Fairness Without Demographics in Human-Centered Federated Learning
2404.19725
0
0
🌐
Abstract
Federated learning (FL) enables collaborative model training while preserving data privacy, making it suitable for decentralized human-centered AI applications. However, a significant research gap remains in ensuring fairness in these systems. Current fairness strategies in FL require knowledge of bias-creating/sensitive attributes, clashing with FL's privacy principles. Moreover, in human-centered datasets, sensitive attributes may remain latent. To tackle these challenges, we present a novel bias mitigation approach inspired by Fairness without Demographics in machine learning. The presented approach achieves fairness without needing knowledge of sensitive attributes by minimizing the top eigenvalue of the Hessian matrix during training, ensuring equitable loss landscapes across FL participants. Notably, we introduce a novel FL aggregation scheme that promotes participating models based on error rates and loss landscape curvature attributes, fostering fairness across the FL system. This work represents the first approach to attaining Fairness without Demographics in human-centered FL. Through comprehensive evaluation, our approach demonstrates effectiveness in balancing fairness and efficacy across various real-world applications, FL setups, and scenarios involving single and multiple bias-inducing factors, representing a significant advancement in human-centered FL.
Create account to get full access
Overview
- Federated learning (FL) enables collaborative model training while preserving data privacy, making it suitable for decentralized human-centered AI applications.
- However, a significant research gap remains in ensuring fairness in these systems.
- Current fairness strategies in FL require knowledge of bias-creating/sensitive attributes, clashing with FL's privacy principles.
- In human-centered datasets, sensitive attributes may remain latent, posing additional challenges.
Plain English Explanation
Federated learning (FL) is a way of training AI models that allows different organizations or individuals to collaborate without having to share their private data. This makes it well-suited for building AI systems that involve people and their personal information. However, ensuring fairness in these FL systems has proven challenging.
Existing methods for making FL systems fair typically require knowing which specific attributes or characteristics of the data are causing unfairness or biases. But this goes against the privacy-preserving principles of FL, where the goal is to avoid sharing sensitive details about the data. Additionally, in datasets related to human experiences, the attributes that are causing unfairness may not be obvious or easily identifiable.
To address these problems, the researchers in this paper have developed a new approach inspired by a machine learning technique called "Fairness without Demographics." The key idea is to achieve fairness without needing to know the sensitive attributes in the data. Instead, the method focuses on minimizing certain mathematical properties of the training process that are linked to unfairness, ensuring that the learning process is equitable across all the participants in the federated system.
The researchers also introduce a novel way of combining the models contributed by the different FL participants, based on measures of their error rates and the curvature of their loss landscapes. This helps promote fairness across the overall FL system.
Technical Explanation
The authors present a novel bias mitigation approach for federated learning (FL) that achieves fairness without requiring knowledge of sensitive attributes. Inspired by the "Fairness without Demographics" concept in machine learning, their method minimizes the top eigenvalue of the Hessian matrix during training. This ensures equitable loss landscapes across FL participants, promoting fairness without needing to identify specific bias-inducing factors.
Additionally, the researchers introduce a new FL aggregation scheme that selects participating models based on their error rates and loss landscape curvature attributes. This mechanism fosters fairness by prioritizing models that demonstrate both high performance and equitable behavior across the FL system.
Through comprehensive evaluations on real-world applications, the authors demonstrate the effectiveness of their approach in balancing fairness and efficacy across various FL setups and scenarios involving single or multiple bias-inducing factors. This work represents a significant advancement in enabling fair, human-centered FL systems, addressing a crucial gap in the field.
Critical Analysis
The proposed approach is a valuable contribution to the field of federated learning, as it addresses an important challenge in ensuring fairness without relying on explicit knowledge of sensitive attributes. This is particularly relevant for human-centered applications, where such attributes may not be readily available or easily identifiable.
However, the paper does not discuss the potential computational overhead or training complexity introduced by the additional fairness-promoting mechanisms, such as the Hessian-based optimization and the custom aggregation scheme. These factors could impact the practical implementation and scalability of the method, especially in resource-constrained or time-sensitive scenarios.
Additionally, the authors acknowledge that their approach may not be able to fully eliminate all forms of unfairness, as it primarily focuses on mitigating bias arising from the training process itself. Potential biases inherent in the data or introduced by other external factors may still persist, and further research may be needed to address these broader sources of unfairness.
