Nested-TNT: Hierarchical Vision Transformers with Multi-Scale Feature Processing
2404.13434
0
0

Abstract
Transformer has been applied in the field of computer vision due to its excellent performance in natural language processing, surpassing traditional convolutional neural networks and achieving new state-of-the-art. ViT divides an image into several local patches, known as visual sentences. However, the information contained in the image is vast and complex, and focusing only on the features at the visual sentence level is not enough. The features between local patches should also be taken into consideration. In order to achieve further improvement, the TNT model is proposed, whose algorithm further divides the image into smaller patches, namely visual words, achieving more accurate results. The core of Transformer is the Multi-Head Attention mechanism, and traditional attention mechanisms ignore interactions across different attention heads. In order to reduce redundancy and improve utilization, we introduce the nested algorithm and apply the Nested-TNT to image classification tasks. The experiment confirms that the proposed model has achieved better classification performance over ViT and TNT, exceeding 2.25%, 1.1% on dataset CIFAR10 and 2.78%, 0.25% on dataset FLOWERS102 respectively.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper introduces Nested-TNT, a hierarchical vision transformer model with multi-scale feature processing
- Nested-TNT aims to improve the performance and efficiency of vision transformers by introducing a nested architecture and multi-scale feature processing
- The model achieves state-of-the-art results on standard computer vision benchmarks while being computationally efficient
Plain English Explanation
Nested-TNT is a new type of machine learning model designed for computer vision tasks like image classification. It builds on a popular architecture called the vision transformer, which has been shown to be effective for many vision problems.
The key idea behind Nested-TNT is to use a hierarchical, or "nested," structure, where the model processes the input image at multiple scales simultaneously. This allows it to capture both high-level and low-level visual features, which can lead to better performance.
Additionally, Nested-TNT includes a multi-scale feature processing module that combines information from these different scales in an intelligent way. This helps the model make more accurate predictions while also being relatively efficient in terms of computation and memory usage.
The researchers demonstrate that Nested-TNT achieves state-of-the-art results on popular computer vision benchmarks, outperforming previous vision transformer models. This suggests that the hierarchical and multi-scale design of Nested-TNT is an effective way to build powerful yet efficient vision AI systems.
Technical Explanation
The Nested-TNT architecture builds on the success of FasterViT, HSVIT, and other recent vision transformer models. Like these models, Nested-TNT uses a transformer-based backbone to process the input image.
However, Nested-TNT introduces two key innovations:
- Nested Structure: Instead of a single transformer block, Nested-TNT has a hierarchical, nested structure with multiple transformer blocks at different spatial resolutions. This allows the model to capture features at multiple scales.
- Multi-Scale Feature Processing: Nested-TNT includes a module that fuses the features from the different transformer blocks, combining information from multiple scales. This helps the model make more accurate predictions.
The researchers evaluate Nested-TNT on standard computer vision benchmarks like ImageNet classification. They show that Nested-TNT outperforms previous vision transformer models while also being more computationally efficient.
Critical Analysis
The paper provides a thorough evaluation of Nested-TNT, exploring its performance on various datasets and comparing it to state-of-the-art models like GVT, ChannelViT, and MaxViT. The results demonstrate the effectiveness of the nested structure and multi-scale feature processing.
However, the paper does not extensively discuss the limitations of Nested-TNT or potential areas for further research. For example, it would be interesting to see how the model performs on more complex or diverse datasets, or how it could be adapted for other computer vision tasks beyond classification.
Additionally, while the paper claims that Nested-TNT is computationally efficient, it would be helpful to see more detailed analysis of the model's efficiency, such as comparisons of inference time or memory usage with other vision transformer models.
Overall, the Nested-TNT model appears to be a promising advance in the field of vision transformers, but further research and analysis could help uncover its full potential and limitations.
Conclusion
The Nested-TNT paper introduces an innovative hierarchical vision transformer model that achieves state-of-the-art performance on standard computer vision benchmarks. By leveraging a nested structure and multi-scale feature processing, Nested-TNT is able to capture visual features at multiple resolutions, leading to improved accuracy.
The technical details and strong experimental results suggest that Nested-TNT represents an important step forward in the development of efficient and powerful vision AI systems. As the field of computer vision continues to evolve, models like Nested-TNT that can balance performance and computational efficiency will likely play a crucial role in enabling a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
FasterViT: Fast Vision Transformers with Hierarchical Attention
Ali Hatamizadeh, Greg Heinrich, Hongxu Yin, Andrew Tao, Jose M. Alvarez, Jan Kautz, Pavlo Molchanov
0
0
We design a new family of hybrid CNN-ViT neural networks, named FasterViT, with a focus on high image throughput for computer vision (CV) applications. FasterViT combines the benefits of fast local representation learning in CNNs and global modeling properties in ViT. Our newly introduced Hierarchical Attention (HAT) approach decomposes global self-attention with quadratic complexity into a multi-level attention with reduced computational costs. We benefit from efficient window-based self-attention. Each window has access to dedicated carrier tokens that participate in local and global representation learning. At a high level, global self-attentions enable the efficient cross-window communication at lower costs. FasterViT achieves a SOTA Pareto-front in terms of accuracy and image throughput. We have extensively validated its effectiveness on various CV tasks including classification, object detection and segmentation. We also show that HAT can be used as a plug-and-play module for existing networks and enhance them. We further demonstrate significantly faster and more accurate performance than competitive counterparts for images with high resolution. Code is available at https://github.com/NVlabs/FasterViT.
