Transferring Fairness using Multi-Task Learning with Limited Demographic Information
2305.12671
0
0
👨🏫
Abstract
Training supervised machine learning systems with a fairness loss can improve prediction fairness across different demographic groups. However, doing so requires demographic annotations for training data, without which we cannot produce debiased classifiers for most tasks. Drawing inspiration from transfer learning methods, we investigate whether we can utilize demographic data from a related task to improve the fairness of a target task. We adapt a single-task fairness loss to a multi-task setting to exploit demographic labels from a related task in debiasing a target task and demonstrate that demographic fairness objectives transfer fairness within a multi-task framework. Additionally, we show that this approach enables intersectional fairness by transferring between two datasets with different single-axis demographics. We explore different data domains to show how our loss can improve fairness domains and tasks.
Create account to get full access
Overview
- This paper explores how to improve the fairness of machine learning models across different demographic groups without requiring demographic annotations for the training data.
- The researchers adapt a single-task fairness loss to a multi-task setting, allowing them to leverage demographic labels from a related task to debias a target task.
- This approach enables intersectional fairness by transferring fairness between datasets with different single-axis demographics.
- The paper examines how this fairness-focused multi-task learning technique can be applied across different data domains and tasks.
Plain English Explanation
Machine learning models can sometimes make biased predictions that unfairly disadvantage certain demographic groups. To address this, researchers have developed techniques that incorporate "fairness loss" during training, which encourages the model to make more equitable predictions. However, these fairness-focused approaches require the training data to include demographic information about the individuals, which is often not available.
To overcome this limitation, the researchers in this paper took inspiration from transfer learning - a technique where knowledge from one task is used to improve performance on a related task. In this case, the researchers adapted the fairness loss to a multi-task setting, allowing them to leverage demographic labels from a related task to improve the fairness of a target task, even if the target task data does not contain that demographic information.
This multi-task fairness approach also enables intersectional fairness, where fairness is considered across multiple demographic axes (e.g., race and gender) simultaneously. The researchers demonstrate how this technique can be applied across different data domains and tasks to improve the overall fairness of machine learning systems.
Technical Explanation
The key innovation in this paper is the adaptation of a single-task fairness loss to a multi-task setting. Typically, fairness-aware training requires demographic annotations for the target task data, which are often unavailable. The researchers hypothesized that they could instead leverage demographic labels from a related task to improve the fairness of the target task predictions.
To test this, they formulated a multi-task learning objective that combines the standard task loss (e.g., classification error) with a fairness loss term. The fairness loss is computed based on the demographic labels from the related task, and this signal is used to debias the target task model, even though the target task data itself does not contain demographic information.
The researchers evaluated this approach across several datasets and tasks, including image classification and natural language processing. They found that the multi-task fairness objective was able to improve demographic parity and equal opportunity metrics compared to standard single-task training, without requiring the target task data to have demographic annotations.
Importantly, the researchers also showed that this multi-task fairness technique enables intersectional fairness - the ability to consider multiple demographic axes (e.g., race and gender) simultaneously. By transferring fairness knowledge across datasets with different single-axis demographics, their approach can promote equitable predictions for individuals belonging to various intersectional groups.
Critical Analysis
While the researchers demonstrate the effectiveness of their multi-task fairness approach, there are a few important caveats to consider. First, the success of the technique relies on the availability of a related task with relevant demographic labels. In practice, finding such a suitable auxiliary task may be challenging, especially for more specialized applications.
Additionally, the paper does not fully explore the trade-offs between fairness and other model performance metrics, such as accuracy or efficiency. It would be valuable to understand how the fairness-focused multi-task objective impacts these other important considerations, and whether there are ways to balance the competing objectives.
Finally, the paper does not address potential privacy concerns that may arise from the use of demographic information, even if it is from a related task. As machine learning systems become more ubiquitous, it will be crucial to develop fairness-improving techniques that also respect individual privacy.
Conclusion
This paper presents a novel approach to improving the fairness of machine learning models without requiring demographic annotations for the target task data. By adapting a fairness loss to a multi-task setting, the researchers were able to leverage demographic labels from a related task to debias a target task, even when the target data lacked this information.
The key contribution of this work is the ability to enable intersectional fairness, where fairness is considered across multiple demographic axes simultaneously. This is a significant advancement, as many existing fairness techniques focus on single-axis demographics, which can overlook the unique challenges faced by individuals belonging to multiple underrepresented groups.
As machine learning systems become more widely deployed, ensuring their fairness and equity across diverse populations will be crucial. The multi-task fairness approach explored in this paper represents an important step towards developing more inclusive and equitable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌐
Fairness Without Demographics in Human-Centered Federated Learning
Shaily Roy, Harshit Sharma, Asif Salekin
0
0
Federated learning (FL) enables collaborative model training while preserving data privacy, making it suitable for decentralized human-centered AI applications. However, a significant research gap remains in ensuring fairness in these systems. Current fairness strategies in FL require knowledge of bias-creating/sensitive attributes, clashing with FL's privacy principles. Moreover, in human-centered datasets, sensitive attributes may remain latent. To tackle these challenges, we present a novel bias mitigation approach inspired by Fairness without Demographics in machine learning. The presented approach achieves fairness without needing knowledge of sensitive attributes by minimizing the top eigenvalue of the Hessian matrix during training, ensuring equitable loss landscapes across FL participants. Notably, we introduce a novel FL aggregation scheme that promotes participating models based on error rates and loss landscape curvature attributes, fostering fairness across the FL system. This work represents the first approach to attaining Fairness without Demographics in human-centered FL. Through comprehensive evaluation, our approach demonstrates effectiveness in balancing fairness and efficacy across various real-world applications, FL setups, and scenarios involving single and multiple bias-inducing factors, representing a significant advancement in human-centered FL.
