Learning Priors for Non Rigid SfM from Casual Videos
2404.07097
0
0

Abstract
This paper addresses the long-standing challenge of reconstructing 3D structures from videos with dynamic content. Current approaches to this problem were not designed to operate on casual videos recorded by standard cameras or require a long optimization time. Aiming to significantly improve the efficiency of previous approaches, we present TracksTo4D, a learning-based approach that enables inferring 3D structure and camera positions from dynamic content originating from casual videos using a single efficient feed-forward pass. To achieve this, we propose operating directly over 2D point tracks as input and designing an architecture tailored for processing 2D point tracks. Our proposed architecture is designed with two key principles in mind: (1) it takes into account the inherent symmetries present in the input point tracks data, and (2) it assumes that the movement patterns can be effectively represented using a low-rank approximation. TracksTo4D is trained in an unsupervised way on a dataset of casual videos utilizing only the 2D point tracks extracted from the videos, without any 3D supervision. Our experiments show that TracksTo4D can reconstruct a temporal point cloud and camera positions of the underlying video with accuracy comparable to state-of-the-art methods, while drastically reducing runtime by up to 95%. We further show that TracksTo4D generalizes well to unseen videos of unseen semantic categories at inference time.
Create account to get full access
Overview
- This research paper focuses on learning priors for non-rigid structure-from-motion (SfM) from casual videos.
- The goal is to develop techniques that can accurately reconstruct 3D models from 2D video footage, even when the objects in the scene are deformable or non-rigid.
- The researchers propose a novel approach that leverages symmetries and equivariances to learn effective priors for non-rigid SfM.
Plain English Explanation
When we watch a video, our brains are able to effortlessly perceive the 3D structure of the objects and people in the scene, even if they are moving or changing shape. Researchers are trying to develop algorithms that can do the same thing - take 2D video footage and automatically reconstruct the 3D geometry of the objects.
This is a challenging problem, especially when the objects are not rigid, like a person's body or a piece of clothing. Traditional 3D reconstruction techniques often struggle in these cases. The researchers in this paper propose a new approach that learns to recognize the natural patterns and structures that exist in non-rigid objects, even in casual, everyday videos.
By training their algorithm to identify symmetries and equivariances - the ways in which an object's shape changes as it moves - they can build a set of priors, or expectations, about how non-rigid objects typically behave. This allows their 3D reconstruction model to more accurately estimate the 3D shape from the 2D video, even for deformable objects.
The key insight is that by leveraging these underlying structural regularities, the algorithm can overcome the inherent ambiguities and challenges of reconstructing 3D shape from 2D images alone. This advances the state-of-the-art in non-rigid structure-from-motion, with implications for applications like augmented reality, robotics, and video understanding.
Technical Explanation
The researchers propose a novel approach to learning priors for non-rigid structure-from-motion (SfM) from casual videos. Their key insight is that natural non-rigid objects often exhibit structural regularities in the form of symmetries and equivariances, which can be effectively leveraged as priors to improve 3D reconstruction.
Specifically, the authors develop a deep neural network architecture that can learn to recognize and exploit these symmetries and equivariances during the 3D reconstruction process. The network takes 2D video frames as input and outputs a 3D mesh representation of the non-rigid object, guided by the learned priors.
The training process involves exposing the network to a diverse set of casual videos depicting a variety of non-rigid objects, such as people, animals, and deformable surfaces. By observing how these objects' shapes change and move over time, the network learns to capture the underlying structural patterns that govern their 3D dynamics.
This learned knowledge is then incorporated into the 3D reconstruction process, allowing the network to make more accurate 3D shape estimates even from challenging, unconstrained video footage. The authors demonstrate the effectiveness of their approach through extensive experiments, showing significant improvements over state-of-the-art non-rigid SfM methods.
Critical Analysis
The paper presents a compelling approach to learning effective priors for non-rigid 3D reconstruction from video. By leveraging symmetries and equivariances, the researchers have developed a technique that can better handle the challenges of reconstructing deformable objects compared to traditional SfM methods.
One potential limitation of the work is the reliance on a diverse training dataset of casual videos. While the authors show that their approach generalizes well, it remains to be seen how it would perform on more specialized or domain-specific non-rigid objects that may exhibit different structural regularities.
Additionally, the paper does not delve into the computational complexity or real-time performance of the proposed method, which could be important considerations for certain applications, such as augmented reality or robotics.
