Fair Active Learning: Solving the Labeling Problem in Insurance
2112.09466
0
0
🏅
Abstract
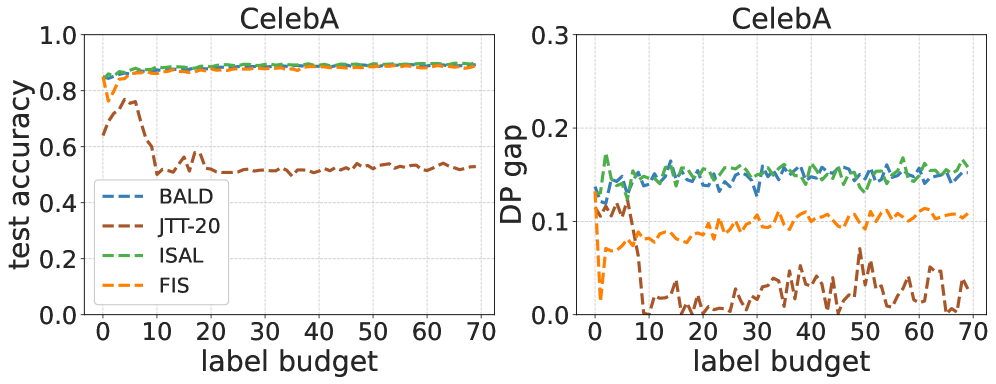
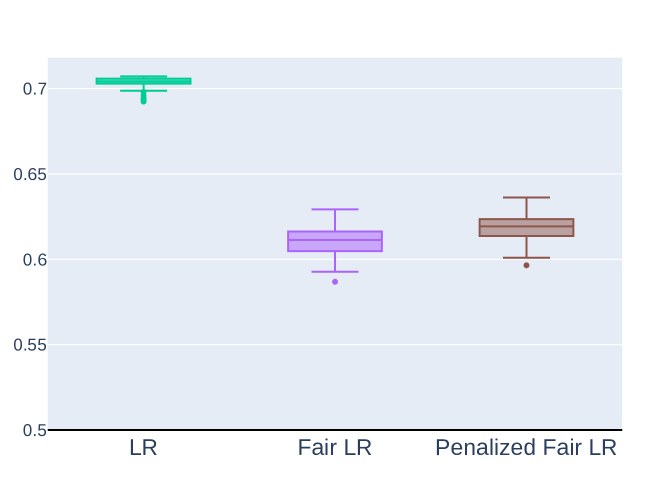
This paper addresses significant obstacles that arise from the widespread use of machine learning models in the insurance industry, with a specific focus on promoting fairness. The initial challenge lies in effectively leveraging unlabeled data in insurance while reducing the labeling effort and emphasizing data relevance through active learning techniques. The paper explores various active learning sampling methodologies and evaluates their impact on both synthetic and real insurance datasets. This analysis highlights the difficulty of achieving fair model inferences, as machine learning models may replicate biases and discrimination found in the underlying data. To tackle these interconnected challenges, the paper introduces an innovative fair active learning method. The proposed approach samples informative and fair instances, achieving a good balance between model predictive performance and fairness, as confirmed by numerical experiments on insurance datasets.
Create account to get full access
Overview
- This paper addresses significant challenges in using machine learning models in the insurance industry, with a focus on promoting fairness.
- The key issues are effectively leveraging unlabeled data, reducing labeling effort, and mitigating biases in the underlying data.
- The paper introduces an innovative "fair active learning" method to balance model performance and fairness.
Plain English Explanation
Machine learning models are increasingly used in the insurance industry, but this comes with important challenges. One major issue is how to make the most of unlabeled data - data without pre-existing labels or classifications. Making better use of unlabeled data with Bayesian active learning techniques can help reduce the labeling effort required.
Another key challenge is ensuring the fairness of these models. Machine learning models can inadvertently pick up on and amplify biases present in the training data, leading to discriminatory outcomes. This is a significant concern in sensitive domains like insurance. Addressing the fragility of active learners is crucial.
To tackle these interconnected issues, the paper introduces a novel "fair active learning" method. This approach selects informative data samples for labeling while also prioritizing fairness, helping to build machine learning models that are both accurate and unbiased. Direct deep active learning under imbalance label and classification tree-based active learning wrapper approach techniques are leveraged to achieve this balance.
Technical Explanation
The paper explores various active learning sampling methodologies and evaluates their impact on both synthetic and real insurance datasets. This analysis reveals the difficulty of achieving fair model inferences, as machine learning models may replicate biases and discrimination found in the underlying data.
To address this, the paper introduces an innovative fair active learning method. The proposed approach samples informative and fair instances, achieving a good balance between model predictive performance and fairness. This is confirmed through numerical experiments on insurance datasets, including comparisons to fair generalized linear mixed models.
Critical Analysis
The paper does a thorough job of identifying and addressing the key challenges surrounding fairness in machine learning for insurance applications. However, it would be helpful to have more discussion around the potential limitations of the proposed fair active learning method.
For example, the paper does not explore how the method might perform on datasets with more severe imbalances or complex, non-linear relationships. Additional experiments and analyses in these areas could help validate the broader applicability of the approach.