Future work could explore the robustness of the method to different types of biases, its performance in more diverse and challenging datasets, and its scalability in large-scale federated learning deployments. Investigating the trade-offs between fairness, accuracy, and efficiency would also be valuable for guiding practical applications.
Conclusion
This paper presents a novel approach to achieving fairness in federated learning systems without relying on explicit knowledge of sensitive attributes. By minimizing the top eigenvalue of the Hessian matrix and introducing a fairness-aware aggregation scheme, the researchers have developed a practical solution for ensuring equitable learning outcomes across FL participants, even in human-centered applications where sensitive attributes may be latent or unknown.
This work represents a significant advancement in the field of federated learning, addressing a crucial gap in enabling fair, privacy-preserving AI systems for decentralized, real-world applications. The comprehensive evaluations and the demonstrated effectiveness across various scenarios underscore the potential impact of this research, paving the way for more inclusive and trustworthy federated learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Fair Federated Learning under Domain Skew with Local Consistency and Domain Diversity
Yuhang Chen, Wenke Huang, Mang Ye
0
0
Federated learning (FL) has emerged as a new paradigm for privacy-preserving collaborative training. Under domain skew, the current FL approaches are biased and face two fairness problems. 1) Parameter Update Conflict: data disparity among clients leads to varying parameter importance and inconsistent update directions. These two disparities cause important parameters to potentially be overwhelmed by unimportant ones of dominant updates. It consequently results in significant performance decreases for lower-performing clients. 2) Model Aggregation Bias: existing FL approaches introduce unfair weight allocation and neglect domain diversity. It leads to biased model convergence objective and distinct performance among domains. We discover a pronounced directional update consistency in Federated Learning and propose a novel framework to tackle above issues. First, leveraging the discovered characteristic, we selectively discard unimportant parameter updates to prevent updates from clients with lower performance overwhelmed by unimportant parameters, resulting in fairer generalization performance. Second, we propose a fair aggregation objective to prevent global model bias towards some domains, ensuring that the global model continuously aligns with an unbiased model. The proposed method is generic and can be combined with other existing FL methods to enhance fairness. Comprehensive experiments on Digits and Office-Caltech demonstrate the high fairness and performance of our method.
5/28/2024
👨🏫
Transferring Fairness using Multi-Task Learning with Limited Demographic Information
Carlos Aguirre, Mark Dredze
0
0
Training supervised machine learning systems with a fairness loss can improve prediction fairness across different demographic groups. However, doing so requires demographic annotations for training data, without which we cannot produce debiased classifiers for most tasks. Drawing inspiration from transfer learning methods, we investigate whether we can utilize demographic data from a related task to improve the fairness of a target task. We adapt a single-task fairness loss to a multi-task setting to exploit demographic labels from a related task in debiasing a target task and demonstrate that demographic fairness objectives transfer fairness within a multi-task framework. Additionally, we show that this approach enables intersectional fairness by transferring between two datasets with different single-axis demographics. We explore different data domains to show how our loss can improve fairness domains and tasks.
