Fast, High-Quality and Parameter-Efficient Articulatory Synthesis using Differentiable DSP

0

Sign in to get full access
Overview
- This research paper presents a novel approach to articulatory speech synthesis that is fast, high-quality, and parameter-efficient.
- The key innovation is the use of differentiable digital signal processing (DSP) techniques to enable end-to-end training of the synthesis model.
- This allows the model to be optimized directly for perceptual speech quality, without the need for complex feature engineering or intermediate representations.
Plain English Explanation
The paper describes a new way to generate synthetic speech that sounds natural and realistic. The key idea is to use differentiable DSP - a technique that allows the speech synthesis model to be trained end-to-end, directly optimizing for how good the output sounds.
This is different from traditional approaches, which often rely on complex mathematical models of the human vocal tract and require a lot of manual feature engineering. By using differentiable DSP, the model can learn to produce high-quality speech without these intermediate steps, making it much more efficient and easier to train.
The result is a speech synthesis system that is fast, produces very natural-sounding audio, and requires far fewer parameters (i.e. is more compact) than previous methods. This could enable new applications like real-time speech avatars or low-power embedded devices with natural-sounding text-to-speech.
Technical Explanation
The paper introduces a novel approach to articulatory speech synthesis that leverages differentiable digital signal processing (differentiable DSP). This allows the synthesis model to be trained end-to-end, directly optimizing the perceptual quality of the output audio.
Traditional articulatory synthesis approaches rely on complex mathematical models of the human vocal tract, which require significant manual feature engineering and prior knowledge. In contrast, the differentiable DSP technique used in this work enables the model to learn the mapping from articulatory parameters to speech acoustics directly from data, without the need for these intermediate representations.
The key technical innovation is the use of differentiable waveshaping and differentiable source-filter modeling components, which can be integrated into a neural network architecture and trained using gradient-based optimization. This allows the model to be optimized end-to-end for perceptual speech quality, leading to faster, more parameter-efficient synthesis compared to prior art.
The authors demonstrate the effectiveness of their approach through extensive subjective and objective evaluations, showing that it achieves state-of-the-art performance on a range of articulatory synthesis tasks.
Critical Analysis
The paper presents a compelling technical advance in articulatory speech synthesis, with the use of differentiable DSP being a particularly notable innovation. By enabling end-to-end optimization of the synthesis model, this approach sidesteps many of the challenges associated with traditional articulatory synthesis techniques.
That said, the paper does not address some potential limitations or caveats of the proposed method. For example, it is unclear how the model would perform on tasks requiring fine-grained control over specific articulatory parameters, or how it would scale to more complex speech phenomena like coarticulation.
Additionally, the authors do not provide much insight into the internal workings of the differentiable DSP components, making it difficult to assess their generalizability or potential failure modes. Further research and analysis in this area could help build a deeper understanding of the method's strengths and weaknesses.
Overall, this work represents an important step forward in articulatory speech synthesis, with the potential to enable new applications through its combination of performance and efficiency. However, continued research and development will be needed to fully realize the potential of this approach.
Conclusion
This research paper presents a novel approach to articulatory speech synthesis that leverages differentiable digital signal processing techniques. By enabling end-to-end optimization of the synthesis model, the method achieves state-of-the-art performance in terms of speed, quality, and parameter efficiency.
The key innovation is the use of differentiable waveshaping and source-filter modeling components, which allow the model to learn the mapping from articulatory parameters to speech acoustics directly from data, without the need for complex feature engineering or intermediate representations.
The authors demonstrate the effectiveness of their approach through extensive evaluations, showing that it outperforms prior art on a range of articulatory synthesis tasks. While the paper does not address all potential limitations, this work represents an important advance in the field of speech synthesis with the potential to enable new applications in areas like real-time speech avatars and low-power embedded devices.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Fast, High-Quality and Parameter-Efficient Articulatory Synthesis using Differentiable DSP
Yisi Liu, Bohan Yu, Drake Lin, Peter Wu, Cheol Jun Cho, Gopala Krishna Anumanchipalli
Articulatory trajectories like electromagnetic articulography (EMA) provide a low-dimensional representation of the vocal tract filter and have been used as natural, grounded features for speech synthesis. Differentiable digital signal processing (DDSP) is a parameter-efficient framework for audio synthesis. Therefore, integrating low-dimensional EMA features with DDSP can significantly enhance the computational efficiency of speech synthesis. In this paper, we propose a fast, high-quality, and parameter-efficient DDSP articulatory vocoder that can synthesize speech from EMA, F0, and loudness. We incorporate several techniques to solve the harmonics / noise imbalance problem, and add a multi-resolution adversarial loss for better synthesis quality. Our model achieves a transcription word error rate (WER) of 6.67% and a mean opinion score (MOS) of 3.74, with an improvement of 1.63% and 0.16 compared to the state-of-the-art (SOTA) baseline. Our DDSP vocoder is 4.9x faster than the baseline on CPU during inference, and can generate speech of comparable quality with only 0.4M parameters, in contrast to the 9M parameters required by the SOTA.
