FAIRM: Learning invariant representations for algorithmic fairness and domain generalization with minimax optimality

0
Sign in to get full access
Overview
- The paper proposes a novel algorithm called FAIRM that aims to learn fair and generalizable representations for machine learning models.
- FAIRM uses a minimax optimization approach to learn representations that are invariant to changes in the data distribution, making the models more robust to domain shifts.
- The algorithm is designed to address both algorithmic fairness and domain generalization, two important challenges in real-world machine learning applications.
Plain English Explanation
FAIRM is an approach that helps machine learning models become more fair and adaptable. Imagine you have a model that's trained to make decisions, like approving loan applications. The model might work well on the data it was trained on, but if the real-world data changes, the model could start making unfair or inaccurate decisions.
FAIRM tries to solve this by learning representations of the data that are "invariant" - meaning they don't change even if the data changes. This allows the model to make fair and reliable decisions no matter what the real-world data looks like.
The key insight is that FAIRM uses a "minimax" optimization technique. This means the model is trained to be the best it can be at making decisions, while also being the least vulnerable to changes in the data. It's a bit like training a superhero - you want them to be as strong as possible, but also resilient to any threats they might face.
By learning these robust and fair representations, FAIRM-based models should be able to generalize better to new situations and make decisions that are both accurate and equitable, even as the real-world data evolves over time.
Technical Explanation
The paper proposes a new algorithm called FAIRM (Fair and Invariant Representation Learning via Minimax Optimization) that aims to learn representations for machine learning models that are both fair and generalizable across different data distributions.
At a high level, FAIRM works by formulating the representation learning problem as a minimax optimization problem. The goal is to learn a representation function that maximizes the performance of a downstream prediction task, while simultaneously minimizing the ability of an adversary to predict sensitive attributes of the data (e.g. race, gender) from the learned representations.
The minimax formulation encourages the learned representations to be invariant to changes in the data distribution, making the models more robust to domain shifts. This addresses the challenge of domain generalization, where models need to perform well on data that may differ from their training distribution.
The paper presents a detailed algorithm for optimizing the minimax objective, including the use of gradient reversal layers to train the adversary. The authors also provide theoretical analysis showing that the minimax formulation leads to representations that are both fair (in the sense of being independent of sensitive attributes) and invariant to distribution shifts.
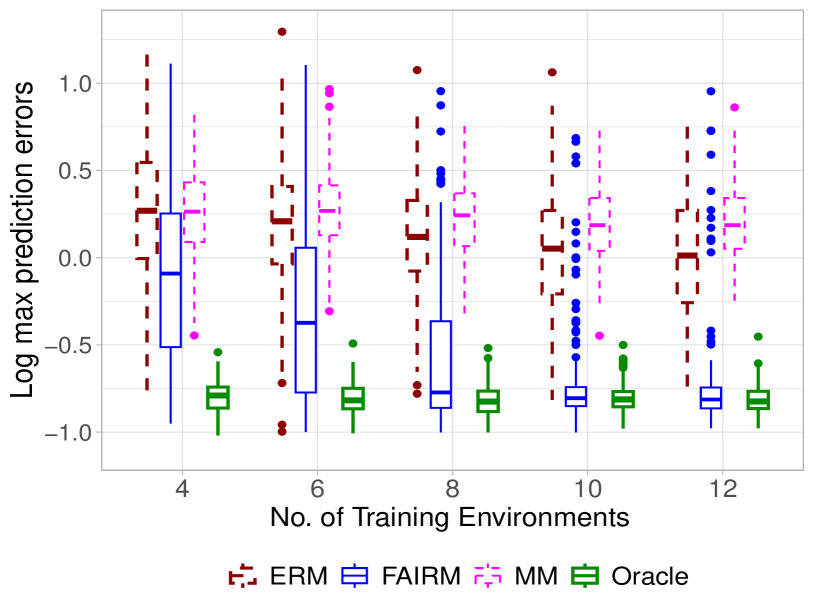
Experimental results on several benchmark datasets demonstrate that FAIRM outperforms existing methods for learning fair and generalizable representations, particularly in situations where the test distribution differs from the training distribution.
Critical Analysis
The FAIRM approach presents a promising solution for addressing the dual challenges of algorithmic fairness and domain generalization in machine learning. By learning representations that are simultaneously fair and invariant to distribution shifts, the models developed using FAIRM should be more robust and reliable in real-world deployments.
However, the paper does not fully explore the limitations and potential drawbacks of the FAIRM approach. For example, the authors do not discuss how the method might perform in situations with very limited or noisy data on sensitive attributes, which could impact the ability to learn truly fair representations.
Additionally, the theoretical analysis in the paper makes several simplifying assumptions, such as the availability of an "optimal" adversary. In practice, training the adversary component may be challenging, and the performance of FAIRM could be sensitive to hyperparameter choices or the specific architecture of the adversarial network.
Further research is also needed to understand the trade-offs between fairness and invariance, and how to best balance these competing objectives in different application domains. The paper does not explore the potential for tension between these two goals, which could be an important consideration in some real-world scenarios.
Overall, the FAIRM approach represents an important step forward in the quest for fair and generalizable machine learning models. However, its practical implementation and broader implications warrant further investigation and validation, particularly in more diverse and challenging real-world settings.
Conclusion
The FAIRM algorithm proposed in this paper is a innovative approach to addressing two critical challenges in machine learning: algorithmic fairness and domain generalization. By formulating the representation learning problem as a minimax optimization, FAIRM is able to learn representations that are both fair (independent of sensitive attributes) and invariant to changes in the data distribution.
This is a significant advancement, as it allows machine learning models to make accurate and equitable decisions, even as the real-world data they encounter evolves over time. The theoretical analysis and experimental results presented in the paper demonstrate the effectiveness of the FAIRM approach, particularly in situations where the test data differs from the training data.
While the FAIRM method shows great promise, further research is needed to fully understand its limitations and potential trade-offs. Nonetheless, this work represents an important step towards building more robust and trustworthy machine learning systems that can be reliably deployed in the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FAIRM: Learning invariant representations for algorithmic fairness and domain generalization with minimax optimality
Sai Li, Linjun Zhang
Machine learning methods often assume that the test data have the same distribution as the training data. However, this assumption may not hold due to multiple levels of heterogeneity in applications, raising issues in algorithmic fairness and domain generalization. In this work, we address the problem of fair and generalizable machine learning by invariant principles. We propose a training environment-based oracle, FAIRM, which has desirable fairness and domain generalization properties under a diversity-type condition. We then provide an empirical FAIRM with finite-sample theoretical guarantees under weak distributional assumptions. We then develop efficient algorithms to realize FAIRM in linear models and demonstrate the nonasymptotic performance with minimax optimality. We evaluate our method in numerical experiments with synthetic data and MNIST data and show that it outperforms its counterparts.
Read more4/3/2024

