FairJob: A Real-World Dataset for Fairness in Online Systems

0
Sign in to get full access
Overview
- This paper introduces FairJob, a real-world dataset for studying fairness in online hiring systems.
- The dataset includes information about job postings, applicants, and hiring decisions across multiple job platforms.
- The authors aim to provide a comprehensive resource for researchers to investigate issues of fairness and bias in online hiring.
Plain English Explanation
The paper presents a new dataset called FairJob that can be used to study fairness in online job hiring systems. Online hiring platforms have become increasingly common, but there are concerns that these systems may exhibit unfair biases in their hiring decisions. The FairJob dataset contains detailed information about job postings, applicants, and hiring outcomes across multiple real-world job platforms.
By making this dataset publicly available, the researchers hope to enable other researchers to investigate issues of fairness and bias in large-scale hiring systems. This could lead to the development of fairer and more equitable hiring practices that reduce discrimination and provide greater opportunities for job seekers from diverse backgrounds.
Technical Explanation
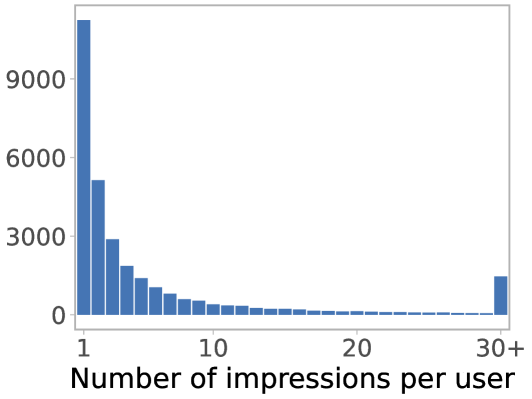
The FairJob dataset contains information on over 1 million job postings, 10 million applicants, and 500,000 hiring decisions across multiple online job platforms. The data includes details about the job postings, such as job title, description, and location, as well as information about the applicants, including demographic attributes, work experience, and application outcomes.
The authors designed the dataset to support a wide range of fairness-related research questions, such as measuring fairness in large-scale recommendation systems and studying the tradeoffs between user and item fairness in multi-sided recommendations. Researchers can use the FairJob dataset to investigate bias in hiring decisions, understand the factors that contribute to unfair outcomes, and develop techniques for improving the fairness of hiring systems.
Critical Analysis
The FairJob dataset represents a valuable resource for studying fairness in online hiring, but it also has some limitations. The data is limited to a specific set of job platforms and may not be representative of the entire online hiring landscape. Additionally, the dataset does not include information on the internal decision-making processes of the hiring platforms, which could provide important insights into the sources of bias.
Another potential concern is the extent to which the dataset can be used to draw causal conclusions about the factors that contribute to unfair hiring decisions. While the dataset provides a rich set of features, it may be challenging to disentangle the complex interplay of individual, organizational, and societal factors that shape hiring outcomes.
Despite these caveats, the FairJob dataset is a significant contribution to the growing body of research on fairness in AI systems. By making this data publicly available, the authors are encouraging a more transparent and collaborative approach to addressing these important issues.
Conclusion
The FairJob dataset represents a valuable resource for researchers and practitioners interested in studying fairness in online hiring systems. By providing a comprehensive dataset that captures real-world hiring data, the authors are enabling a deeper understanding of the factors that contribute to unfair outcomes and the development of techniques to improve the fairness of hiring algorithms.
As the use of AI and automated decision-making systems continues to grow in the domain of employment, the FairJob dataset will play a crucial role in ensuring that these systems are designed and deployed in a fair and equitable manner, providing greater opportunities for job seekers from all backgrounds.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FairJob: A Real-World Dataset for Fairness in Online Systems
Mariia Vladimirova, Federico Pavone, Eustache Diemert
We introduce a fairness-aware dataset for job recommendation in advertising, designed to foster research in algorithmic fairness within real-world scenarios. It was collected and prepared to comply with privacy standards and business confidentiality. An additional challenge is the lack of access to protected user attributes such as gender, for which we propose a solution to obtain a proxy estimate. Despite being anonymized and including a proxy for a sensitive attribute, our dataset preserves predictive power and maintains a realistic and challenging benchmark. This dataset addresses a significant gap in the availability of fairness-focused resources for high-impact domains like advertising -- the actual impact being having access or not to precious employment opportunities, where balancing fairness and utility is a common industrial challenge. We also explore various stages in the advertising process where unfairness can occur and introduce a method to compute a fair utility metric for the job recommendations in online systems case from a biased dataset. Experimental evaluations of bias mitigation techniques on the released dataset demonstrate potential improvements in fairness and the associated trade-offs with utility.