4/3/2024
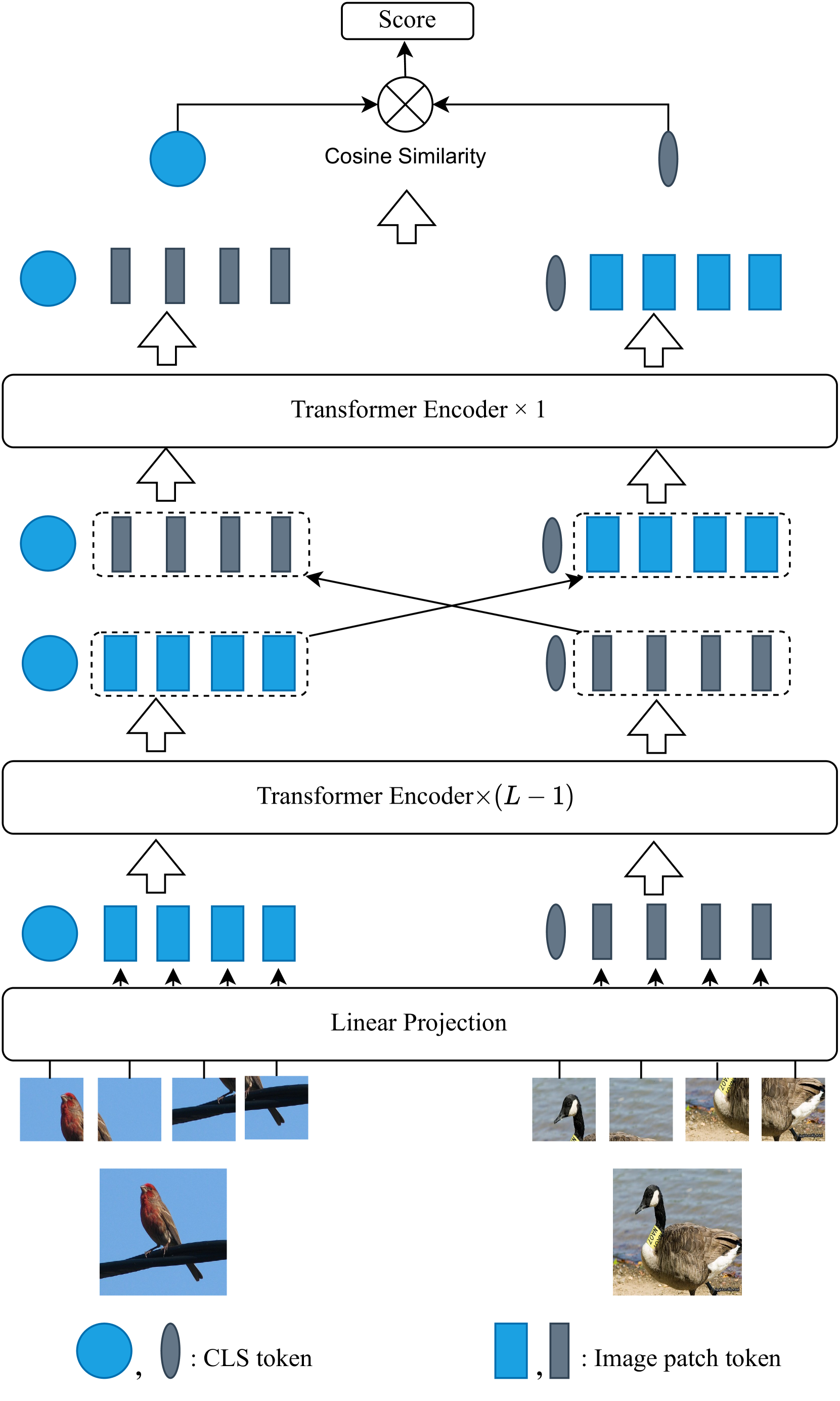
Intra-task Mutual Attention based Vision Transformer for Few-Shot Learning
Weihao Jiang, Chang Liu, Kun He
0
0
Humans possess remarkable ability to accurately classify new, unseen images after being exposed to only a few examples. Such ability stems from their capacity to identify common features shared between new and previously seen images while disregarding distractions such as background variations. However, for artificial neural network models, determining the most relevant features for distinguishing between two images with limited samples presents a challenge. In this paper, we propose an intra-task mutual attention method for few-shot learning, that involves splitting the support and query samples into patches and encoding them using the pre-trained Vision Transformer (ViT) architecture. Specifically, we swap the class (CLS) token and patch tokens between the support and query sets to have the mutual attention, which enables each set to focus on the most useful information. This facilitates the strengthening of intra-class representations and promotes closer proximity between instances of the same class. For implementation, we adopt the ViT-based network architecture and utilize pre-trained model parameters obtained through self-supervision. By leveraging Masked Image Modeling as a self-supervised training task for pre-training, the pre-trained model yields semantically meaningful representations while successfully avoiding supervision collapse. We then employ a meta-learning method to fine-tune the last several layers and CLS token modules. Our strategy significantly reduces the num- ber of parameters that require fine-tuning while effectively uti- lizing