Furthermore, the paper does not delve into potential societal implications or unintended consequences of deploying such fairness-aware machine learning models in the insurance industry. These are important considerations that warrant further exploration.
Conclusion
This paper makes a valuable contribution to the growing body of research on fairness in machine learning. By introducing an innovative fair active learning technique, it provides a promising approach for building accurate and unbiased models in the insurance domain.
The insights and methods presented here have the potential to help address longstanding concerns around bias and discrimination in insurance pricing and underwriting. As machine learning continues to transform the industry, this research highlights the critical importance of proactively considering fairness throughout the model development process.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Fairness Without Harm: An Influence-Guided Active Sampling Approach
Jinlong Pang, Jialu Wang, Zhaowei Zhu, Yuanshun Yao, Chen Qian, Yang Liu
0
0
The pursuit of fairness in machine learning (ML), ensuring that the models do not exhibit biases toward protected demographic groups, typically results in a compromise scenario. This compromise can be explained by a Pareto frontier where given certain resources (e.g., data), reducing the fairness violations often comes at the cost of lowering the model accuracy. In this work, we aim to train models that mitigate group fairness disparity without causing harm to model accuracy. Intuitively, acquiring more data is a natural and promising approach to achieve this goal by reaching a better Pareto frontier of the fairness-accuracy tradeoff. The current data acquisition methods, such as fair active learning approaches, typically require annotating sensitive attributes. However, these sensitive attribute annotations should be protected due to privacy and safety concerns. In this paper, we propose a tractable active data sampling algorithm that does not rely on training group annotations, instead only requiring group annotations on a small validation set. Specifically, the algorithm first scores each new example by its influence on fairness and accuracy evaluated on the validation dataset, and then selects a certain number of examples for training. We theoretically analyze how acquiring more data can improve fairness without causing harm, and validate the possibility of our sampling approach in the context of risk disparity. We also provide the upper bound of generalization error and risk disparity as well as the corresponding connections. Extensive experiments on real-world data demonstrate the effectiveness of our proposed algorithm.
6/4/2024

AIM: Attributing, Interpreting, Mitigating Data Unfairness
Zhining Liu, Ruizhong Qiu, Zhichen Zeng, Yada Zhu, Hendrik Hamann, Hanghang Tong
0
0
Data collected in the real world often encapsulates historical discrimination against disadvantaged groups and individuals. Existing fair machine learning (FairML) research has predominantly focused on mitigating discriminative bias in the model prediction, with far less effort dedicated towards exploring how to trace biases present in the data, despite its importance for the transparency and interpretability of FairML. To fill this gap, we investigate a novel research problem: discovering samples that reflect biases/prejudices from the training data. Grounding on the existing fairness notions, we lay out a sample bias criterion and propose practical algorithms for measuring and countering sample bias. The derived bias score provides intuitive sample-level attribution and explanation of historical bias in data. On this basis, we further design two FairML strategies via sample-bias-informed minimal data editing. They can mitigate both group and individual unfairness at the cost of minimal or zero predictive utility loss. Extensive experiments and analyses on multiple real-world datasets demonstrate the effectiveness of our methods in explaining and mitigating unfairness. Code is available at https://github.com/ZhiningLiu1998/AIM.
6/19/2024
Fair Generalized Linear Mixed Models
Jan Pablo Burgard, Jo~ao Vitor Pamplona
0
0
When using machine learning for automated prediction, it is important to account for fairness in the prediction. Fairness in machine learning aims to ensure that biases in the data and model inaccuracies do not lead to discriminatory decisions. E.g., predictions from fair machine learning models should not discriminate against sensitive variables such as sexual orientation and ethnicity. The training data often in obtained from social surveys. In social surveys, oftentimes the data collection process is a strata sampling, e.g. due to cost restrictions. In strata samples, the assumption of independence between the observation is not fulfilled. Hence, if the machine learning models do not account for the strata correlations, the results may be biased. Especially high is the bias in cases where the strata assignment is correlated to the variable of interest. We present in this paper an algorithm that can handle both problems simultaneously, and we demonstrate the impact of stratified sampling on the quality of fair machine learning predictions in a reproducible simulation study.
5/24/2024

Classification Tree-based Active Learning: A Wrapper Approach
Ashna Jose, Emilie Devijver, Massih-Reza Amini, Noel Jakse, Roberta Poloni
0
0
Supervised machine learning often requires large training sets to train accurate models, yet obtaining large amounts of labeled data is not always feasible. Hence, it becomes crucial to explore active learning methods for reducing the size of training sets while maintaining high accuracy. The aim is to select the optimal subset of data for labeling from an initial unlabeled set, ensuring precise prediction of outcomes. However, conventional active learning approaches are comparable to classical random sampling. This paper proposes a wrapper active learning method for classification, organizing the sampling process into a tree structure, that improves state-of-the-art algorithms. A classification tree constructed on an initial set of labeled samples is considered to decompose the space into low-entropy regions. Input-space based criteria are used thereafter to sub-sample from these regions, the total number of points to be labeled being decomposed into each region. This adaptation proves to be a significant enhancement over existing active learning methods. Through experiments conducted on various benchmark data sets, the paper demonstrates the efficacy of the proposed framework by being effective in constructing accurate classification models, even when provided with a severely restricted labeled data set.
4/16/2024