0
Learning Fair Invariant Representations under Covariate and Correlation Shifts Simultaneously
Dong Li, Chen Zhao, Minglai Shao, Wenjun Wang
Achieving the generalization of an invariant classifier from training domains to shifted test domains while simultaneously considering model fairness is a substantial and complex challenge in machine learning. Existing methods address the problem of fairness-aware domain generalization, focusing on either covariate shift or correlation shift, but rarely consider both at the same time. In this paper, we introduce a novel approach that focuses on learning a fairness-aware domain-invariant predictor within a framework addressing both covariate and correlation shifts simultaneously, ensuring its generalization to unknown test domains inaccessible during training. In our approach, data are first disentangled into content and style factors in latent spaces. Furthermore, fairness-aware domain-invariant content representations can be learned by mitigating sensitive information and retaining as much other information as possible. Extensive empirical studies on benchmark datasets demonstrate that our approach surpasses state-of-the-art methods with respect to model accuracy as well as both group and individual fairness.
Read more8/20/2024
↗️
0
Normalise for Fairness: A Simple Normalisation Technique for Fairness in Regression Machine Learning Problems
Mostafa M. Amin, Bjorn W. Schuller
Algorithms and Machine Learning (ML) are increasingly affecting everyday life and several decision-making processes, where ML has an advantage due to scalability or superior performance. Fairness in such applications is crucial, where models should not discriminate their results based on race, gender, or other protected groups. This is especially crucial for models affecting very sensitive topics, like interview invitation or recidivism prediction. Fairness is not commonly studied for regression problems compared to binary classification problems; hence, we present a simple, yet effective method based on normalisation (FaiReg), which minimises the impact of unfairness in regression problems, especially due to labelling bias. We present a theoretical analysis of the method, in addition to an empirical comparison against two standard methods for fairness, namely data balancing and adversarial training. We also include a hybrid formulation (FaiRegH), merging the presented method with data balancing, in an attempt to face labelling and sampling biases simultaneously. The experiments are conducted on the multimodal dataset First Impressions (FI) with various labels, namely Big-Five personality prediction and interview screening score. The results show the superior performance of diminishing the effects of unfairness better than data balancing, also without deteriorating the performance of the original problem as much as adversarial training. Fairness is evaluated based on the Equal Accuracy (EA) and Statistical Parity (SP) constraints. The experiments present a setup that enhances the fairness for several protected variables simultaneously.
Read more8/21/2024

0
AdapFair: Ensuring Continuous Fairness for Machine Learning Operations
Yinghui Huang, Zihao Tang, Xiangyu Chang
The biases and discrimination of machine learning algorithms have attracted significant attention, leading to the development of various algorithms tailored to specific contexts. However, these solutions often fall short of addressing fairness issues inherent in machine learning operations. In this paper, we present a debiasing framework designed to find an optimal fair transformation of input data that maximally preserves data predictability. A distinctive feature of our approach is its flexibility and efficiency. It can be integrated with any downstream black-box classifiers, providing continuous fairness guarantees with minimal retraining efforts, even in the face of frequent data drifts, evolving fairness requirements, and batches of similar tasks. To achieve this, we leverage the normalizing flows to enable efficient, information-preserving data transformation, ensuring that no critical information is lost during the debiasing process. Additionally, we incorporate the Wasserstein distance as the unfairness measure to guide the optimization of data transformations. Finally, we introduce an efficient optimization algorithm with closed-formed gradient computations, making our framework scalable and suitable for dynamic, real-world environments.
Read more9/24/2024