Fast Sampling Through The Reuse Of Attention Maps In Diffusion Models
2401.01008
0
0

Abstract
Text-to-image diffusion models have demonstrated unprecedented capabilities for flexible and realistic image synthesis. Nevertheless, these models rely on a time-consuming sampling procedure, which has motivated attempts to reduce their latency. When improving efficiency, researchers often use the original diffusion model to train an additional network designed specifically for fast image generation. In contrast, our approach seeks to reduce latency directly, without any retraining, fine-tuning, or knowledge distillation. In particular, we find the repeated calculation of attention maps to be costly yet redundant, and instead suggest reusing them during sampling. Our specific reuse strategies are based on ODE theory, which implies that the later a map is reused, the smaller the distortion in the final image. We empirically compare these reuse strategies with few-step sampling procedures of comparable latency, finding that reuse generates images that are closer to those produced by the original high-latency diffusion model.
Create account to get full access
Overview
- This paper proposes a method for improving the efficiency of diffusion models, which are a type of machine learning model used for tasks like image generation and text-to-image synthesis.
- The key idea is to reuse attention maps, which are internal representations that capture the relationships between different parts of the input, to speed up the inference process.
- The authors show that this approach can significantly reduce the computational cost of running diffusion models without compromising their performance.
Plain English Explanation
Diffusion models are a powerful type of machine learning system that can be used to generate all sorts of content, from images to text. However, running these models can be computationally expensive, which can limit their real-world applications.
The researchers behind this paper found a clever way to make diffusion models run more efficiently. Their key insight was that there are certain internal representations, called "attention maps," that the models use to understand the relationships between different parts of the input. By reusing these attention maps during the inference process, the researchers were able to significantly speed up the models without sacrificing their ability to generate high-quality outputs.
This is an important contribution because it brings diffusion models one step closer to being practical for real-world use cases. By making them more efficient, the researchers have opened the door for these models to be deployed in a wider range of applications, from AI-powered art generation to faster and more accurate text-to-image synthesis.
Technical Explanation
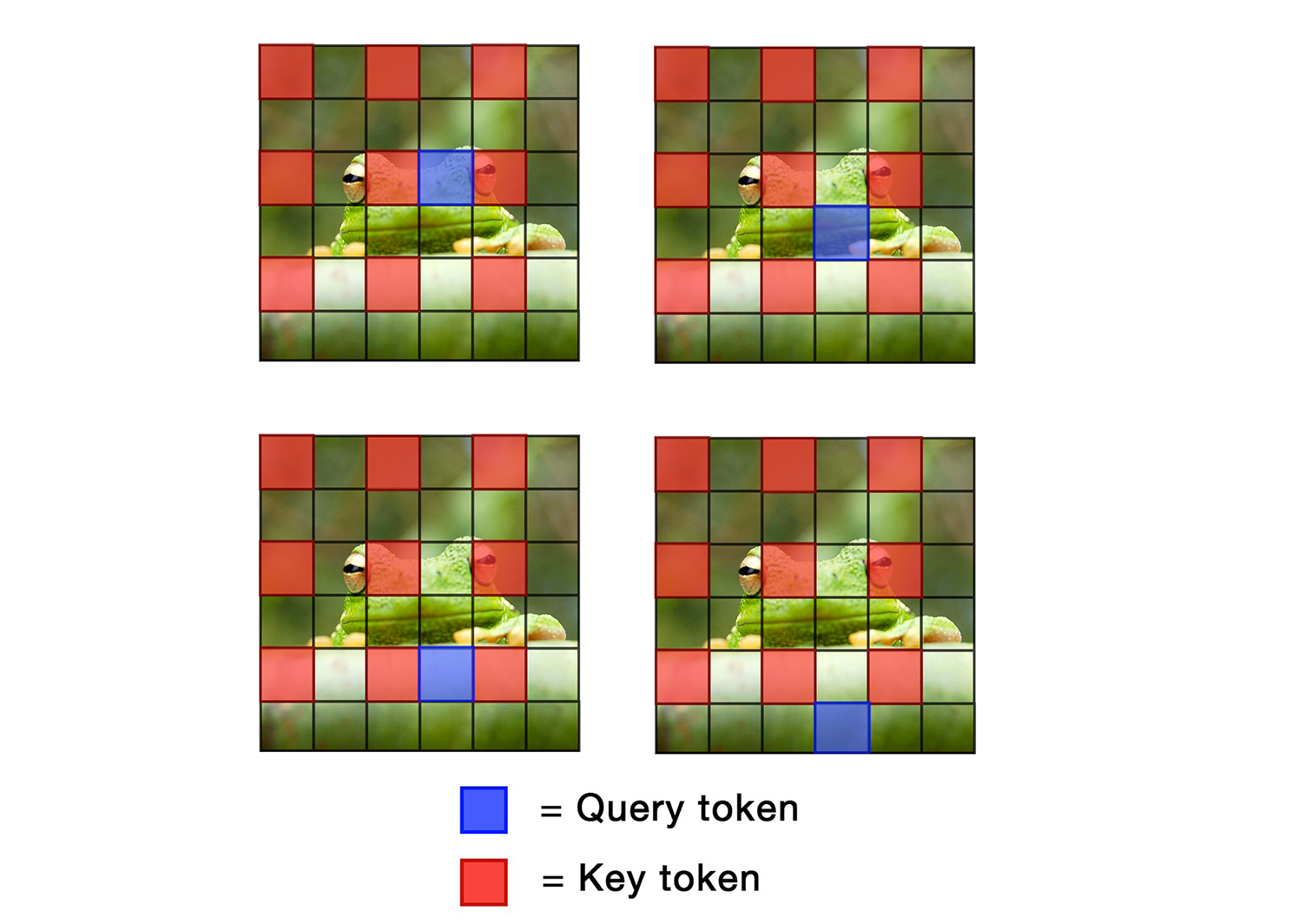
The key innovation in this paper is the idea of reusing attention maps during the inference process in diffusion models. Attention maps are internal representations that capture the relationships between different parts of the input, and they play a crucial role in the operation of diffusion models.
