Fast Multipole Attention: A Divide-and-Conquer Attention Mechanism for Long Sequences

0
📶
Sign in to get full access
Overview
- Transformer models have achieved state-of-the-art performance but struggle with long sequences due to quadratic complexity of self-attention.
- This paper proposes Fast Multipole Attention, a new attention mechanism that reduces time and memory complexity from O(n^2) to O(n log n) or O(n).
- The hierarchical approach groups queries, keys, and values into O(log n) levels of resolution, considering interactions between distant tokens at lower resolutions.
- Evaluation shows the Fast Multipole Transformer outperforms other efficient transformers in terms of memory size and accuracy.
Plain English Explanation
Transformer-based models have become very powerful and are used for many AI tasks. However, a key limitation is that the standard attention mechanism they use has a major drawback - the amount of computation and memory needed grows quadratically with the length of the input sequence. This makes it difficult to use transformers effectively on very long sequences of text or other data.
The authors of this paper introduce a new attention mechanism called Fast Multipole Attention that addresses this limitation. Instead of computing attention between every pair of tokens in the sequence, it uses a clever divide-and-conquer strategy to group tokens into a hierarchy of resolutions. Tokens that are further apart are considered at a lower, more efficient level of resolution, while nearby tokens get higher resolution attention.
This hierarchical approach reduces the computational complexity from quadratic to either linear (O(n)) or O(n log n), depending on whether the input sequence is downsampled. So the Fast Multipole Attention mechanism can handle much longer sequences without running out of memory or taking too long to compute.
The authors evaluated this new attention module on language modeling tasks and found that the resulting "Fast Multipole Transformer" model significantly outperformed other efficient transformer variants in terms of both memory usage and accuracy. This suggests the Fast Multipole Attention could be a key enabler for scaling up large language models to handle much longer input sequences and provide a more complete, contextual understanding.
Technical Explanation
The key innovation in the Fast Multipole Attention mechanism is the use of a hierarchical, divide-and-conquer strategy inspired by the Fast Multipole Method from n-body physics.
Instead of computing attention between every pair of tokens, the queries, keys, and values are grouped into a hierarchy of O(log n) resolution levels. Tokens that are further apart are represented at a lower, more efficient resolution, while nearby tokens get higher resolution attention.
The weights used to compute the group-level quantities are learned, allowing the model to adapt the level of detail to the specific task and data. This hierarchical approach reduces the time and memory complexity from the standard quadratic O(n^2) to either O(n) or O(n log n), depending on whether the queries are downsampled or not.
The authors evaluate the Fast Multipole Transformer model on autoregressive and bidirectional language modeling tasks, comparing it to other efficient attention variants. They find that the Fast Multipole Transformer outperforms these other models in terms of both memory size and accuracy, demonstrating the effectiveness of the hierarchical attention mechanism.
Critical Analysis
The authors do a thorough job of evaluating the Fast Multipole Attention mechanism and showing its advantages over other efficient attention variants. However, there are a few potential limitations and areas for further research worth considering:
-
The paper focuses on medium-sized datasets, so it's unclear how the model would scale to truly massive language models with hundreds of billions of parameters. More work may be needed to ensure the hierarchical attention mechanism remains effective at that scale.
-
The complexity analysis assumes the queries are downsampled, but the authors don't provide details on how this downsampling is done or its impact on performance. Further investigation into the tradeoffs of query downsampling would be valuable.
-
While the authors demonstrate improvements on language modeling tasks, it's uncertain how well the Fast Multipole Attention would generalize to other domains like vision or multimodal tasks. Evaluating it on a broader range of applications would help assess its broader usefulness.
-
The paper doesn't explore the interpretability of the learned attention weights at different hierarchy levels. Understanding how the model is making decisions could lead to additional insights and improvements.
Overall, the Fast Multipole Attention is a promising advance that could unlock significant improvements in the scalability and performance of large transformer models. Further research to address these potential limitations would help solidify its position as a key technique for the next generation of AI systems.
Conclusion
The Fast Multipole Attention mechanism introduced in this paper represents an important step forward in making transformer-based models more efficient and applicable to long sequences. By using a hierarchical, divide-and-conquer approach inspired by n-body physics, the authors were able to reduce the computational complexity of attention from quadratic to either linear or O(n log n).
Evaluations show the resulting Fast Multipole Transformer model outperforms other efficient attention variants, suggesting this technique could be a key enabler for scaling up large language models to handle much longer input sequences. With the ability to take the full context into account in an efficient, hierarchical manner, these models may be able to provide richer, more nuanced understanding and generation of language.
