Speech2UnifiedExpressions: Synchronous Synthesis of Co-Speech Affective Face and Body Expressions from Affordable Inputs
2406.18068
0
0

Abstract
We present a multimodal learning-based method to simultaneously synthesize co-speech facial expressions and upper-body gestures for digital characters using RGB video data captured using commodity cameras. Our approach learns from sparse face landmarks and upper-body joints, estimated directly from video data, to generate plausible emotive character motions. Given a speech audio waveform and a token sequence of the speaker's face landmark motion and body-joint motion computed from a video, our method synthesizes the motion sequences for the speaker's face landmarks and body joints to match the content and the affect of the speech. We design a generator consisting of a set of encoders to transform all the inputs into a multimodal embedding space capturing their correlations, followed by a pair of decoders to synthesize the desired face and pose motions. To enhance the plausibility of synthesis, we use an adversarial discriminator that learns to differentiate between the face and pose motions computed from the original videos and our synthesized motions based on their affective expressions. To evaluate our approach, we extend the TED Gesture Dataset to include view-normalized, co-speech face landmarks in addition to body gestures. We demonstrate the performance of our method through thorough quantitative and qualitative experiments on multiple evaluation metrics and via a user study. We observe that our method results in low reconstruction error and produces synthesized samples with diverse facial expressions and body gestures for digital characters.
Create account to get full access
Overview
- This paper proposes a system called "Speech2UnifiedExpressions" that can generate synchronized facial and body expressions from speech input.
- The system uses affordable input devices like microphones and webcams to capture speech and visual data, and then uses AI models to generate realistic co-speech expressions.
- The goal is to enable more natural and engaging virtual avatars and conversational agents that can communicate through both speech and expressive body language.
Plain English Explanation
The researchers have developed a new system that can create animated virtual characters that move and express themselves in sync with spoken language. Rather than relying on expensive motion capture equipment, this system uses affordable microphones and webcams to capture the speech and visual cues of a real person.
The AI models then analyze this input data and generate realistic facial expressions, head movements, and body gestures that match the tone and content of the speech. This allows the virtual avatar to communicate through both voice and nonverbal behaviors, creating a more natural and immersive interaction.
This technology could be used to improve the realism and engagement of virtual assistants, video game characters, and other interactive digital agents. By incorporating expressive body language, these systems can convey emotion and personality in a more human-like way, potentially enhancing the user experience. The affordable inputs and synchronous synthesis approach of this research aims to make this type of co-speech expression more accessible and scalable.
Technical Explanation
The key innovation of this work is the "Speech2UnifiedExpressions" system, which takes speech audio and visual data as input and generates synchronized facial expressions, head movements, and body gestures as output. The system consists of several deep learning models trained on datasets of human speech and body movement.
First, a speech recognition model transcribes the input audio into text. Next, a language model analyzes the text to understand the semantic content and emotional tone. This information is then fed into separate models that generate the corresponding facial, head, and body motions in a unified, synchronized manner.
The researchers experimented with different model architectures and training approaches, including using adversarial losses to improve the realism and coherence of the generated expressions. They also explored techniques to make the system work with affordable input devices rather than relying on expensive motion capture setups.
Through quantitative and qualitative evaluations, the authors demonstrate that their Speech2UnifiedExpressions system can generate high-quality, synchronized facial and body expressions from speech that are perceived as more natural and engaging by human observers.
Critical Analysis
The authors acknowledge several limitations of their work that could be addressed in future research. For example, the current system only generates expressions in response to speech, but does not model how physical movements and gestures can also influence speech and facial expressions. Incorporating bidirectional modeling of speech and body language could further improve the realism and interactivity of the virtual avatars.
Additionally, the training data used in this study was collected in a controlled lab setting, so the system's performance may degrade when applied to more natural, unconstrained conversational scenarios. Exploring ways to make the models more robust to real-world variability would be an important next step.
Finally, while the use of affordable input devices is a strength of this work, the overall system complexity and computational requirements may still limit its scalability and accessibility for some applications. Investigating more efficient or lightweight model architectures could help address these practical deployment concerns.
Conclusion
Overall, the Speech2UnifiedExpressions system represents an important step forward in enabling more natural and engaging virtual avatars and conversational agents. By generating synchronized facial and body expressions from speech input, this technology has the potential to create more immersive and human-like interactions in a wide range of applications, from virtual assistants to video games.