Typically, diffusion models generate new samples by iteratively refining an initial noisy input. This process can be computationally expensive, especially for high-resolution outputs. The researchers hypothesized that by reusing attention maps from earlier steps in the process, they could significantly reduce the computational cost without compromising the quality of the generated samples.
To test this idea, the authors developed a new diffusion model architecture that explicitly stores and reuses attention maps during inference. They compared the performance of this model to standard diffusion models on a range of image generation tasks, and found that it was able to achieve similar or better results while being much faster to run.
The authors attribute this efficiency gain to the fact that attention maps capture important structural information about the input, which can be leveraged to guide the generation process more effectively. This builds on previous work in attention-driven training methods and feature reuse techniques for diffusion models.
Critical Analysis
The researchers have presented a compelling approach for improving the efficiency of diffusion models, but there are a few potential limitations and areas for further exploration:
-
The experiments in the paper primarily focus on image generation tasks, and it's not clear how well the attention map reuse technique would generalize to other domains like text-to-image synthesis or audio generation.
-
The paper does not provide a detailed analysis of the computational and memory requirements of the proposed architecture, which would be important for understanding its real-world practicality.
-
The authors mention that their method could potentially be combined with other efficiency-boosting techniques, such as token downsampling or perturbing attention, but they don't explore these combinations in depth.
Overall, this is an interesting and promising piece of research that could have significant implications for the practical deployment of diffusion models. However, further investigation and validation of the approach across a wider range of applications and settings would be valuable.
Conclusion
In this paper, the researchers have introduced a novel technique for improving the efficiency of diffusion models by reusing attention maps during the inference process. Their results show that this approach can significantly reduce the computational cost of running these models without compromising their performance on image generation tasks.
This work is an important step forward in making diffusion models more practical for real-world applications, where computational efficiency is often a critical concern. By building on previous advances in attention-driven training and feature reuse, the authors have demonstrated the potential for further breakthroughs in this area.