Further research could explore ways to make the algorithm more efficient, as well as investigate its robustness to noise, occlusions, and other real-world challenges that may arise in practical deployment scenarios. Comparisons to physics-guided approaches for non-rigid reconstruction could also provide additional insights.
Conclusion
This paper presents a novel approach to learning priors for non-rigid structure-from-motion from casual videos. By leveraging the structural regularities inherent in natural non-rigid objects, the researchers have developed a technique that can more accurately reconstruct 3D models from 2D video footage.
The key innovation is the use of symmetries and equivariances as guiding principles for the 3D reconstruction process. This allows the algorithm to overcome the inherent ambiguities and challenges of non-rigid SfM, with promising results that advance the state-of-the-art in this important computer vision task.
The potential applications of this work are wide-ranging, from augmented reality and robotics to video understanding and 3D content creation. As the field of 3D reconstruction continues to evolve, techniques like the one proposed in this paper will be increasingly crucial for enabling machines to perceive and interact with the rich, dynamic 3D world around us.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
Physics-guided Shape-from-Template: Monocular Video Perception through Neural Surrogate Models
David Stotko, Nils Wandel, Reinhard Klein
0
0
3D reconstruction of dynamic scenes is a long-standing problem in computer graphics and increasingly difficult the less information is available. Shape-from-Template (SfT) methods aim to reconstruct a template-based geometry from RGB images or video sequences, often leveraging just a single monocular camera without depth information, such as regular smartphone recordings. Unfortunately, existing reconstruction methods are either unphysical and noisy or slow in optimization. To solve this problem, we propose a novel SfT reconstruction algorithm for cloth using a pre-trained neural surrogate model that is fast to evaluate, stable, and produces smooth reconstructions due to a regularizing physics simulation. Differentiable rendering of the simulated mesh enables pixel-wise comparisons between the reconstruction and a target video sequence that can be used for a gradient-based optimization procedure to extract not only shape information but also physical parameters such as stretching, shearing, or bending stiffness of the cloth. This allows to retain a precise, stable, and smooth reconstructed geometry while reducing the runtime by a factor of 400-500 compared to $phi$-SfT, a state-of-the-art physics-based SfT approach.
4/16/2024

RESFM: Robust Equivariant Multiview Structure from Motion
Fadi Khatib, Yoni Kasten, Dror Moran, Meirav Galun, Ronen Basri
0
0
Multiview Structure from Motion is a fundamental and challenging computer vision problem. A recent deep-based approach was proposed utilizing matrix equivariant architectures for the simultaneous recovery of camera pose and 3D scene structure from large image collections. This work however made the unrealistic assumption that the point tracks given as input are clean of outliers. Here we propose an architecture suited to dealing with outliers by adding an inlier/outlier classifying module that respects the model equivariance and by adding a robust bundle adjustment step. Experiments demonstrate that our method can be successfully applied in realistic settings that include large image collections and point tracks extracted with common heuristics and include many outliers.