The researchers' focus on using affordable input devices and their exploration of various technical approaches to improve realism and coherence are particularly promising. As the field of co-speech expression continues to advance, this work could serve as a valuable foundation for further innovations in making interactive digital characters more lifelike and compelling.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Emotional Conversation: Empowering Talking Faces with Cohesive Expression, Gaze and Pose Generation
Jiadong Liang, Feng Lu
0
0
Vivid talking face generation holds immense potential applications across diverse multimedia domains, such as film and game production. While existing methods accurately synchronize lip movements with input audio, they typically ignore crucial alignments between emotion and facial cues, which include expression, gaze, and head pose. These alignments are indispensable for synthesizing realistic videos. To address these issues, we propose a two-stage audio-driven talking face generation framework that employs 3D facial landmarks as intermediate variables. This framework achieves collaborative alignment of expression, gaze, and pose with emotions through self-supervised learning. Specifically, we decompose this task into two key steps, namely speech-to-landmarks synthesis and landmarks-to-face generation. The first step focuses on simultaneously synthesizing emotionally aligned facial cues, including normalized landmarks that represent expressions, gaze, and head pose. These cues are subsequently reassembled into relocated facial landmarks. In the second step, these relocated landmarks are mapped to latent key points using self-supervised learning and then input into a pretrained model to create high-quality face images. Extensive experiments on the MEAD dataset demonstrate that our model significantly advances the state-of-the-art performance in both visual quality and emotional alignment.
6/13/2024
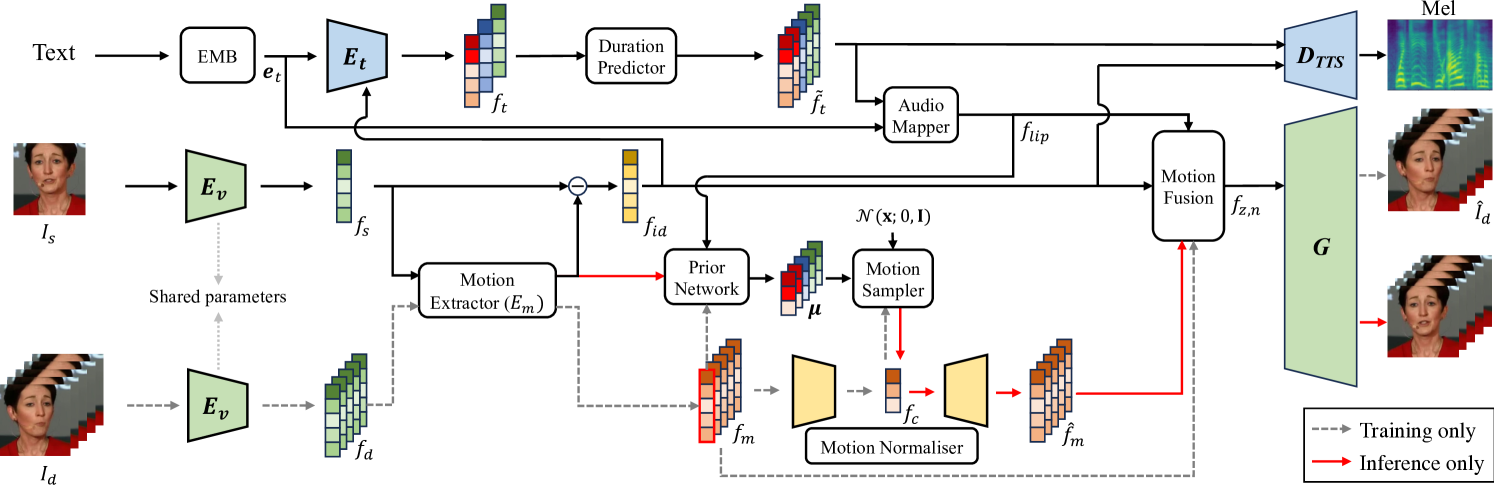
Faces that Speak: Jointly Synthesising Talking Face and Speech from Text
Youngjoon Jang, Ji-Hoon Kim, Junseok Ahn, Doyeop Kwak, Hong-Sun Yang, Yoon-Cheol Ju, Il-Hwan Kim, Byeong-Yeol Kim, Joon Son Chung
0
0
The goal of this work is to simultaneously generate natural talking faces and speech outputs from text. We achieve this by integrating Talking Face Generation (TFG) and Text-to-Speech (TTS) systems into a unified framework. We address the main challenges of each task: (1) generating a range of head poses representative of real-world scenarios, and (2) ensuring voice consistency despite variations in facial motion for the same identity. To tackle these issues, we introduce a motion sampler based on conditional flow matching, which is capable of high-quality motion code generation in an efficient way. Moreover, we introduce a novel conditioning method for the TTS system, which utilises motion-removed features from the TFG model to yield uniform speech outputs. Our extensive experiments demonstrate that our method effectively creates natural-looking talking faces and speech that accurately match the input text. To our knowledge, this is the first effort to build a multimodal synthesis system that can generalise to unseen identities.
5/17/2024
👨🏫
CSTalk: Correlation Supervised Speech-driven 3D Emotional Facial Animation Generation
Xiangyu Liang, Wenlin Zhuang, Tianyong Wang, Guangxing Geng, Guangyue Geng, Haifeng Xia, Siyu Xia
0
0
Speech-driven 3D facial animation technology has been developed for years, but its practical application still lacks expectations. The main challenges lie in data limitations, lip alignment, and the naturalness of facial expressions. Although lip alignment has seen many related studies, existing methods struggle to synthesize natural and realistic expressions, resulting in a mechanical and stiff appearance of facial animations. Even with some research extracting emotional features from speech, the randomness of facial movements limits the effective expression of emotions. To address this issue, this paper proposes a method called CSTalk (Correlation Supervised) that models the correlations among different regions of facial movements and supervises the training of the generative model to generate realistic expressions that conform to human facial motion patterns. To generate more intricate animations, we employ a rich set of control parameters based on the metahuman character model and capture a dataset for five different emotions. We train a generative network using an autoencoder structure and input an emotion embedding vector to achieve the generation of user-control expressions. Experimental results demonstrate that our method outperforms existing state-of-the-art methods.