As the field of machine learning continues to evolve, techniques like the one presented in this paper will become increasingly important for unlocking the full potential of powerful generative models. The authors have laid the groundwork for future research that could lead to even more efficient and versatile diffusion-based systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
ToDo: Token Downsampling for Efficient Generation of High-Resolution Images
Ethan Smith, Nayan Saxena, Aninda Saha
0
0
Attention mechanism has been crucial for image diffusion models, however, their quadratic computational complexity limits the sizes of images we can process within reasonable time and memory constraints. This paper investigates the importance of dense attention in generative image models, which often contain redundant features, making them suitable for sparser attention mechanisms. We propose a novel training-free method ToDo that relies on token downsampling of key and value tokens to accelerate Stable Diffusion inference by up to 2x for common sizes and up to 4.5x or more for high resolutions like 2048x2048. We demonstrate that our approach outperforms previous methods in balancing efficient throughput and fidelity.
5/9/2024
🧠
Perturbing Attention Gives You More Bang for the Buck: Subtle Imaging Perturbations That Efficiently Fool Customized Diffusion Models
Jingyao Xu, Yuetong Lu, Yandong Li, Siyang Lu, Dongdong Wang, Xiang Wei
0
0
Diffusion models (DMs) embark a new era of generative modeling and offer more opportunities for efficient generating high-quality and realistic data samples. However, their widespread use has also brought forth new challenges in model security, which motivates the creation of more effective adversarial attackers on DMs to understand its vulnerability. We propose CAAT, a simple but generic and efficient approach that does not require costly training to effectively fool latent diffusion models (LDMs). The approach is based on the observation that cross-attention layers exhibits higher sensitivity to gradient change, allowing for leveraging subtle perturbations on published images to significantly corrupt the generated images. We show that a subtle perturbation on an image can significantly impact the cross-attention layers, thus changing the mapping between text and image during the fine-tuning of customized diffusion models. Extensive experiments demonstrate that CAAT is compatible with diverse diffusion models and outperforms baseline attack methods in a more effective (more noise) and efficient (twice as fast as Anti-DreamBooth and Mist) manner.
6/17/2024
↗️
HiDiffusion: Unlocking Higher-Resolution Creativity and Efficiency in Pretrained Diffusion Models
Shen Zhang, Zhaowei Chen, Zhenyu Zhao, Yuhao Chen, Yao Tang, Jiajun Liang
0
0
Diffusion models have become a mainstream approach for high-resolution image synthesis. However, directly generating higher-resolution images from pretrained diffusion models will encounter unreasonable object duplication and exponentially increase the generation time. In this paper, we discover that object duplication arises from feature duplication in the deep blocks of the U-Net. Concurrently, We pinpoint the extended generation times to self-attention redundancy in U-Net's top blocks. To address these issues, we propose a tuning-free higher-resolution framework named HiDiffusion. Specifically, HiDiffusion contains Resolution-Aware U-Net (RAU-Net) that dynamically adjusts the feature map size to resolve object duplication and engages Modified Shifted Window Multi-head Self-Attention (MSW-MSA) that utilizes optimized window attention to reduce computations. we can integrate HiDiffusion into various pretrained diffusion models to scale image generation resolutions even to 4096x4096 at 1.5-6x the inference speed of previous methods. Extensive experiments demonstrate that our approach can address object duplication and heavy computation issues, achieving state-of-the-art performance on higher-resolution image synthesis tasks.
4/30/2024
✨
FRDiff : Feature Reuse for Universal Training-free Acceleration of Diffusion Models
Junhyuk So, Jungwon Lee, Eunhyeok Park
0
0
The substantial computational costs of diffusion models, especially due to the repeated denoising steps necessary for high-quality image generation, present a major obstacle to their widespread adoption. While several studies have attempted to address this issue by reducing the number of score function evaluations (NFE) using advanced ODE solvers without fine-tuning, the decreased number of denoising iterations misses the opportunity to update fine details, resulting in noticeable quality degradation. In our work, we introduce an advanced acceleration technique that leverages the temporal redundancy inherent in diffusion models. Reusing feature maps with high temporal similarity opens up a new opportunity to save computation resources without compromising output quality. To realize the practical benefits of this intuition, we conduct an extensive analysis and propose a novel method, FRDiff. FRDiff is designed to harness the advantages of both reduced NFE and feature reuse, achieving a Pareto frontier that balances fidelity and latency trade-offs in various generative tasks.
4/3/2024