5/17/2024
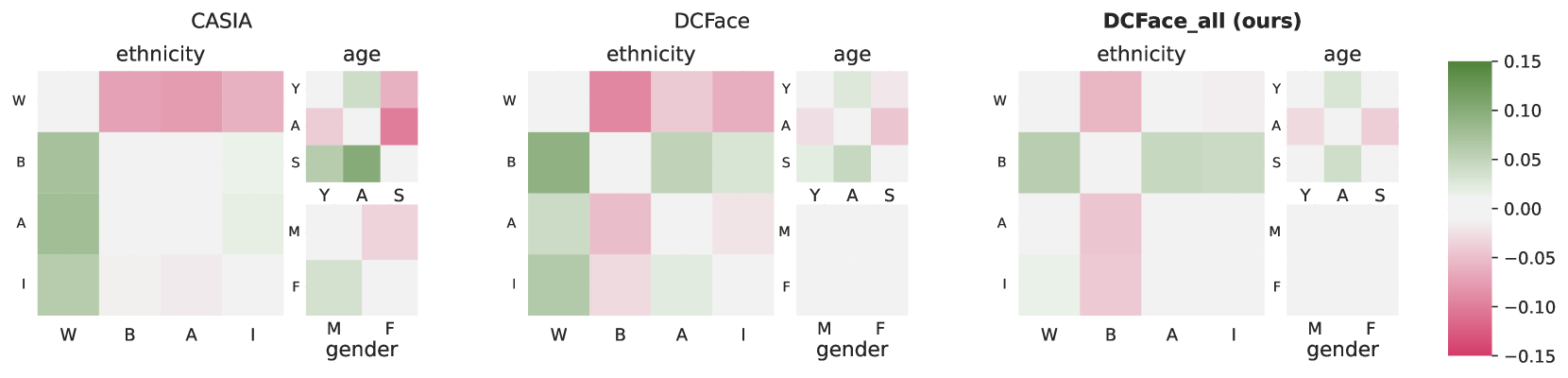
Toward Fairer Face Recognition Datasets
Alexandre Fournier-Mongieux, Michael Soumm, Adrian Popescu, Bertrand Luvison, Herv'e Le Borgne
0
0
Face recognition and verification are two computer vision tasks whose performance has progressed with the introduction of deep representations. However, ethical, legal, and technical challenges due to the sensitive character of face data and biases in real training datasets hinder their development. Generative AI addresses privacy by creating fictitious identities, but fairness problems persist. We promote fairness by introducing a demographic attributes balancing mechanism in generated training datasets. We experiment with an existing real dataset, three generated training datasets, and the balanced versions of a diffusion-based dataset. We propose a comprehensive evaluation that considers accuracy and fairness equally and includes a rigorous regression-based statistical analysis of attributes. The analysis shows that balancing reduces demographic unfairness. Also, a performance gap persists despite generation becoming more accurate with time. The proposed balancing method and comprehensive verification evaluation promote fairer and transparent face recognition and verification.
6/26/2024
🔄
DoDo Learning: DOmain-DemOgraphic Transfer in Language Models for Detecting Abuse Targeted at Public Figures
Angus R. Williams, Hannah Rose Kirk, Liam Burke, Yi-Ling Chung, Ivan Debono, Pica Johansson, Francesca Stevens, Jonathan Bright, Scott A. Hale
0
0
Public figures receive a disproportionate amount of abuse on social media, impacting their active participation in public life. Automated systems can identify abuse at scale but labelling training data is expensive, complex and potentially harmful. So, it is desirable that systems are efficient and generalisable, handling both shared and specific aspects of online abuse. We explore the dynamics of cross-group text classification in order to understand how well classifiers trained on one domain or demographic can transfer to others, with a view to building more generalisable abuse classifiers. We fine-tune language models to classify tweets targeted at public figures across DOmains (sport and politics) and DemOgraphics (women and men) using our novel DODO dataset, containing 28,000 labelled entries, split equally across four domain-demographic pairs. We find that (i) small amounts of diverse data are hugely beneficial to generalisation and model adaptation; (ii) models transfer more easily across demographics but models trained on cross-domain data are more generalisable; (iii) some groups contribute more to generalisability than others; and (iv) dataset similarity is a signal of transferability.
4/26/2024

Enhancing Fairness and Performance in Machine Learning Models: A Multi-Task Learning Approach with Monte-Carlo Dropout and Pareto Optimality
Khadija Zanna, Akane Sano
0
0
This paper considers the need for generalizable bias mitigation techniques in machine learning due to the growing concerns of fairness and discrimination in data-driven decision-making procedures across a range of industries. While many existing methods for mitigating bias in machine learning have succeeded in specific cases, they often lack generalizability and cannot be easily applied to different data types or models. Additionally, the trade-off between accuracy and fairness remains a fundamental tension in the field. To address these issues, we propose a bias mitigation method based on multi-task learning, utilizing the concept of Monte-Carlo dropout and Pareto optimality from multi-objective optimization. This method optimizes accuracy and fairness while improving the model's explainability without using sensitive information. We test this method on three datasets from different domains and show how it can deliver the most desired trade-off between model fairness and performance. This allows for tuning in specific domains where one metric may be more important than another. With the framework we introduce in this paper, we aim to enhance the fairness-performance trade-off and offer a solution to bias mitigation methods' generalizability issues in machine learning.
4/15/2024