While the paper has a few limitations that warrant further investigation, the Fast Multipole Attention represents an exciting advance that could have widespread implications for the future of transformer-based AI systems. As models continue to grow in size and ambition, techniques like this will be crucial for unlocking their full potential.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📶
0
Fast Multipole Attention: A Divide-and-Conquer Attention Mechanism for Long Sequences
Yanming Kang, Giang Tran, Hans De Sterck
Transformer-based models have achieved state-of-the-art performance in many areas. However, the quadratic complexity of self-attention with respect to the input length hinders the applicability of Transformer-based models to long sequences. To address this, we present Fast Multipole Attention, a new attention mechanism that uses a divide-and-conquer strategy to reduce the time and memory complexity of attention for sequences of length $n$ from $mathcal{O}(n^2)$ to $mathcal{O}(n log n)$ or $O(n)$, while retaining a global receptive field. The hierarchical approach groups queries, keys, and values into $mathcal{O}( log n)$ levels of resolution, where groups at greater distances are increasingly larger in size and the weights to compute group quantities are learned. As such, the interaction between tokens far from each other is considered in lower resolution in an efficient hierarchical manner. The overall complexity of Fast Multipole Attention is $mathcal{O}(n)$ or $mathcal{O}(n log n)$, depending on whether the queries are down-sampled or not. This multi-level divide-and-conquer strategy is inspired by fast summation methods from $n$-body physics and the Fast Multipole Method. We perform evaluation on autoregressive and bidirectional language modeling tasks and compare our Fast Multipole Attention model with other efficient attention variants on medium-size datasets. We find empirically that the Fast Multipole Transformer performs much better than other efficient transformers in terms of memory size and accuracy. The Fast Multipole Attention mechanism has the potential to empower large language models with much greater sequence lengths, taking the full context into account in an efficient, naturally hierarchical manner during training and when generating long sequences.
Read more7/31/2024
0
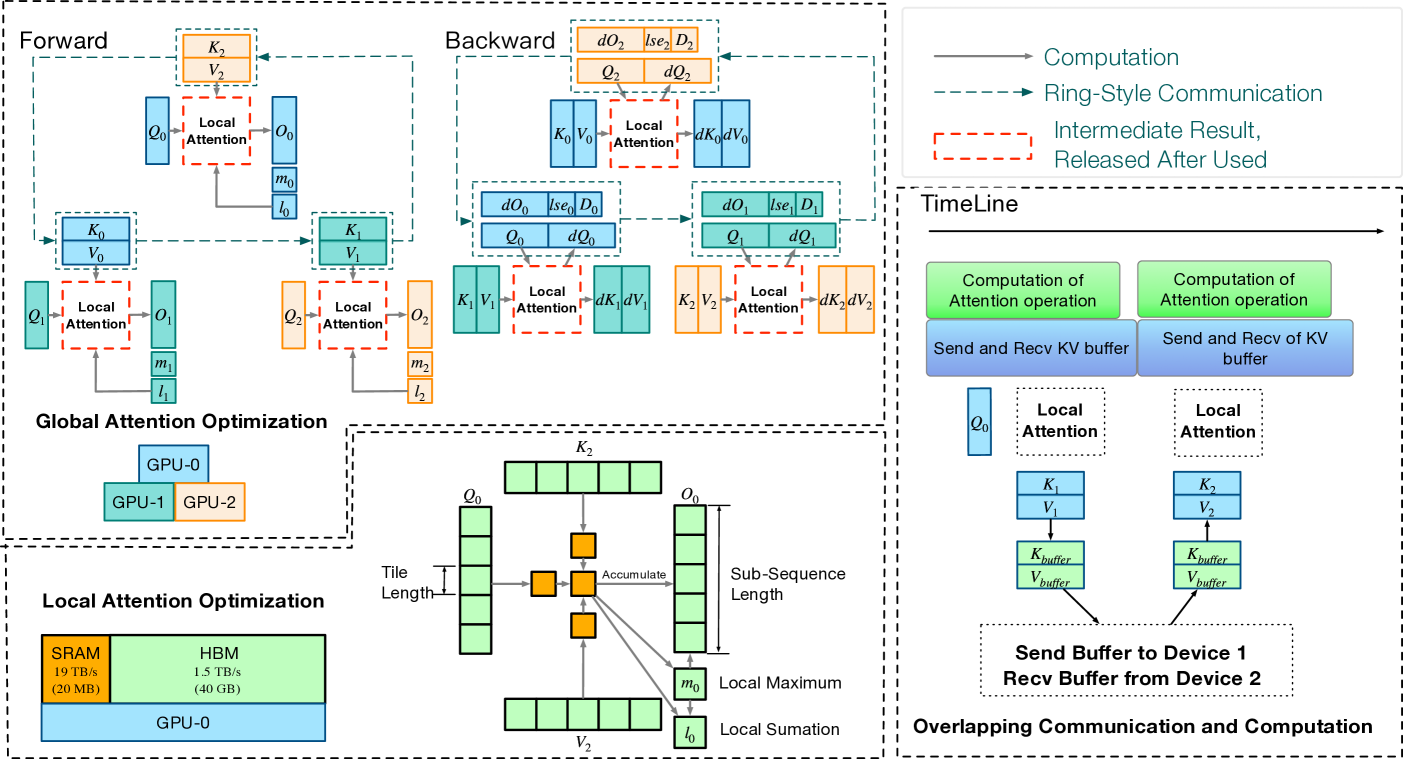
BurstAttention: An Efficient Distributed Attention Framework for Extremely Long Sequences
Ao Sun, Weilin Zhao, Xu Han, Cheng Yang, Zhiyuan Liu, Chuan Shi, Maosong Sun
Effective attention modules have played a crucial role in the success of Transformer-based large language models (LLMs), but the quadratic time and memory complexities of these attention modules also pose a challenge when processing long sequences. One potential solution for the long sequence problem is to utilize distributed clusters to parallelize the computation of attention modules across multiple devices (e.g., GPUs). However, adopting a distributed approach inevitably introduces extra memory overheads to store local attention results and incurs additional communication costs to aggregate local results into global ones. In this paper, we propose a distributed attention framework named ``BurstAttention'' to optimize memory access and communication operations at both the global cluster and local device levels. In our experiments, we compare BurstAttention with other competitive distributed attention solutions for long sequence processing. The experimental results under different length settings demonstrate that BurstAttention offers significant advantages for processing long sequences compared with these competitive baselines, reducing 40% communication overheads and achieving 1.37 X speedup during training 128K sequence length on 32 X A100.
