need for large labeled anomaly datasets, FADE makes anomaly detection more accessible and practical in a wider range of scenarios.
Technical Explanation
FADE: Few-shot/Zero-shot Anomaly Detection Engine using Large Vision-Language Model proposes a novel approach to anomaly detection that leverages the capabilities of large vision-language models.
The key innovation of FADE is its ability to perform few-shot and zero-shot anomaly detection. In few-shot anomaly detection, the model only requires a small number of annotated examples of the anomaly to learn its visual characteristics and detect it in new images. In zero-shot anomaly detection, the model can detect anomalies without any examples, simply by describing the anomaly in natural language.
To enable this, FADE uses a multi-modal architecture that integrates a vision encoder and a language encoder. The vision encoder processes the input image, while the language encoder processes a textual description of the target anomaly. The outputs from these two encoders are then fused and fed into a decision module that classifies the image as normal or anomalous.
The key advantages of FADE are:
- Data Efficiency: FADE can detect anomalies with very few annotated examples, making it more practical than traditional supervised anomaly detection methods that require large labeled datasets.
- Versatility: FADE's zero-shot capabilities allow it to detect a wide range of anomalies without the need for prior training on those specific anomaly types.
- Interpretability: The language-based interface of FADE allows users to clearly communicate their understanding of anomalies to the model, making the detection process more transparent and intuitive.
The paper evaluates FADE on several anomaly detection benchmarks and demonstrates its superior performance compared to existing few-shot and zero-shot anomaly detection approaches.
Critical Analysis
The FADE: Few-shot/Zero-shot Anomaly Detection Engine using Large Vision-Language Model paper presents a promising approach to anomaly detection, but there are a few potential limitations and areas for further research:
-
Generalization Capabilities: While FADE shows strong performance on the evaluated benchmarks, it's important to assess its ability to generalize to more diverse and complex real-world anomaly detection scenarios. Further testing on a broader range of datasets would help validate the robustness of the approach.
-
Computational Efficiency: As FADE relies on large pre-trained vision-language models, there may be concerns about its computational efficiency and inference speed, which could limit its applicability in time-sensitive or resource-constrained settings. Techniques to optimize the model's performance should be explored.
-
Interpretability and Explainability: The paper emphasizes the interpretability of FADE's language-based interface, but it would be valuable to further investigate how users can understand the model's decision-making process and the reasons behind its anomaly detections. Enhancing the explainability of FADE could increase trust and adoption in critical applications.
-
Handling Novel Anomalies: While FADE's zero-shot capabilities allow it to detect previously unseen anomalies, the paper does not address how the model would perform in the face of completely new and unfamiliar anomaly types. Strategies to improve the model's adaptability to emerging anomalies could be an area for future research.
Overall, the FADE: Few-shot/Zero-shot Anomaly Detection Engine using Large Vision-Language Model paper presents a compelling approach that could significantly advance the field of anomaly detection. Further research to address the identified limitations and explore additional applications would be valuable.
Conclusion
FADE: Few-shot/Zero-shot Anomaly Detection Engine using Large Vision-Language Model introduces a novel anomaly detection technique that leverages the power of large vision-language models. By enabling few-shot and zero-shot anomaly detection, FADE overcomes the data limitations of traditional supervised approaches and offers a more versatile and interpretable solution.
The key strengths of FADE include its data efficiency, versatility in detecting a wide range of anomalies, and its language-based interface that allows for clear communication of anomaly descriptions. While the paper demonstrates promising results, there are opportunities to further explore the model's generalization capabilities, computational efficiency, interpretability, and adaptability to novel anomalies.