4/23/2024

GFlow: Recovering 4D World from Monocular Video
Shizun Wang, Xingyi Yang, Qiuhong Shen, Zhenxiang Jiang, Xinchao Wang
0
0
Reconstructing 4D scenes from video inputs is a crucial yet challenging task. Conventional methods usually rely on the assumptions of multi-view video inputs, known camera parameters, or static scenes, all of which are typically absent under in-the-wild scenarios. In this paper, we relax all these constraints and tackle a highly ambitious but practical task, which we termed as AnyV4D: we assume only one monocular video is available without any camera parameters as input, and we aim to recover the dynamic 4D world alongside the camera poses. To this end, we introduce GFlow, a new framework that utilizes only 2D priors (depth and optical flow) to lift a video (3D) to a 4D explicit representation, entailing a flow of Gaussian splatting through space and time. GFlow first clusters the scene into still and moving parts, then applies a sequential optimization process that optimizes camera poses and the dynamics of 3D Gaussian points based on 2D priors and scene clustering, ensuring fidelity among neighboring points and smooth movement across frames. Since dynamic scenes always introduce new content, we also propose a new pixel-wise densification strategy for Gaussian points to integrate new visual content. Moreover, GFlow transcends the boundaries of mere 4D reconstruction; it also enables tracking of any points across frames without the need for prior training and segments moving objects from the scene in an unsupervised way. Additionally, the camera poses of each frame can be derived from GFlow, allowing for rendering novel views of a video scene through changing camera pose. By employing the explicit representation, we may readily conduct scene-level or object-level editing as desired, underscoring its versatility and power. Visit our project website at: https://littlepure2333.github.io/GFlow
5/29/2024
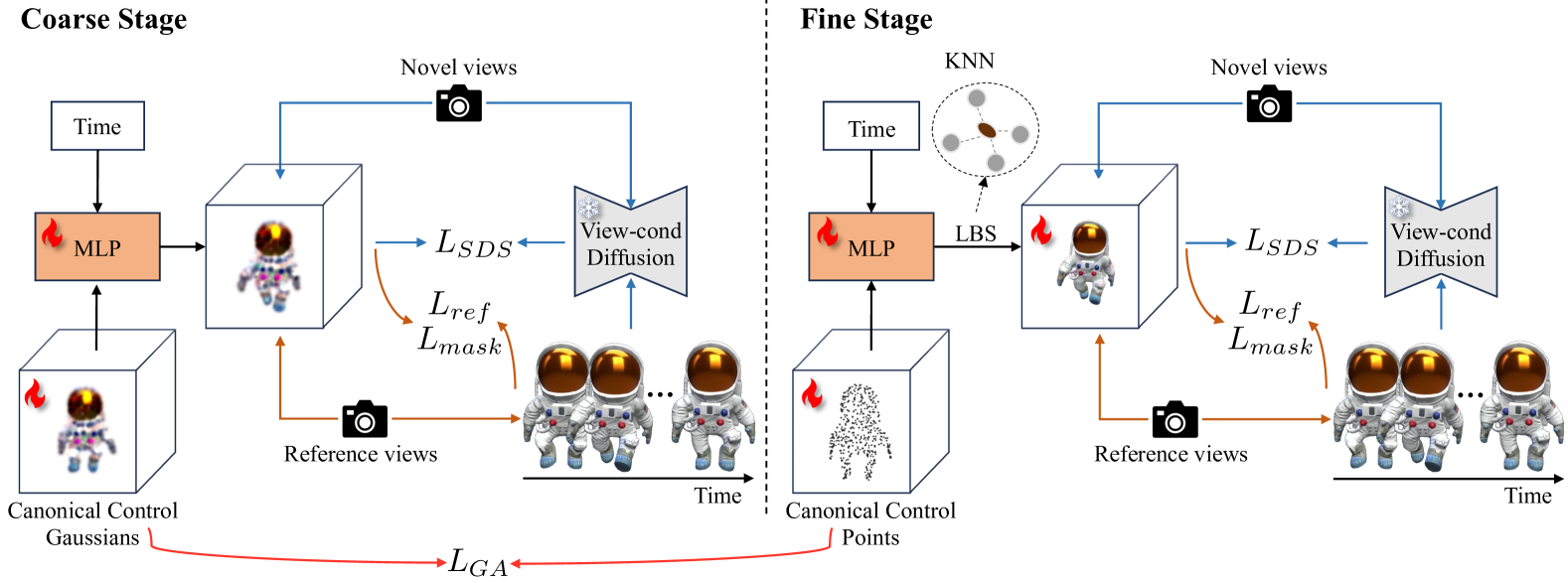
SC4D: Sparse-Controlled Video-to-4D Generation and Motion Transfer
Zijie Wu, Chaohui Yu, Yanqin Jiang, Chenjie Cao, Fan Wang, Xiang Bai
0
0
Recent advances in 2D/3D generative models enable the generation of dynamic 3D objects from a single-view video. Existing approaches utilize score distillation sampling to form the dynamic scene as dynamic NeRF or dense 3D Gaussians. However, these methods struggle to strike a balance among reference view alignment, spatio-temporal consistency, and motion fidelity under single-view conditions due to the implicit nature of NeRF or the intricate dense Gaussian motion prediction. To address these issues, this paper proposes an efficient, sparse-controlled video-to-4D framework named SC4D, that decouples motion and appearance to achieve superior video-to-4D generation. Moreover, we introduce Adaptive Gaussian (AG) initialization and Gaussian Alignment (GA) loss to mitigate shape degeneration issue, ensuring the fidelity of the learned motion and shape. Comprehensive experimental results demonstrate that our method surpasses existing methods in both quality and efficiency. In addition, facilitated by the disentangled modeling of motion and appearance of SC4D, we devise a novel application that seamlessly transfers the learned motion onto a diverse array of 4D entities according to textual descriptions.
4/8/2024