the capability of pre-trained model. Extensive experiments show that our framework is simple, effective and computationally efficient, achieving superior performance as compared to the state-of-the-art baselines on five popular few-shot classification benchmarks under the 5-shot and 1-shot scenarios
5/7/2024
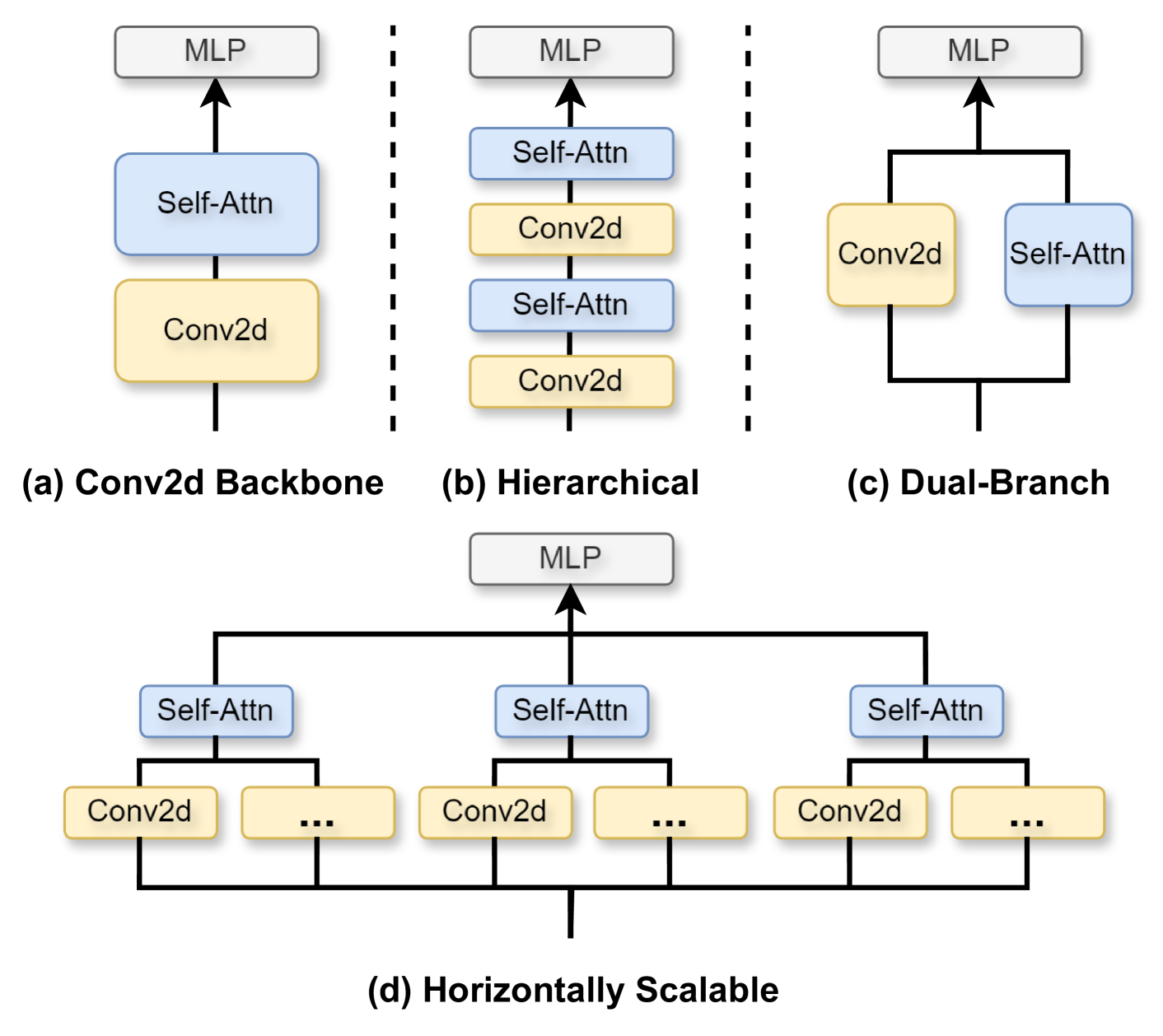
HSViT: Horizontally Scalable Vision Transformer
Chenhao Xu, Chang-Tsun Li, Chee Peng Lim, Douglas Creighton
0
0
While the Vision Transformer (ViT) architecture gains prominence in computer vision and attracts significant attention from multimedia communities, its deficiency in prior knowledge (inductive bias) regarding shift, scale, and rotational invariance necessitates pre-training on large-scale datasets. Furthermore, the growing layers and parameters in both ViT and convolutional neural networks (CNNs) impede their applicability to mobile multimedia services, primarily owing to the constrained computational resources on edge devices. To mitigate the aforementioned challenges, this paper introduces a novel horizontally scalable vision transformer (HSViT). Specifically, a novel image-level feature embedding allows ViT to better leverage the inductive bias inherent in the convolutional layers. Based on this, an innovative horizontally scalable architecture is designed, which reduces the number of layers and parameters of the models while facilitating collaborative training and inference of ViT models across multiple nodes. The experimental results depict that, without pre-training on large-scale datasets, HSViT achieves up to 10% higher top-1 accuracy than state-of-the-art schemes, ascertaining its superior preservation of inductive bias. The code is available at https://github.com/xuchenhao001/HSViT.
