Fair Minimum Representation Clustering via Integer Programming

0

Sign in to get full access
Overview
- Presents a new clustering method that aims to achieve fair representation of different groups in each cluster
- Formulates the problem as an integer programming optimization problem to find the optimal cluster assignments
- Demonstrates the method's effectiveness on real-world datasets and compares it to existing fair clustering approaches
Plain English Explanation
The paper introduces a new approach for [object Object], which is the task of grouping data points into clusters while ensuring that the representation of different demographic groups is balanced across the clusters.
The key idea is to frame the fair clustering problem as an [object Object] optimization problem, where the goal is to find the optimal assignment of data points to clusters that minimizes the overall representation deviation from a target level of fairness.
This allows the method to systematically take into account the representation of different groups and find a solution that achieves the desired level of fairness, rather than relying on heuristics or ad-hoc approaches.
The paper demonstrates the effectiveness of this [object Object] technique on several real-world datasets and compares it to existing fair clustering methods, showing improvements in terms of fairness and clustering quality.
Technical Explanation
The paper formulates the fair clustering problem as an integer programming optimization problem. The key elements are:
- A set of data points to be clustered, each with an associated group membership (e.g., demographic attributes)
- A target representation level for each group in each cluster, specified as a constraint
- An objective function that minimizes the overall deviation from the target representation levels
The integer programming problem is solved to find the optimal assignment of data points to clusters that satisfies the fairness constraints while minimizing the deviation from the target representation levels.
The paper evaluates the proposed method on several real-world datasets and compares it to existing fair clustering approaches, such as proportional fairness and fairness-quality trade-off clustering. The results demonstrate that the proposed fair minimum representation clustering method can achieve higher levels of fairness while maintaining good clustering quality.
Critical Analysis
The paper provides a rigorous and principled approach to fair clustering by formulating it as an integer programming optimization problem. This allows the method to systematically balance the representation of different groups across the clusters, which is an important consideration in many real-world applications.
However, the paper does not discuss the computational complexity of the integer programming problem, which can be challenging to solve for large-scale datasets. Additionally, the paper does not explore the sensitivity of the method to the choice of target representation levels or the impact of different fairness metrics.
Further research could investigate the scalability of the proposed method, explore alternative fairness objectives and constraints, and consider the trade-offs between fairness, clustering quality, and computational efficiency.
Conclusion
This paper presents a novel approach to fair clustering that leverages integer programming to achieve fair representation of different groups in the resulting clusters. The method demonstrates improved fairness and clustering quality compared to existing techniques, highlighting the potential of optimization-based approaches for addressing fairness in clustering problems.
The work contributes to the growing body of research on fair machine learning and provides a valuable tool for applications where ensuring equitable representation is essential.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Fair Minimum Representation Clustering via Integer Programming
Connor Lawless, Oktay Gunluk
Clustering is an unsupervised learning task that aims to partition data into a set of clusters. In many applications, these clusters correspond to real-world constructs (e.g., electoral districts, playlists, TV channels) whose benefit can only be attained by groups when they reach a minimum level of representation (e.g., 50% to elect their desired candidate). In this paper, we study the k-means and k-medians clustering problems with the additional constraint that each group (e.g., demographic group) must have a minimum level of representation in at least a given number of clusters. We formulate the problem through a mixed-integer optimization framework and present an alternating minimization algorithm, called MiniReL, that directly incorporates the fairness constraints. While incorporating the fairness criteria leads to an NP-Hard assignment problem within the algorithm, we provide computational approaches that make the algorithm practical even for large datasets. Numerical results show that the approach is able to create fairer clusters with practically no increase in the clustering cost across standard benchmark datasets.