Read more7/4/2024
0
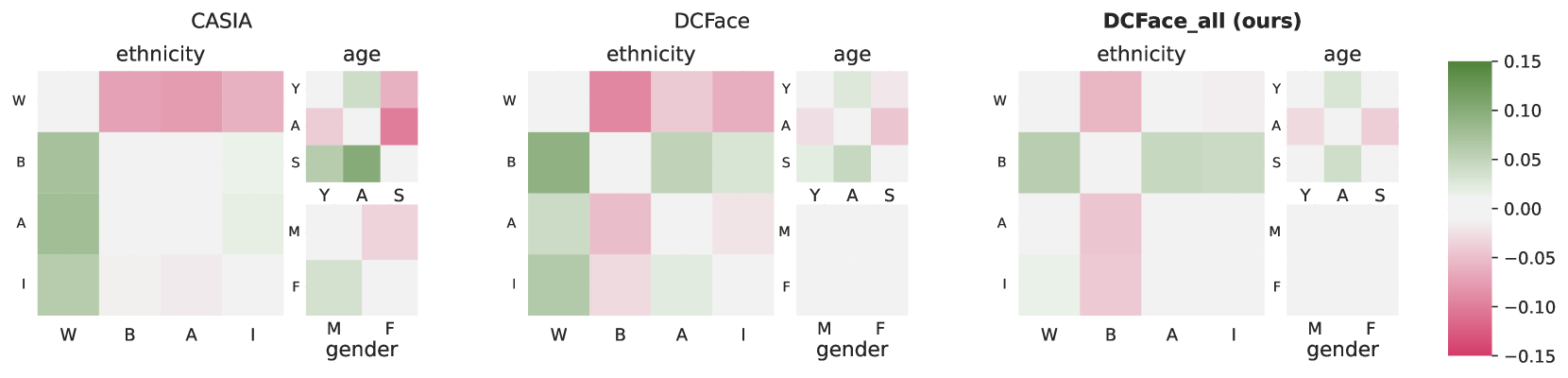
Toward Fairer Face Recognition Datasets
Alexandre Fournier-Mongieux, Michael Soumm, Adrian Popescu, Bertrand Luvison, Herv'e Le Borgne
Face recognition and verification are two computer vision tasks whose performance has progressed with the introduction of deep representations. However, ethical, legal, and technical challenges due to the sensitive character of face data and biases in real training datasets hinder their development. Generative AI addresses privacy by creating fictitious identities, but fairness problems persist. We promote fairness by introducing a demographic attributes balancing mechanism in generated training datasets. We experiment with an existing real dataset, three generated training datasets, and the balanced versions of a diffusion-based dataset. We propose a comprehensive evaluation that considers accuracy and fairness equally and includes a rigorous regression-based statistical analysis of attributes. The analysis shows that balancing reduces demographic unfairness. Also, a performance gap persists despite generation becoming more accurate with time. The proposed balancing method and comprehensive verification evaluation promote fairer and transparent face recognition and verification.
Read more6/26/2024
📊
0
Achievable Fairness on Your Data With Utility Guarantees
Muhammad Faaiz Taufiq, Jean-Francois Ton, Yang Liu
In machine learning fairness, training models that minimize disparity across different sensitive groups often leads to diminished accuracy, a phenomenon known as the fairness-accuracy trade-off. The severity of this trade-off inherently depends on dataset characteristics such as dataset imbalances or biases and therefore, using a uniform fairness requirement across diverse datasets remains questionable. To address this, we present a computationally efficient approach to approximate the fairness-accuracy trade-off curve tailored to individual datasets, backed by rigorous statistical guarantees. By utilizing the You-Only-Train-Once (YOTO) framework, our approach mitigates the computational burden of having to train multiple models when approximating the trade-off curve. Crucially, we introduce a novel methodology for quantifying uncertainty in our estimates, thereby providing practitioners with a robust framework for auditing model fairness while avoiding false conclusions due to estimation errors. Our experiments spanning tabular (e.g., Adult), image (CelebA), and language (Jigsaw) datasets underscore that our approach not only reliably quantifies the optimum achievable trade-offs across various data modalities but also helps detect suboptimality in SOTA fairness methods.
Read more5/31/2024

0
Interpolating Item and User Fairness in Multi-Sided Recommendations
Qinyi Chen, Jason Cheuk Nam Liang, Negin Golrezaei, Djallel Bouneffouf
Today's online platforms heavily lean on algorithmic recommendations for bolstering user engagement and driving revenue. However, these recommendations can impact multiple stakeholders simultaneously -- the platform, items (sellers), and users (customers) -- each with their unique objectives, making it difficult to find the right middle ground that accommodates all stakeholders. To address this, we introduce a novel fair recommendation framework, Problem (FAIR), that flexibly balances multi-stakeholder interests via a constrained optimization formulation. We next explore Problem (FAIR) in a dynamic online setting where data uncertainty further adds complexity, and propose a low-regret algorithm FORM that concurrently performs real-time learning and fair recommendations, two tasks that are often at odds. Via both theoretical analysis and a numerical case study on real-world data, we demonstrate the efficacy of our framework and method in maintaining platform revenue while ensuring desired levels of fairness for both items and users.
Read more5/28/2024