4/9/2024
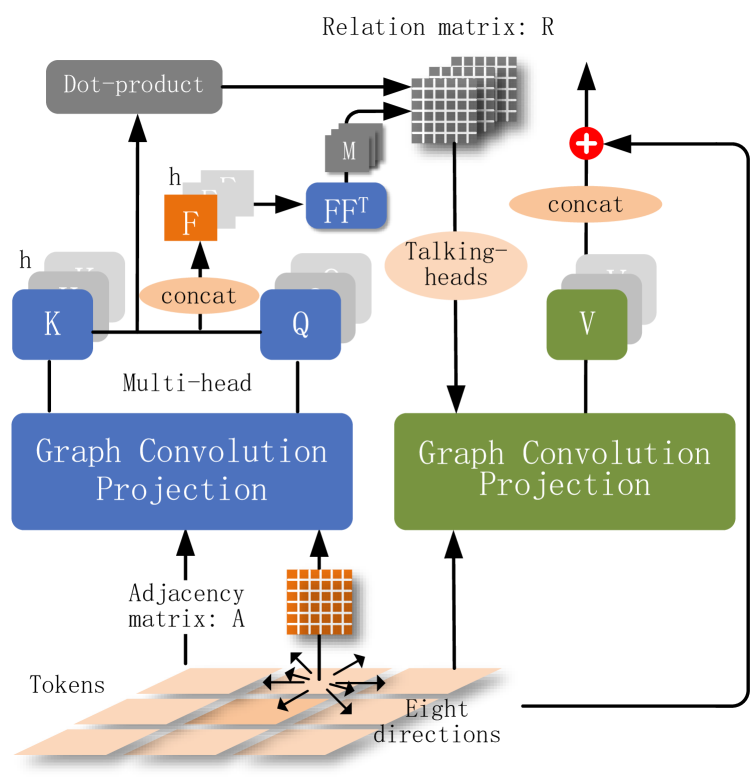
GvT: A Graph-based Vision Transformer with Talking-Heads Utilizing Sparsity, Trained from Scratch on Small Datasets
Dongjing Shan, guiqiang chen
0
0
Vision Transformers (ViTs) have achieved impressive results in large-scale image classification. However, when training from scratch on small datasets, there is still a significant performance gap between ViTs and Convolutional Neural Networks (CNNs), which is attributed to the lack of inductive bias. To address this issue, we propose a Graph-based Vision Transformer (GvT) that utilizes graph convolutional projection and graph-pooling. In each block, queries and keys are calculated through graph convolutional projection based on the spatial adjacency matrix, while dot-product attention is used in another graph convolution to generate values. When using more attention heads, the queries and keys become lower-dimensional, making their dot product an uninformative matching function. To overcome this low-rank bottleneck in attention heads, we employ talking-heads technology based on bilinear pooled features and sparse selection of attention tensors. This allows interaction among filtered attention scores and enables each attention mechanism to depend on all queries and keys. Additionally, we apply graph-pooling between two intermediate blocks to reduce the number of tokens and aggregate semantic information more effectively. Our experimental results show that GvT produces comparable or superior outcomes to deep convolutional networks and surpasses vision transformers without pre-training on large datasets. The code for our proposed model is publicly available on the website.
4/9/2024