Read more9/6/2024
0
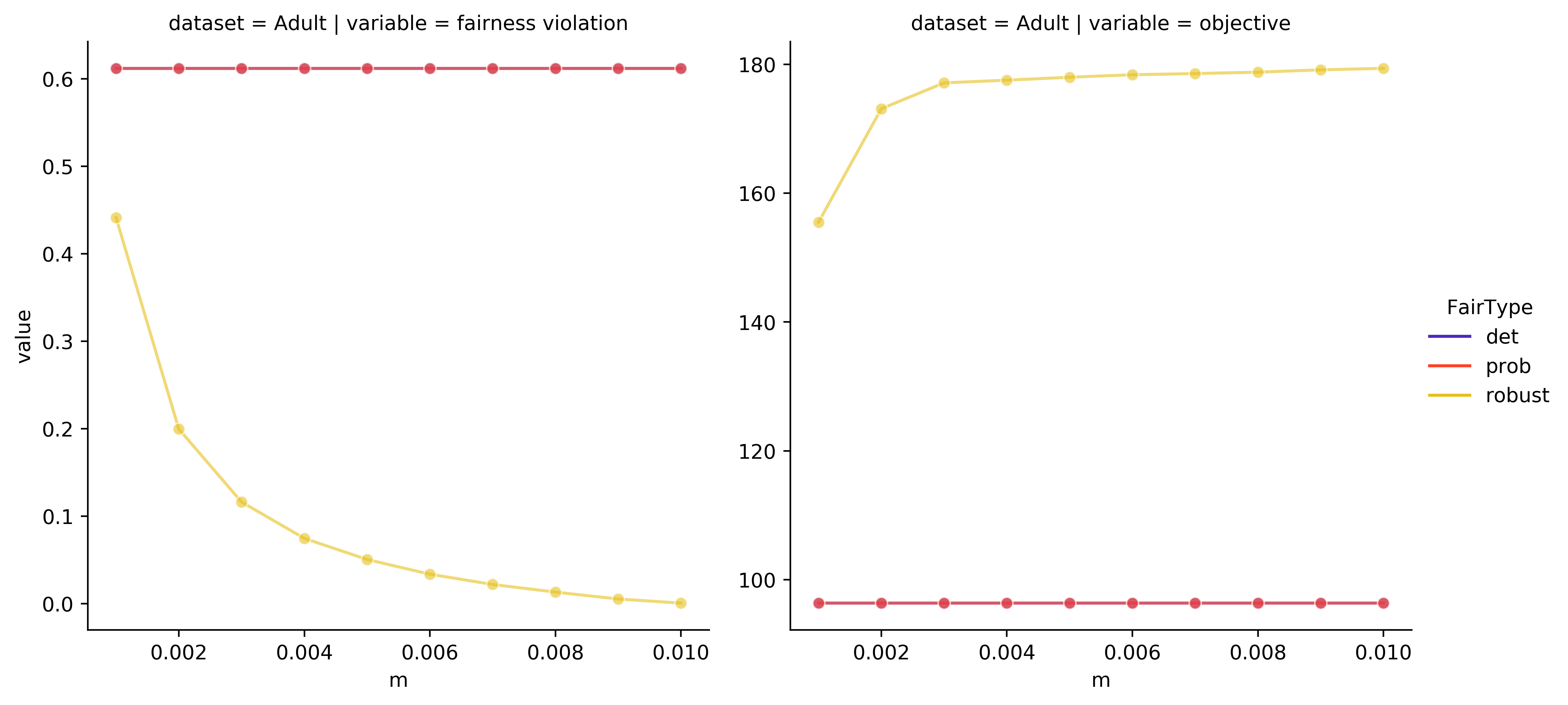
Robust Fair Clustering with Group Membership Uncertainty Sets
Sharmila Duppala, Juan Luque, John P. Dickerson, Seyed A. Esmaeili
We study the canonical fair clustering problem where each cluster is constrained to have close to population-level representation of each group. Despite significant attention, the salient issue of having incomplete knowledge about the group membership of each point has been superficially addressed. In this paper, we consider a setting where errors exist in the assigned group memberships. We introduce a simple and interpretable family of error models that require a small number of parameters to be given by the decision maker. We then present an algorithm for fair clustering with provable robustness guarantees. Our framework enables the decision maker to trade off between the robustness and the clustering quality. Unlike previous work, our algorithms are backed by worst-case theoretical guarantees. Finally, we empirically verify the performance of our algorithm on real world datasets and show its superior performance over existing baselines.
Read more6/4/2024
0
Fair Clustering: Critique, Caveats, and Future Directions
John Dickerson, Seyed A. Esmaeili, Jamie Morgenstern, Claire Jie Zhang
Clustering is a fundamental problem in machine learning and operations research. Therefore, given the fact that fairness considerations have become of paramount importance in algorithm design, fairness in clustering has received significant attention from the research community. The literature on fair clustering has resulted in a collection of interesting fairness notions and elaborate algorithms. In this paper, we take a critical view of fair clustering, identifying a collection of ignored issues such as the lack of a clear utility characterization and the difficulty in accounting for the downstream effects of a fair clustering algorithm in machine learning settings. In some cases, we demonstrate examples where the application of a fair clustering algorithm can have significant negative impacts on social welfare. We end by identifying a collection of steps that would lead towards more impactful research in fair clustering.
Read more6/26/2024
🌀
0
Proportional Fairness in Clustering: A Social Choice Perspective
Leon Kellerhals, Jannik Peters
We study the proportional clustering problem of Chen et al. [ICML'19] and relate it to the area of multiwinner voting in computational social choice. We show that any clustering satisfying a weak proportionality notion of Brill and Peters [EC'23] simultaneously obtains the best known approximations to the proportional fairness notion of Chen et al. [ICML'19], but also to individual fairness [Jung et al., FORC'20] and the core [Li et al. ICML'21]. In fact, we show that any approximation to proportional fairness is also an approximation to individual fairness and vice versa. Finally, we also study stronger notions of proportional representation, in which deviations do not only happen to single, but multiple candidate centers, and show that stronger proportionality notions of Brill and Peters [EC'23] imply approximations to these stronger guarantees.
Read more5/27/2024