4/17/2024
Toward Fairer Face Recognition Datasets
Alexandre Fournier-Mongieux, Michael Soumm, Adrian Popescu, Bertrand Luvison, Herv'e Le Borgne
0
0
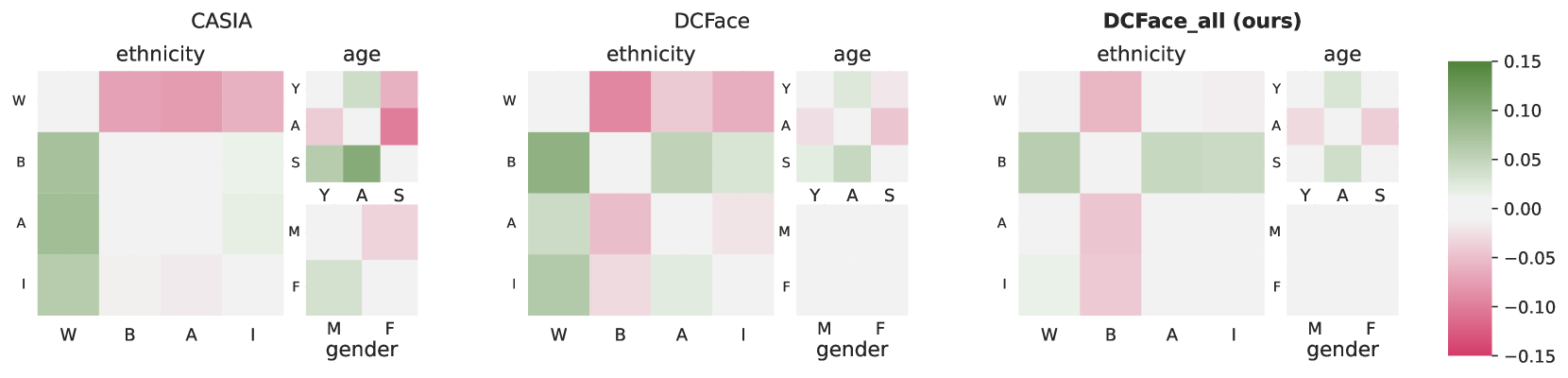
Face recognition and verification are two computer vision tasks whose performance has progressed with the introduction of deep representations. However, ethical, legal, and technical challenges due to the sensitive character of face data and biases in real training datasets hinder their development. Generative AI addresses privacy by creating fictitious identities, but fairness problems persist. We promote fairness by introducing a demographic attributes balancing mechanism in generated training datasets. We experiment with an existing real dataset, three generated training datasets, and the balanced versions of a diffusion-based dataset. We propose a comprehensive evaluation that considers accuracy and fairness equally and includes a rigorous regression-based statistical analysis of attributes. The analysis shows that balancing reduces demographic unfairness. Also, a performance gap persists despite generation becoming more accurate with time. The proposed balancing method and comprehensive verification evaluation promote fairer and transparent face recognition and verification.
6/26/2024
Fairness Without Harm: An Influence-Guided Active Sampling Approach
Jinlong Pang, Jialu Wang, Zhaowei Zhu, Yuanshun Yao, Chen Qian, Yang Liu
0
0
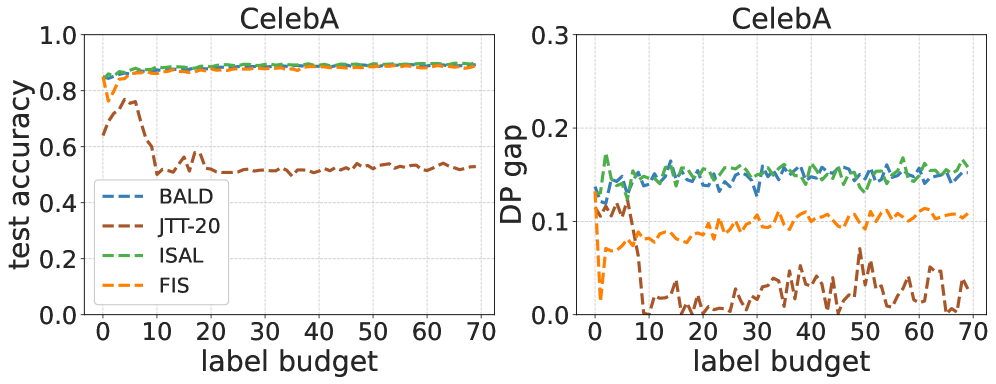
The pursuit of fairness in machine learning (ML), ensuring that the models do not exhibit biases toward protected demographic groups, typically results in a compromise scenario. This compromise can be explained by a Pareto frontier where given certain resources (e.g., data), reducing the fairness violations often comes at the cost of lowering the model accuracy. In this work, we aim to train models that mitigate group fairness disparity without causing harm to model accuracy. Intuitively, acquiring more data is a natural and promising approach to achieve this goal by reaching a better Pareto frontier of the fairness-accuracy tradeoff. The current data acquisition methods, such as fair active learning approaches, typically require annotating sensitive attributes. However, these sensitive attribute annotations should be protected due to privacy and safety concerns. In this paper, we propose a tractable active data sampling algorithm that does not rely on training group annotations, instead only requiring group annotations on a small validation set. Specifically, the algorithm first scores each new example by its influence on fairness and accuracy evaluated on the validation dataset, and then selects a certain number of examples for training. We theoretically analyze how acquiring more data can improve fairness without causing harm, and validate the possibility of our sampling approach in the context of risk disparity. We also provide the upper bound of generalization error and risk disparity as well as the corresponding connections. Extensive experiments on real-world data demonstrate the effectiveness of our proposed algorithm.
6/4/2024