Overall, the FADE approach represents an exciting advance in the field of anomaly detection, with the potential to unlock new applications and make this important task more accessible across various industries and domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FADE: Few-shot/zero-shot Anomaly Detection Engine using Large Vision-Language Model
Yuanwei Li, Elizaveta Ivanova, Martins Bruveris
Automatic image anomaly detection is important for quality inspection in the manufacturing industry. The usual unsupervised anomaly detection approach is to train a model for each object class using a dataset of normal samples. However, a more realistic problem is zero-/few-shot anomaly detection where zero or only a few normal samples are available. This makes the training of object-specific models challenging. Recently, large foundation vision-language models have shown strong zero-shot performance in various downstream tasks. While these models have learned complex relationships between vision and language, they are not specifically designed for the tasks of anomaly detection. In this paper, we propose the Few-shot/zero-shot Anomaly Detection Engine (FADE) which leverages the vision-language CLIP model and adjusts it for the purpose of industrial anomaly detection. Specifically, we improve language-guided anomaly segmentation 1) by adapting CLIP to extract multi-scale image patch embeddings that are better aligned with language and 2) by automatically generating an ensemble of text prompts related to industrial anomaly detection. 3) We use additional vision-based guidance from the query and reference images to further improve both zero-shot and few-shot anomaly detection. On the MVTec-AD (and VisA) dataset, FADE outperforms other state-of-the-art methods in anomaly segmentation with pixel-AUROC of 89.6% (91.5%) in zero-shot and 95.4% (97.5%) in 1-normal-shot. Code is available at https://github.com/BMVC-FADE/BMVC-FADE.
Read more9/4/2024

0
AnoPLe: Few-Shot Anomaly Detection via Bi-directional Prompt Learning with Only Normal Samples
Yujin Lee, Seoyoon Jang, Hyunsoo Yoon
Few-shot Anomaly Detection (FAD) poses significant challenges due to the limited availability of training samples and the frequent absence of abnormal samples. Previous approaches often rely on annotations or true abnormal samples to improve detection, but such textual or visual cues are not always accessible. To address this, we introduce AnoPLe, a multi-modal prompt learning method designed for anomaly detection without prior knowledge of anomalies. AnoPLe simulates anomalies and employs bidirectional coupling of textual and visual prompts to facilitate deep interaction between the two modalities. Additionally, we integrate a lightweight decoder with a learnable multi-view signal, trained on multi-scale images to enhance local semantic comprehension. To further improve performance, we align global and local semantics, enriching the image-level understanding of anomalies. The experimental results demonstrate that AnoPLe achieves strong FAD performance, recording 94.1% and 86.2% Image AUROC on MVTec-AD and VisA respectively, with only around a 1% gap compared to the SoTA, despite not being exposed to true anomalies. Code is available at https://github.com/YoojLee/AnoPLe.
Read more8/27/2024

0
Revisiting Few-Shot Object Detection with Vision-Language Models
Anish Madan, Neehar Peri, Shu Kong, Deva Ramanan
The era of vision-language models (VLMs) trained on large web-scale datasets challenges conventional formulations of open-world perception. In this work, we revisit the task of few-shot object detection (FSOD) in the context of recent foundational VLMs. First, we point out that zero-shot VLMs such as GroundingDINO significantly outperform state-of-the-art few-shot detectors (48 vs. 33 AP) on COCO. Despite their strong zero-shot performance, such foundational models may still be sub-optimal. For example, trucks on the web may be defined differently from trucks for a target application such as autonomous vehicle perception. We argue that the task of few-shot recognition can be reformulated as aligning foundation models to target concepts using a few examples. Interestingly, such examples can be multi-modal, using both text and visual cues, mimicking instructions that are often given to human annotators when defining a target concept of interest. Concretely, we propose Foundational FSOD, a new benchmark protocol that evaluates detectors pre-trained on any external datasets and fine-tuned on multi-modal (text and visual) K-shot examples per target class. We repurpose nuImages for Foundational FSOD, benchmark several popular open-source VLMs, and provide an empirical analysis of state-of-the-art methods. Lastly, we discuss our recent CVPR 2024 Foundational FSOD competition and share insights from the community. Notably, the winning team significantly outperforms our baseline by 23.9 mAP!
