FastLog: An End-to-End Method to Efficiently Generate and Insert Logging Statements

0
🗣️
Sign in to get full access
Overview
- Logs are crucial for software maintenance, as they allow developers to track and fix issues.
- Existing approaches to help developers write better logging statements have limitations - they either only support partial tasks or are time-consuming.
- The paper presents FastLog, a new method that can quickly generate and insert complete logging statements into code.
Plain English Explanation
Logs are like a record of everything that happens in a software program. They are essential for developers, as they can use the logs to understand what's going on, diagnose problems, and fix bugs. However, writing good logging statements is not always easy.
FastLog aims to make this task simpler and faster. It can automatically figure out where the best place is to insert a logging statement in the code, and then generate an appropriate logging statement to put there. This is useful because it saves developers time and helps ensure the logging statements are high-quality and useful.
The key idea is that FastLog uses machine learning techniques to predict where logging statements should go and what they should say. It also uses a clever trick called "text splitting" to improve the accuracy of this prediction process, even for long sections of code.
Technical Explanation
The paper presents a new tool called FastLog that can generate and insert logging statements into code in a fast and efficient manner.
FastLog works by first predicting the precise location where a logging statement should be inserted, down to the individual token level. It then generates an appropriate logging statement to place at that location. This is done using machine learning models trained on large datasets of existing logging statements.
To handle long input methods, FastLog employs a text splitting technique. This splits the input method into smaller chunks, makes predictions for each chunk, and then combines the results to determine the final logging statement placement and content.
The authors evaluated FastLog against a state-of-the-art baseline approach. They found that FastLog was significantly faster, while also producing logging statements that were rated as higher quality by human evaluators.
Critical Analysis
The paper makes a convincing case for the need to better support developers in writing high-quality logging statements. FastLog appears to be a promising solution that addresses key limitations of prior work.
However, the evaluation is limited to a specific dataset and coding tasks. More research would be needed to fully understand how well FastLog generalizes to other software projects and logging practices.
Additionally, the paper does not explore potential downsides or unintended consequences of automating logging statement generation. There may be cases where human judgment is still important, and over-reliance on an automated tool could potentially lead to suboptimal logging.
Further research could also investigate ways to make the FastLog tool more transparent and interpretable, so developers can better understand its decision-making process.
Conclusion
The FastLog approach presented in this paper offers an efficient and effective way to assist developers in generating and inserting logging statements. By automating this task, it has the potential to save developers time and improve the overall quality of logging in software systems.
While more research is needed to fully understand the limitations and broader implications, FastLog represents an important step forward in supporting developers with this crucial aspect of software maintenance and development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
0
FastLog: An End-to-End Method to Efficiently Generate and Insert Logging Statements
Xiaoyuan Xie, Zhipeng Cai, Songqiang Chen, Jifeng Xuan
Logs play a crucial role in modern software systems, serving as a means for developers to record essential information for future software maintenance. As the performance of these log-based maintenance tasks heavily relies on the quality of logging statements, various works have been proposed to assist developers in writing appropriate logging statements. However, these works either only support developers in partial sub-tasks of this whole activity; or perform with a relatively high time cost and may introduce unwanted modifications. To address their limitations, we propose FastLog, which can support the complete logging statement generation and insertion activity, in a very speedy manner. Specifically, given a program method, FastLog first predicts the insertion position in the finest token level, and then generates a complete logging statement to insert. We further use text splitting for long input texts to improve the accuracy of predicting where to insert logging statements. A comprehensive empirical analysis shows that our method outperforms the state-of-the-art approach in both efficiency and output quality, which reveals its great potential and practicality in current real-time intelligent development environments.
Read more4/1/2024

0
LogParser-LLM: Advancing Efficient Log Parsing with Large Language Models
Aoxiao Zhong, Dengyao Mo, Guiyang Liu, Jinbu Liu, Qingda Lu, Qi Zhou, Jiesheng Wu, Quanzheng Li, Qingsong Wen
Logs are ubiquitous digital footprints, playing an indispensable role in system diagnostics, security analysis, and performance optimization. The extraction of actionable insights from logs is critically dependent on the log parsing process, which converts raw logs into structured formats for downstream analysis. Yet, the complexities of contemporary systems and the dynamic nature of logs pose significant challenges to existing automatic parsing techniques. The emergence of Large Language Models (LLM) offers new horizons. With their expansive knowledge and contextual prowess, LLMs have been transformative across diverse applications. Building on this, we introduce LogParser-LLM, a novel log parser integrated with LLM capabilities. This union seamlessly blends semantic insights with statistical nuances, obviating the need for hyper-parameter tuning and labeled training data, while ensuring rapid adaptability through online parsing. Further deepening our exploration, we address the intricate challenge of parsing granularity, proposing a new metric and integrating human interactions to allow users to calibrate granularity to their specific needs. Our method's efficacy is empirically demonstrated through evaluations on the Loghub-2k and the large-scale LogPub benchmark. In evaluations on the LogPub benchmark, involving an average of 3.6 million logs per dataset across 14 datasets, our LogParser-LLM requires only 272.5 LLM invocations on average, achieving a 90.6% F1 score for grouping accuracy and an 81.1% for parsing accuracy. These results demonstrate the method's high efficiency and accuracy, outperforming current state-of-the-art log parsers, including pattern-based, neural network-based, and existing LLM-enhanced approaches.