4/30/2024
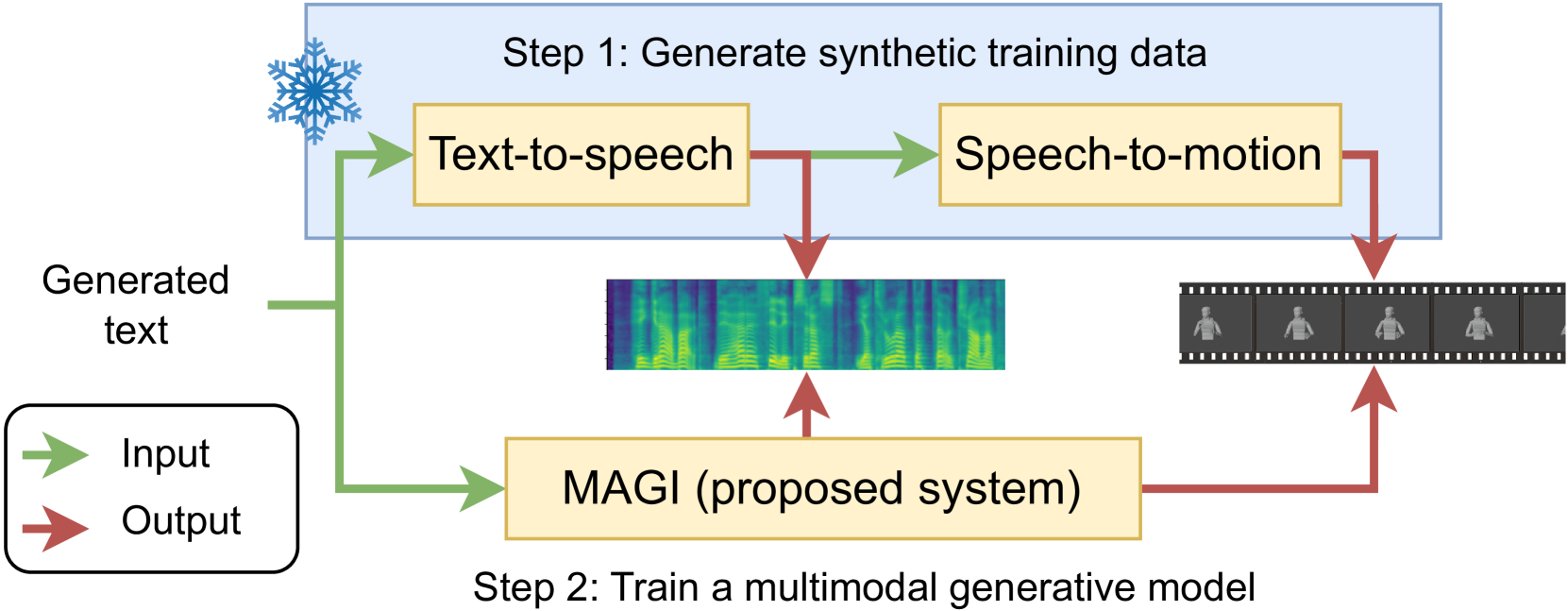
Fake it to make it: Using synthetic data to remedy the data shortage in joint multimodal speech-and-gesture synthesis
Shivam Mehta, Anna Deichler, Jim O'Regan, Birger Moell, Jonas Beskow, Gustav Eje Henter, Simon Alexanderson
0
0
Although humans engaged in face-to-face conversation simultaneously communicate both verbally and non-verbally, methods for joint and unified synthesis of speech audio and co-speech 3D gesture motion from text are a new and emerging field. These technologies hold great promise for more human-like, efficient, expressive, and robust synthetic communication, but are currently held back by the lack of suitably large datasets, as existing methods are trained on parallel data from all constituent modalities. Inspired by student-teacher methods, we propose a straightforward solution to the data shortage, by simply synthesising additional training material. Specifically, we use unimodal synthesis models trained on large datasets to create multimodal (but synthetic) parallel training data, and then pre-train a joint synthesis model on that material. In addition, we propose a new synthesis architecture that adds better and more controllable prosody modelling to the state-of-the-art method in the field. Our results confirm that pre-training on large amounts of synthetic data improves the quality of both the speech and the motion synthesised by the multimodal model, with the proposed architecture yielding further benefits when pre-trained on the synthetic data. See https://shivammehta25.github.io/MAGI/ for example output.
5/1/2024