Read more6/17/2024
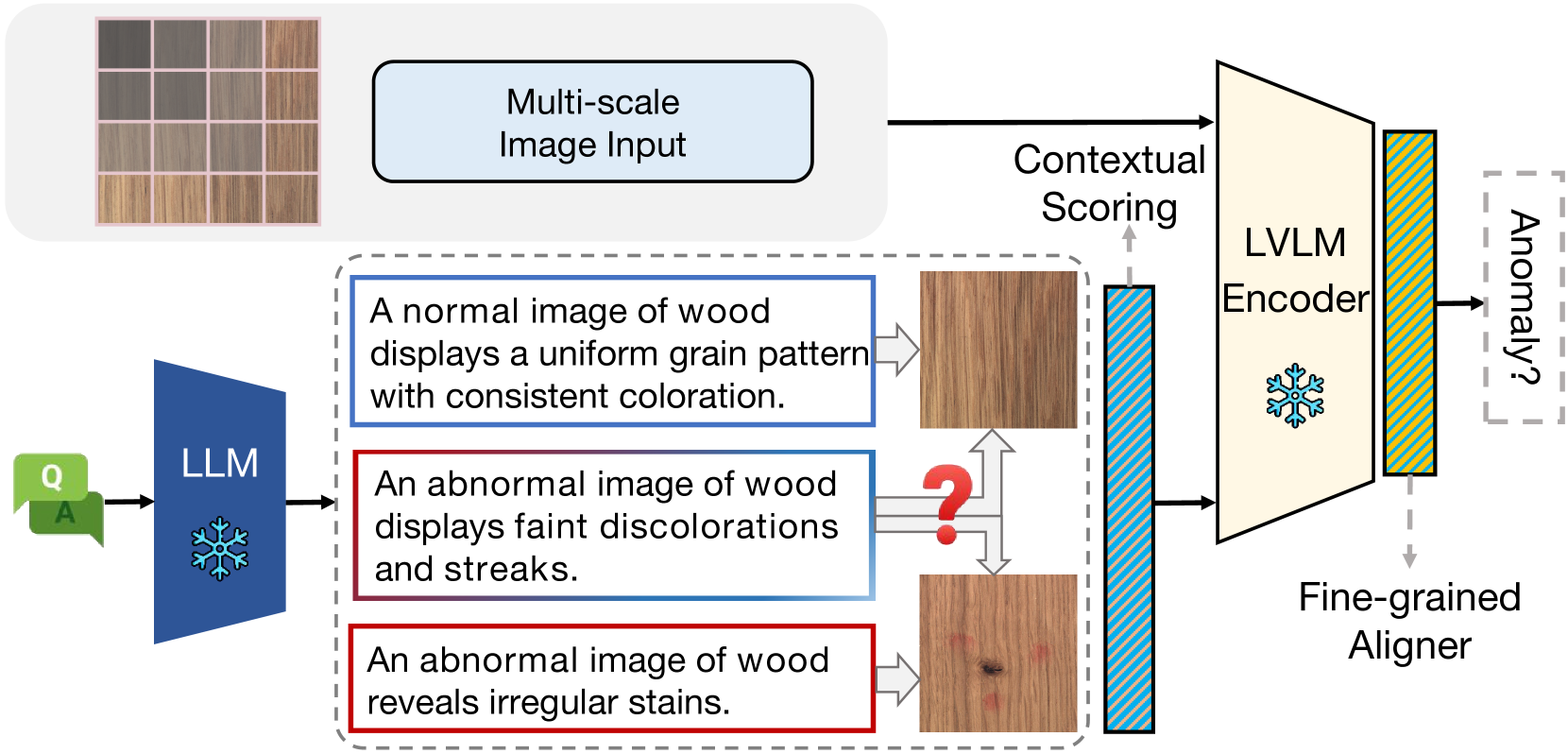
0
Do LLMs Understand Visual Anomalies? Uncovering LLM Capabilities in Zero-shot Anomaly Detection
Jiaqi Zhu, Shaofeng Cai, Fang Deng, Beng Chin Ooi, Junran Wu
Large vision-language models (LVLMs) are markedly proficient in deriving visual representations guided by natural language. Recent explorations have utilized LVLMs to tackle zero-shot visual anomaly detection (VAD) challenges by pairing images with textual descriptions indicative of normal and abnormal conditions, referred to as anomaly prompts. However, existing approaches depend on static anomaly prompts that are prone to cross-semantic ambiguity, and prioritize global image-level representations over crucial local pixel-level image-to-text alignment that is necessary for accurate anomaly localization. In this paper, we present ALFA, a training-free approach designed to address these challenges via a unified model. We propose a run-time prompt adaptation strategy, which first generates informative anomaly prompts to leverage the capabilities of a large language model (LLM). This strategy is enhanced by a contextual scoring mechanism for per-image anomaly prompt adaptation and cross-semantic ambiguity mitigation. We further introduce a novel fine-grained aligner to fuse local pixel-level semantics for precise anomaly localization, by projecting the image-text alignment from global to local semantic spaces. Extensive evaluations on MVTec and VisA datasets confirm ALFA's effectiveness in harnessing the language potential for zero-shot VAD, achieving significant PRO improvements of 12.1% on MVTec and 8.9% on VisA compared to state-of-the-art approaches.
Read more9/11/2024