Read more8/27/2024
❗
0
On the Effectiveness of Log Representation for Log-based Anomaly Detection
Xingfang Wu, Heng Li, Foutse Khomh
Logs are an essential source of information for people to understand the running status of a software system. Due to the evolving modern software architecture and maintenance methods, more research efforts have been devoted to automated log analysis. In particular, machine learning (ML) has been widely used in log analysis tasks. In ML-based log analysis tasks, converting textual log data into numerical feature vectors is a critical and indispensable step. However, the impact of using different log representation techniques on the performance of the downstream models is not clear, which limits researchers and practitioners' opportunities of choosing the optimal log representation techniques in their automated log analysis workflows. Therefore, this work investigates and compares the commonly adopted log representation techniques from previous log analysis research. Particularly, we select six log representation techniques and evaluate them with seven ML models and four public log datasets (i.e., HDFS, BGL, Spirit and Thunderbird) in the context of log-based anomaly detection. We also examine the impacts of the log parsing process and the different feature aggregation approaches when they are employed with log representation techniques. From the experiments, we provide some heuristic guidelines for future researchers and developers to follow when designing an automated log analysis workflow. We believe our comprehensive comparison of log representation techniques can help researchers and practitioners better understand the characteristics of different log representation techniques and provide them with guidance for selecting the most suitable ones for their ML-based log analysis workflow.
Read more4/9/2024
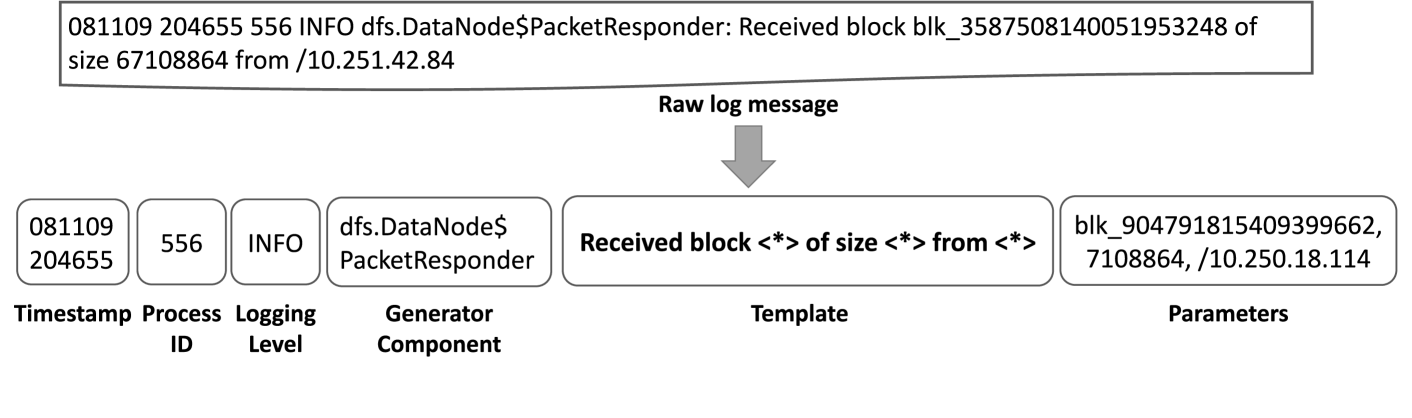
0
A Comparative Study on Large Language Models for Log Parsing
Merve Astekin, Max Hort, Leon Moonen
Background: Log messages provide valuable information about the status of software systems. This information is provided in an unstructured fashion and automated approaches are applied to extract relevant parameters. To ease this process, log parsing can be applied, which transforms log messages into structured log templates. Recent advances in language models have led to several studies that apply ChatGPT to the task of log parsing with promising results. However, the performance of other state-of-the-art large language models (LLMs) on the log parsing task remains unclear. Aims: In this study, we investigate the current capability of state-of-the-art LLMs to perform log parsing. Method: We select six recent LLMs, including both paid proprietary (GPT-3.5, Claude 2.1) and four free-to-use open models, and compare their performance on system logs obtained from a selection of mature open-source projects. We design two different prompting approaches and apply the LLMs on 1, 354 log templates across 16 different projects. We evaluate their effectiveness, in the number of correctly identified templates, and the syntactic similarity between the generated templates and the ground truth. Results: We found that free-to-use models are able to compete with paid models, with CodeLlama extracting 10% more log templates correctly than GPT-3.5. Moreover, we provide qualitative insights into the usability of language models (e.g., how easy it is to use their responses). Conclusions: Our results reveal that some of the smaller, free-to-use LLMs can considerably assist log parsing compared to their paid proprietary competitors, especially code-specialized models.
Read more9/5/2024