Read more9/5/2024
0
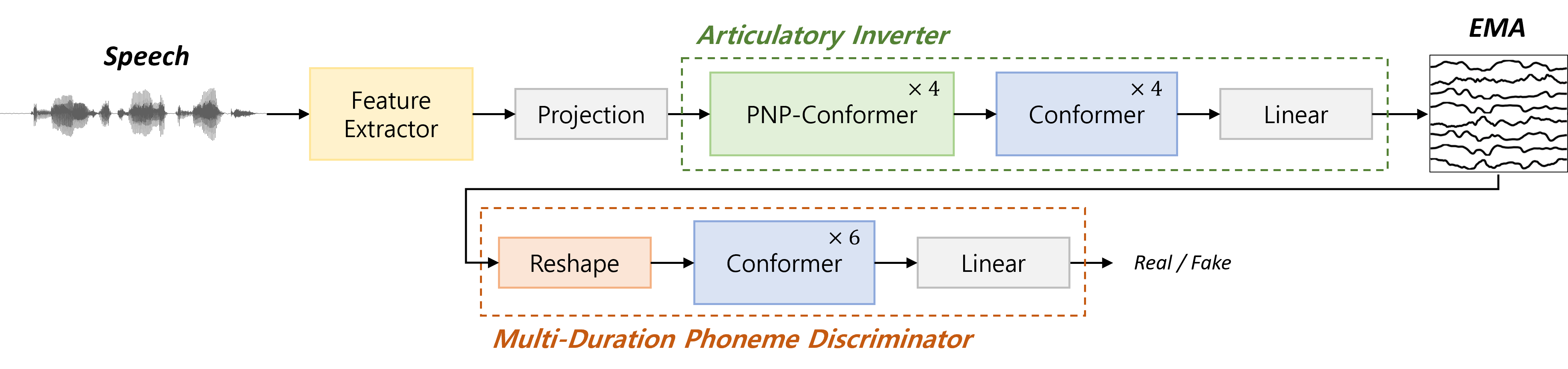
Speaker-Independent Acoustic-to-Articulatory Inversion through Multi-Channel Attention Discriminator
Woo-Jin Chung, Hong-Goo Kang
We present a novel speaker-independent acoustic-to-articulatory inversion (AAI) model, overcoming the limitations observed in conventional AAI models that rely on acoustic features derived from restricted datasets. To address these challenges, we leverage representations from a pre-trained self-supervised learning (SSL) model to more effectively estimate the global, local, and kinematic pattern information in Electromagnetic Articulography (EMA) signals during the AAI process. We train our model using an adversarial approach and introduce an attention-based Multi-duration phoneme discriminator (MDPD) designed to fully capture the intricate relationship among multi-channel articulatory signals. Our method achieves a Pearson correlation coefficient of 0.847, marking state-of-the-art performance in speaker-independent AAI models. The implementation details and code can be found online.
Read more6/26/2024
0
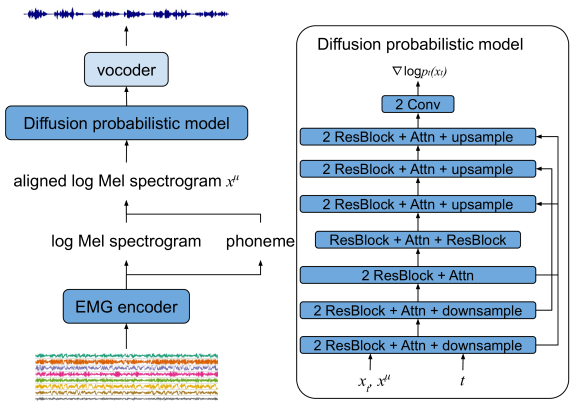
Diff-ETS: Learning a Diffusion Probabilistic Model for Electromyography-to-Speech Conversion
Zhao Ren, Kevin Scheck, Qinhan Hou, Stefano van Gogh, Michael Wand, Tanja Schultz
Electromyography-to-Speech (ETS) conversion has demonstrated its potential for silent speech interfaces by generating audible speech from Electromyography (EMG) signals during silent articulations. ETS models usually consist of an EMG encoder which converts EMG signals to acoustic speech features, and a vocoder which then synthesises the speech signals. Due to an inadequate amount of available data and noisy signals, the synthesised speech often exhibits a low level of naturalness. In this work, we propose Diff-ETS, an ETS model which uses a score-based diffusion probabilistic model to enhance the naturalness of synthesised speech. The diffusion model is applied to improve the quality of the acoustic features predicted by an EMG encoder. In our experiments, we evaluated fine-tuning the diffusion model on predictions of a pre-trained EMG encoder, and training both models in an end-to-end fashion. We compared Diff-ETS with a baseline ETS model without diffusion using objective metrics and a listening test. The results indicated the proposed Diff-ETS significantly improved speech naturalness over the baseline.
Read more5/15/2024
0
Articulatory Phonetics Informed Controllable Expressive Speech Synthesis
Zehua Kcriss Li, Meiying Melissa Chen, Yi Zhong, Pinxin Liu, Zhiyao Duan
Expressive speech synthesis aims to generate speech that captures a wide range of para-linguistic features, including emotion and articulation, though current research primarily emphasizes emotional aspects over the nuanced articulatory features mastered by professional voice actors. Inspired by this, we explore expressive speech synthesis through the lens of articulatory phonetics. Specifically, we define a framework with three dimensions: Glottalization, Tenseness, and Resonance (GTR), to guide the synthesis at the voice production level. With this framework, we record a high-quality speech dataset named GTR-Voice, featuring 20 Chinese sentences articulated by a professional voice actor across 125 distinct GTR combinations. We verify the framework and GTR annotations through automatic classification and listening tests, and demonstrate precise controllability along the GTR dimensions on two fine-tuned expressive TTS models. We open-source the dataset and TTS models.
Read more6/18/2024