Read more6/7/2024

0
Lean Attention: Hardware-Aware Scalable Attention Mechanism for the Decode-Phase of Transformers
Rya Sanovar, Srikant Bharadwaj, Renee St. Amant, Victor Ruhle, Saravan Rajmohan
Transformer-based models have emerged as one of the most widely used architectures for natural language processing, natural language generation, and image generation. The size of the state-of-the-art models has increased steadily reaching billions of parameters. These huge models are memory hungry and incur significant inference latency even on cutting edge AI-accelerators, such as GPUs. Specifically, the time and memory complexity of the attention operation is quadratic in terms of the total context length, i.e., prompt and output tokens. Thus, several optimizations such as key-value tensor caching and FlashAttention computation have been proposed to deliver the low latency demands of applications relying on such large models. However, these techniques do not cater to the computationally distinct nature of different phases during inference. To that end, we propose LeanAttention, a scalable technique of computing self-attention for the token-generation phase (decode-phase) of decoder-only transformer models. LeanAttention enables scaling the attention mechanism implementation for the challenging case of long context lengths by re-designing the execution flow for the decode-phase. We identify that the associative property of online softmax can be treated as a reduction operation thus allowing us to parallelize the attention computation over these large context lengths. We extend the stream-K style reduction of tiled calculation to self-attention to enable parallel computation resulting in an average of 2.6x attention execution speedup over FlashAttention-2 and up to 8.33x speedup for 512k context lengths.
Read more5/20/2024

0
FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, Tri Dao
Attention, as a core layer of the ubiquitous Transformer architecture, is the bottleneck for large language models and long-context applications. FlashAttention elaborated an approach to speed up attention on GPUs through minimizing memory reads/writes. However, it has yet to take advantage of new capabilities present in recent hardware, with FlashAttention-2 achieving only 35% utilization on the H100 GPU. We develop three main techniques to speed up attention on Hopper GPUs: exploiting asynchrony of the Tensor Cores and TMA to (1) overlap overall computation and data movement via warp-specialization and (2) interleave block-wise matmul and softmax operations, and (3) block quantization and incoherent processing that leverages hardware support for FP8 low-precision. We demonstrate that our method, FlashAttention-3, achieves speedup on H100 GPUs by 1.5-2.0$times$ with FP16 reaching up to 740 TFLOPs/s (75% utilization), and with FP8 reaching close to 1.2 PFLOPs/s. We validate that FP8 FlashAttention-3 achieves 2.6$times$ lower numerical error than a baseline FP8 attention.
Read more7/16/2024